
1.集積カプセルオートエンコーダー(4/6)まとめ
・カプセルアクティベーションを取得する手順は二段階にわけてPCAEとOCAEで行われる
・PCAE、パーツカプセルオートエンコーダーはパーツを検出してそれらを画像に再結合する
・OCAE、オブジェクトカプセルオートエンコーダは、パーツをオブジェクトに編成する
2.カプセルのパラメータ
以下、akosiorek.github.ioより「Stacked Capsule Autoencoders」の意訳です。元記事の投稿は2019年6月23日、Adam Kosiorekさんによる投稿です。段々とルー大柴チックな訳になりつつありますが、このレベルになると日本語訳がまだない概念が増えてくるのでそれっぽい日本語を造語するか、回りくどい説明になるか、カタカナ万歳 or アルファベット表記最高!の4択になってしまう感が否めず「エクスペリエンスをしながらグローイングアップしていくのが、僕のフィロソフィーだから by ルー大柴」
カプセルのパラメータはどこから入手できますか?
前項では、「生成プロセス」を、オブジェクトとパーツカプセルのアクティベーションをイメージに変換する事と定義しました。
しかし、特定の画像を記述するカプセルアクティベーションを取得するためには、何らかの推論を実行する必要があります。
この場合、VAEのように、推論をならす(amortize)ためにニューラルネットワークを使用します。(VAEの詳細については、「What is wrong with VAEs?」を参照してください)。言い換えれば、ニューラルネットは画像からカプセルアクティベーションを直接予測します。
これは2段階にわけて行われます。まず、画像が与えられたら、学習可能したパーツ銀行から各パーツのポーズパラメータと存在確率をニューラルネットで予測します。
次に、別のニューラルネットがパーツのパラメータを調べて、オブジェクトカプセルのアクティベーションを直接予測しようとします。
これらの2つの段階は、概説した生成プロセスの2つの段階に対応しています。こうして、各段階に対応する生成段階とペアにして、2つのオートエンコーダに到達できます。
1つはパーツカプセルオートエンコーダー(PCAE:Part Capsule Autoencoder)で、パーツを検出してそれらを画像に再結合します。もう1つのオブジェクトカプセルオートエンコーダ(OCAE:Object Capsule Autoencoder)は、パーツをオブジェクトに編成します。
以下では、それらのアーキテクチャと設計上の選択について説明します。
部品とポーズの推定
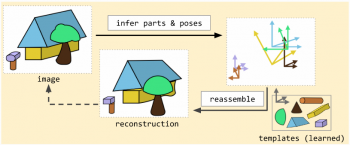
図5:Part Capsule Autoencoder(PCAE)は、画像から部品とその姿勢を検出し、アフィン変換されたパーツから直接組み立てることによって画像を再構築します。
PCAEはCNNベースのエンコーダを使用しますが、微調整が必要です。 まず、M個の部分に対して、M x (6 + 1)個の予測パラメータが必要であることに注意してください。
つまり、全てのパーツに対して、アフィン変換Xm(2次元で作業します)のための6つのパラメータとそのパーツが存在する確率Dmが必要です。いくつかの追加パラメータも予測に使用する事ができます。
実際、それを行っていますが、わかりやすくするためにここでは詳細を省略します。詳細については論文を参照してください。
CNNの後にfully-connectedレイヤーを使用しても、ここではうまく機能しないことがわかります。これについても詳細は論文を参照してください。
代わりに、CNNの出力を1×1の畳み込みを使用してMx(6 + 1 + 1)のフィーチャーマップに投影します。ここでは、各パーツカプセルに新たにフィーチャーマップを追加しています。
この追加のフィーチャーマップは、アテンションマスクとして機能します。ソフトマックスを使用して空間的に正規化し、残りの7つのマップを乗算して、空間位置全体で各次元を個別に合計します。
これはグローバル平均プーリング(global-average pooling)に似ていますが、モデルが特定の場所に焦点を合わせることを可能にします。私達はこれをアテンションベースプーリング(attention-based pooling)と呼んでいます。
そして、パーツ存在確率とパーツ姿勢を用いて、アフィン変換を学習したパーツを選択し、それらを画像としてまとめることができます。全ての変換されたパーツは空間的ガウス混合コンポーネントとして扱われ、そして私達はこの混合物の下で対数尤度を最大にすることによってPCAEを訓練します。
3.集積カプセルオートエンコーダー(4/6)関連リンク
1)akosiorek.github.io
Stacked Capsule Autoencoders
What is wrong with VAEs?
2)openreview.net
Matrix capsules with EM routing
3)arxiv.org
Group Equivariant Convolutional Networks
Spatial Transformer Networks
4)medium.com
Understanding Hinton’s Capsule Networks. Part I: Intuition.
5)science.sciencemag.org
Human-level concept learning through probabilistic program induction

コメント