
1.集積カプセルオートエンコーダー(5/6)まとめ
・OCAEは、パーツの姿勢をオブジェクトとして説明しようとする
・古いカプセルはEMベースの推論を使用してオブジェクトに対するパーツの投票をクラスタ化した
・新しいカプセルはK個の出力を持つSet Transformerを使用してパーツのアクティベーションをエンコード
2.オブジェクトカプセルオートエンコーダー
以下、akosiorek.github.ioより「Stacked Capsule Autoencoders」の意訳です。元記事の投稿は2019年6月23日、Adam Kosiorekさんによる投稿です。
パーツをオブジェクトにまとめる
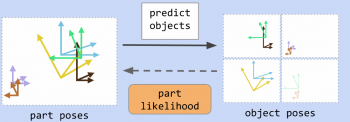
オブジェクトカプセルオートエンコーダー(OCAE:Object Capsule Autoencoder)は、パーツの姿勢をオブジェクトとして説明しようとします。自動的にデータ内に構造を発見し、それによってそれぞれのオブジェクトカプセルが異なったオブジェクトに特化します。
画像内にどのパーツがあるのか、それらがどこにあるのかがわかると便利ですが、最終的には、それらのパーツが属するオブジェクトがどれであるかについて注意を払います。
以前の古いバージョンのカプセルでは、EMベースの推論手続きを使用して、パーツをオブジェクトに投票させていました。
この方法では、各パーツは、異なったオブジェクトに投票する事ができます。最初はバラバラですが、最終的には、少数のオブジェクトのセットに投票は収束することになります。
推論を圧縮と見なすこともできます。つまり、潜在的に大きなパーツセットが、潜在的に非常にまばらなオブジェクトセットによって説明できます。そこで、パーツのポーズと存在確率から直接オブジェクトカプセルのアクティベーションを予測します。
EMベースの推論は、オブジェクトに対するパーツの投票をクラスタ化しようとしました。 この直感に従い、K個の出力を持つSet Transformerを使用してパーツのアクティベーションをエンコードします。
Set Transformerは、amortized-clusteringタイプの問題に対して適切に機能することが証明されており、permutation invariant(順列不変:入力データの順序が異なっても出力が同じになる性質を持つ事)です。
パーツカプセルアクティベーションは、画素ではなく、画像内の任意の位置に存在する事ができるパーツを表し、その意味で順序はありません。従って、set-inputニューラルネットワークはMLPよりも優れた選択であるように思われます。(論文内で私達が行ったアブレーション研究によって裏付けられた仮説です)
Set Transformerの各出力は個別のMLPに供給され、MLPは対応するオブジェクトカプセルのすべてのアクティベーションを出力します。
また、オブジェクトの存在確率に適用されるいくつかの希薄性損失(sparsity losses)も使用します。これらは、オブジェクトカプセルをさまざまな種類のオブジェクトに特化させるために必要です。詳細については、論文を参照してください。
OCAEは、希薄性制約(sparsity constraints)受け、オブジェクトカプセルからのガウス混合予測の下で、パーツカプセルアクティベーションの尤度を最大化するように訓練されます。
3.集積カプセルオートエンコーダー(5/6)関連リンク
1)akosiorek.github.io
Stacked Capsule Autoencoders
What is wrong with VAEs?
2)openreview.net
Matrix capsules with EM routing
3)arxiv.org
Group Equivariant Convolutional Networks
Spatial Transformer Networks
Set Transformer: A Framework for Attention-based Permutation-Invariant Neural Networks
4)medium.com
Understanding Hinton’s Capsule Networks. Part I: Intuition.
5)science.sciencemag.org
Human-level concept learning through probabilistic program induction

コメント