
1.PAWS:自然言語の言い換えの理解を促進する新しいデータセット(3/3)まとめ
・BERTなどの強力なモデルはPAWSでトレーニングすると大幅に性能が向上
・BOWなどの文脈情報を学習できないモデルではPAWSを使っても性能向上せず
・PAWS-Xを多言語BERTモデルでパフォーマンス評価したところ言語横断的な手法が優れていた
2.PAWS-Xの評価
以下、ai.googleblog.comより「Releasing PAWS and PAWS-X: Two New Datasets to Improve Natural Language Understanding Models」の意訳です。元記事の投稿は2019年10月2日、Yuan ZhangさんとYinfei Yangさんによる投稿です。
PAWSおよびPAWS-Xを使用した言語理解
PAWSでトレーニングすると、BERTやDIINなどの強力なモデルは、既存のQuora Question Pairs(QQP)データセットでトレーニングした場合に比べて大幅に性能が改善されます。
たとえば、QQPをソースとするPAWSデータ(PAWS-QQP)では、BERTは既存のQQPでトレーニングすると33.5の精度しか得られませんが、PAWSトレーニングデータを与えられると83.1の精度に回復します。
BERTとは異なり、単純なBag-of-Words(BOW)モデルはPAWSトレーニングデータから学習できず、非局所的文脈情報を捕捉できない弱点を示しています。これらの結果は、PAWSが単語順と文章構造に対するモデルの感度を効果的に測定することを示しています。
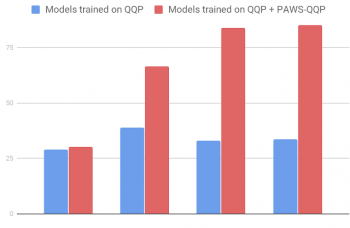
PAWS-QQP評価セットの精度(英語版)
以下の図は、いくつかの良く使われる手法を使用してPAWS-Xの多言語BERTモデルでのパフォーマンスを示しています。
1)ゼロショット(Zero Shot)
モデルはPAWS英語版トレーニングデータでトレーニングされ、 そのまま他言語で評価されます。機械翻訳はこの手法では使われません。
2)翻訳テスト(Translate Test)
英語のトレーニングデータを使用してモデルをトレーニングし、すべてのテスト結果を機械翻訳して評価します。
3)翻訳トレーニング(Translate Train)
英語のトレーニングデータをは各ターゲット言語に機械翻訳し、各言語用のモデルをトレーニングするためのデータとして使います。
4)統合(Merged)
多言語モデルを、「英語のデータ」と「他の全ての言語に機械翻訳したデータ」を使ってトレーニングします。
結果は、言語横断的な手法が役立つことを示していますが、言い換えれば、多言語の言い換え識別問題の性能には更なる研究の余地があります。
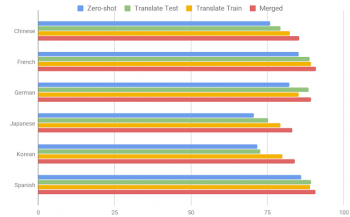
BERTモデルを使用したPAWS-Xテストセットの精度
これらのデータセットが、構造、文脈、および言い換えペアの比較をより活用可能な多言語モデルの更なる進歩を促進するために、研究コミュニティに役立つことを願っています。
謝辞
コアチームにはLuheng He, Jason Baldridge, Chris Tarが含まれます。
Google Researchの言語チーム、特にEmily Pitlerに、論文に貢献した洞察に満ちたコメントをくれた事に感謝します。Ashwin Kakarla, Henry Jicha, and Mengmeng Niuにも注釈の助けをしてくれて感謝します。
3.PAWS:自然言語の言い換えの理解を促進する新しいデータセット(3/3)関連リンク
1)ai.googleblog.com
Releasing PAWS and PAWS-X: Two New Datasets to Improve Natural Language Understanding Models
2)github.com
google-research-datasets/paws
google-research-datasets/paws/pawsx
3)arxiv.org
PAWS: Paraphrase Adversaries from Word Scrambling
Natural Language Inference over Interaction Space

コメント