1.ClearGrasp:透明な物体を認識可能な機械学習アルゴリズム(3/3)まとめ
・合成データセットには地面に設置された透明な物体のみが含まれるという制限があった
・Matterport3DおよびScanNetデータセットのデータを利用して表面形状の学習を追加した
・ClearGraspの出力深度情報はRGB-D画像を使用する最先端のロボット操作アルゴリズムで使用可能
2.ClearGraspの定性的評価
以下、ai.googleblog.comより「Learning to See Transparent Objects」の意訳です。元記事の投稿は2020年2月12日、Shreeyak SajjanさんとAndy Zengさんによる投稿です。アイキャッチ画像のクレジットはPhoto by Aleks Dahlberg on Unsplash
次に、既知の表面を奥行情報に拡張するグローバル最適化モジュールを使用します。予測した面法線を使用して再構成の形状を導き、予測オクルージョン境界を使用して異なるオブジェクト間の分離を維持します。
各ニューラルネットワークは、合成データセットでトレーニングされ、現実世界の透明な物体に対して良好に機能しました。ただし、壁や果物など一部の物体の表面形状推定は不十分でした。
これは、合成データセットの制限によるものです。データセットには地面に設置された透明な物体のみが含まれているためです。
この問題を軽減するために、Matterport3DおよびScanNetデータセットの現実世界の屋内シーンを表面法線トレーニングループに含めました。合成データセットと現実世界のデータセットの両方でトレーニングを行うことにより、モデルはテストセットのすべての表面形状で良好に機能するようになりました。

それぞれのデータセットを使って学修したモデルの現実世界の表面法線推定の結果
a)Matterport3DおよびScanNetのみを使って学習(MP + SN)
b)合成データセットのみ
c)MP + SNおよび合成データセット
MP + SNでトレーニングされたモデルがどのように透過物体の検出に失敗するかに注目してください。合成データのみでトレーニングされたモデルは、学習時に使ったプラスチックボトルを非常によくピックアップしますが、他のオブジェクトや表面形状では失敗します。両方でトレーニングを行うと、私たちのモデルは両方の長所を活用できます。
結果
最終的に、定量的な実験により、ClearGraspは透明な物体の奥行情報を、他の手法よりもはるかに忠実に再構築できる事が示されました。合成された透明物体のみを使ってトレーニングされていますが、モデルは実世界の画像にもうまく適応でき、既知の物体に関して定量的に非常に近しい再構成パフォーマンスを達成できます。また、モデルは、これまでに見たことのない複雑な形状の新しい物体にも対応できています。
ClearGraspの定性的なパフォーマンスを確認するために、以下に示すように、入力および出力の深度画像から3D画像を構築しています。プロジェクトのWebページで追加の事例を確認できます。
結果として得られる推定3D表面は、単眼深度推定法で見られるギザギザのノイズなしに、3Dマッピングや3Dオブジェクト検出などのアプリケーションに重要な、クリーンで一貫した再構成形状を持ちます。私たちのモデルは堅牢で、パターン化された背景を持つ風景内に存在する透明な物体の識別や、部分的に互いに隠されている透明な物体の区別など、困難な条件でうまく機能します。
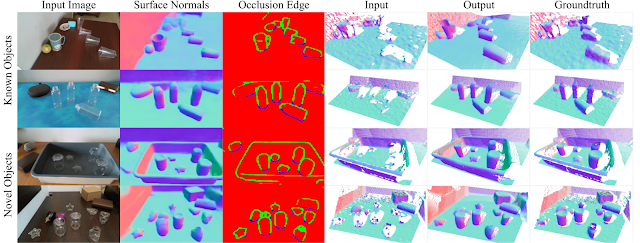
実画像を使った定性的評価
上2行:既知の物体の評価
下2行:未見の物体の評価
表面法線で色付けされた点群は、対応する奥行情報から生成されています。
最も重要なことは、ClearGraspが出力する深度情報は、RGB-D画像を使用する最先端の操作アルゴリズムへの入力として直接使用できることです。
生のセンサーデータの代わりにClearGraspの出力深度の推定値を使用することで、UR5ロボットアームの把握アルゴリズムを使った透明な物体の把握成功率が大幅に向上しました。平行顎グリッパーを使用した場合、成功率はベースラインの12%から74%に、吸引で64%から86%に向上しました。
![]()
ClearGraspを使用した透明な物体のロボット操作
大変難しい条件下で作業している事に着目してください。テクスチャのない背景、複雑な物体形状、および紛らわしい影とコースティクス(caustics:光が表面から反射または屈折するときに発生する光のパターン)を引き起こす指向性ライト
制限と今後の作業
合成データセットの制限は、従来のパストレーシングアルゴリズムでのレンダリングの制限により、正確なコースティクスが表現できないことです。その結果、私達のモデルは、明るいコースティクスと影を混同して、独立した透明な物体であると混同します。これらの欠点はありますが、ClearGraspを使用した研究では、合成データが学習ベースの深度再構築手法の有能な結果を達成する実現可能なアプローチであることが示されています。
将来の研究の有望な方向性は、物理的に正しいコースティクスと指紋などにより表面に不備を持つレンダリングを生成することにより、実世界の画像への適応能力を改善することです。
ClearGraspを使用すると、高品質のレンダリングを使用して現実世界で良好に機能するモデルを正常にトレーニングできることを実証できました。私たちのデータセットが、透明な物体のデータ駆動型知覚アルゴリズムの更なる研究を促進することを願っています。 ダウンロードリンクとその他のサンプル画像は、プロジェクトWebサイトとGitHubリポジトリにあります。
謝辞
この研究は、Shreeyak Sajjan(Synthesis.ai)、Matthew Moore(Synthesis.ai)、Mike Pan(Synthesis.ai)、Ganesh Nagaraja(Synthesis.ai)、Johnny Lee、Andy Zeng、およびShuran Song(コロンビア大学)によって行われました。マネージメントのサポートをしてくれたRyan Hickman、実り多い技術的な議論をしてくれたIvan KrasinとStefan Welker、ポーションボトルの3Dモデルを共有してくれたCameron(@camfoxmusic)、ウェブデザインを手伝ってくれたSharat Sajjanに感謝します。
3.ClearGrasp:透明な物体を認識可能な機械学習アルゴリズム(3/3)関連リンク
1)ai.googleblog.com
Learning to See Transparent Objects
2)sites.google.com
3D Datasets for Transparent Objects
3)github.com
Shreeyak/cleargrasp
4)arxiv.org
Deep Depth Completion of a Single RGB-D Image
