
1.PAWS:自然言語の言い換えの理解を促進する新しいデータセット(2/3)まとめ
・PAWSの作成には「言い換えペアになるかはわからないが意味ある文章を作成する単語交換モデル」を使用
・単語変換モデルの出力結果を人間の評価者が目で言い換えペアであるか否かをチェックを実施
・PAWS-Xもニューラルマシン翻訳(NMT)サービスと人間の翻訳家の組み合わせでデータセットを作成
2.PAWSの作成方法
以下、ai.googleblog.comより「Releasing PAWS and PAWS-X: Two New Datasets to Improve Natural Language Understanding Models」の意訳です。元記事の投稿は2019年10月2日、Yuan ZhangさんとYinfei Yangさんによる投稿です。
英語用PAWSデータセットの作成
論文「PAWS: Paraphrase Adversaries from Word Scrambling」では、重複する単語が多いけれども、言い換えペアと非言い換えペアのバランスがとれている文のペアを生成する作業フローを紹介しています。
例文を生成するために、元文章は、特殊な言語モデルに最初に渡されます。このモデルは、「意味を持つ文章にはなるけれども言い換えペアになるかどうかは曖昧な単語交換」を行います。
次に、これらは人間の評価者によって文法が判断され、複数の評価者が言い換えペアであるかどうかを判断します。
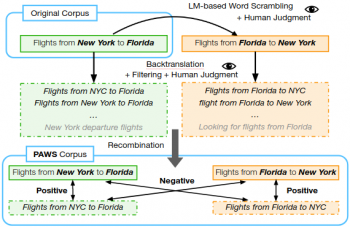
PAWSのコーパス作成ワークフロー
この単語交換戦略の問題の1つは、言い換えではないペアを生成する傾向がある事です。
例えば、
(1)why do bad things happen to good people?
何故、善人に悪い事が起こるのか?
(2)why do good things happen to bad people?
何故、悪人に良い事が起こるのか?
は、同じ意味ではありません。
言い換えペアと非言い換えペアのバランスを確保するために、逆翻訳を行って他の例を追加しました。逆翻訳は、単語の順序と単語の選択を変更しながら意味を保持する傾向があるため、交換戦略と逆の傾向があります。これらの2つの戦略により、特にWikipediaの部分で、PAWSの全体的なバランスが保たれました。
多言語用PAWS-Xデータセットの作成
PAWSを作成した後、中国語、フランス語、ドイツ語、韓国語、日本語、スペイン語の6つの言語に拡張しました。人間の翻訳者を雇い開発用データセットとテスト用データセットを翻訳し、ニューラルマシン翻訳(NMT)サービスを使用して学習用データセットを翻訳しました。
6つの言語(48,000の翻訳文)のそれぞれについて、PAWS開発セットからランダムに抽出した4,000文のペアに対して人間(ネイティブスピーカー)の手を借りて翻訳をしました。
ペアの各文は独立して表示されるため、翻訳作業は文脈の影響を受けません。ランダムに抽出されたサブセットは、2人目の作業者によって検証されました。最終的なデータセットのワードレベルエラー率は5%未満です。
私達が翻訳家に、文が不完全または曖昧な場合は翻訳しないように指示していた事に注意してください。平均して、翻訳されなかったペアは2%未満であり、単純にそれらを除外しています。最終的に翻訳されたペアは、新しい開発セットとテストセットに分割されました。(それぞれ最大2,000ペア)。
![]()
ドイツ語(de)と中国語(zh)の人間の翻訳ペアの例
3.PAWS:自然言語の言い換えの理解を促進する新しいデータセット(2/3)関連リンク
1)ai.googleblog.com
Releasing PAWS and PAWS-X: Two New Datasets to Improve Natural Language Understanding Models
2)github.com
google-research-datasets/paws
google-research-datasets/paws/pawsx
3)arxiv.org
PAWS: Paraphrase Adversaries from Word Scrambling

コメント