
1.MediaPipeを利用してオンデバイスでリアルタイムに手の動きを知覚(1/2)まとめ
・手は形状が自由に変化したり他の手と組み合わされる事もありリアルタイムな検知が難しい
・MediaPipeと言う様々な手法の知覚データを処理可能な機械学習パイプラインを用いてこれを実現した
・リアルタイムでスマホ等のオンデバイスで95.7%の平均精度で手のひらの検出を達成
2.MediaPipeとは?
以下、ai.googleblog.comより「On-Device, Real-Time Hand Tracking with MediaPipe」の意訳です。元記事は2019年8月19日、Valentin BazarevskyさんとFan Zhangさんによる投稿です。
2020年12月追記)その他のMediaPipeシリーズのまとめ記事はこちら。
手の形と動きを知覚する能力は、さまざまな技術的領域とプラットフォームでユーザー体験を向上させるための重要なカギとなります。
例えば、手話の理解や手振りで機械をコントールする際の基礎となり、物理的世界の手のひらと拡張現実のデジタルコンテンツを融合させる事もできます。人間は生まれながらに手を知覚できますが、堅牢にリアルタイムに手の動きを知覚するは、非常にチャレンジングなコンピュータービジョンタスクです。手はしばしば手のひら自身、または手のひら同士でお互いを握り合い(例:指や手を握る、または握手する)、明確な陰影パターンを持っていません。
本日、手の知覚に関する新しいアプローチのリリースを発表します。これは、6月のCVPR 2019でMediaPipe上で実装してプレビューされたものです。MediaPipeはオープンソースのクロスプラットフォームフレームワークで、ビデオやオーディオなど、様々な表現手法を用いた知覚データを処理するパイプラインを構築する事ができます。
このアプローチでは、機械学習(ML)を使用して、手と指を忠実に追跡します。単一のフレームから手のひらに21個の3Dキーポイントを推測することで、これを実現しています。
現在の最先端の手認識アプローチは推論を実行するために強力な計算機パワーを持つデスクトップパソコン環境に主に依存しているのに対し、今回の方法は携帯電話でリアルタイムに実行可能なパフォーマンスを達成し、更に複数の手を対象に拡張できます。この手を知覚する機能をより広範な研究開発コミュニティに提供することで、創造的なユースケースが出現し、新しいアプリケーションや新しい研究手段が刺激されることを願っています。

MediaPipeを介して携帯電話でリアルタイムに3Dで手を認識。このソリューションでは、機械学習を使用して、ビデオフレームから手に21個の3Dポイントを計算します。奥行は線の色合いで示されています。
手の追跡とジェスチャー認識のためのMLパイプライン
私達の手の追跡ソリューションは、連携して動作する複数のモデルで構成されるMLパイプラインを利用しています。
1)手のひら検出器モデル(BlazePalmと呼ばれます)は、画像全体から手が描かれている範囲の境界ボックスと方向を返します。
2)手のひら検出モデルによって定義され、切り抜かれた境界ボックス領域で動作し、高い正確性で手の3Dポイントを計算するランドマークモデル。
3)計算されたキーポイントを個別のジェスチャーに分類するジェスチャーレコグナイザ。
このアーキテクチャは、最近公開されたフェイスメッシュMLパイプラインで採用されているものや、他の人がポーズ推定に使用しているものと似ています。
ランドマークモデルに正確にトリミングされた手のひら画像を提供することで、データの拡張(回転、変換、スケールなど)の必要性が大幅に削減され、代わりにネットワークがその能力のほとんどを予測の精度に充てることができます。
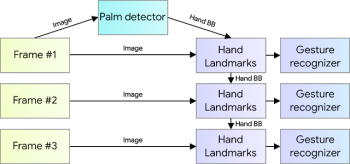
手を認識するパイプラインの概要
始めに手の位置を検出するために、BlazePalmと呼ばれるシングルショット検出器モデルを採用しています。
これは、モバイル機器上でリアルタイムで顔認識が出来るように最適化されたBlazeFaceと同様の手法で、これらはMediaPipeで利用可能です。
手の検出は非常に複雑なタスクです。モデルは、画像フレームに対して大きなスケール(最大20倍)を含む様々な手のサイズで動作し、握手状態や握った状態の手も検出できる必要があります。
顔は、例えば目と口の領域でコントラストの高いパターンを持っていますが、手はそのような特徴がないため、視覚的な特徴だけから確実に検出することは比較的困難です。代わりに、腕、体、または人的特徴などの追加の情報を提供することで、正確な手の位置特定を支援します。
私達は、様々な戦略を使用して上記の課題に対処します。まず、「手(hand)の検出器」ではなく「手のひら検出器(palm detecter)」をトレーニングします。手のひらやこぶしのような物体として捉える事ができる対象が含まれる領域を境界ボックス単位で推定する事は、手や関節のある指を個々に検出するよりもはるかに簡単です。
更に、手のひらは小さなオブジェクトであるため、Non-Maximum Suppressionアルゴリズム(訳注:検出器が同一物体をちょっとだけずらして重複検出してしまう時に上手い事処理してくれるアルゴリズム)は、握手のような両手が繋がっている状態でもうまく機能します。そして、アスペクト比を無視して四角い境界ボックス(ML用語でアンカー(anchors)と呼びます)を使用して手のひらをモデル化できるため、アンカーの数を1/3から1/5に減らすことができます。
第二に、この小さなオブジェクトに対して、より大きな風景の認識が可能なエンコーダーデコーダー特徴抽出器が適用されます。(RetinaNetのアプローチと同様)。
最後に、トレーニング中の焦点損失を最小限に抑え、大きな認識不一致が引き起こす大量のアンカーをサポートするようにします。
上記の手法により、手のひらの検出で95.7%の平均精度を達成しています。 通常のクロスエントロピー損失を使用し、デコーダーを使用しない場合は86.22%の平均精度です。
3.MediaPipeを利用してオンデバイスでリアルタイムに手の動きを知覚(1/2)関連リンク
1)ai.googleblog.com
On-Device, Real-Time Hand Tracking with MediaPipe
2)arxiv.org
BlazeFace: Sub-millisecond Neural Face Detection on Mobile GPUs
3)github.com
google/mediapipe
4)sites.google.com
Face Mesh
