
1.AutoRL:自動強化学習による長距離ロボットナビゲーションの実現(2/3)まとめ
・PRMのようなサンプリングベースのプランナーを使う事によって長距離ナビゲーションを実現できる
・強化学習ベースのローカルプランナーがノード間を接続できるか調査してPRMを作成していく
・最大の地図は288m x 163mでこれはローカルプランナーが扱える距離(~15m)を大幅に超える
2.PRM-RLとは?
以下、ai.googleblog.comより「Long-Range Robotic Navigation via Automated Reinforcement Learning」の意訳です。元記事は2019年2月28日、Aleksandra FaustさんとAnthony Francisさんによる投稿です。
次のステップは、AutoRLポリシーとサンプリングベースドプランニング(sampling-based planning)を組み合わせて、それらの範囲を拡大し、長距離ナビゲーションを可能にすることです。
PRM-RLによる長距離ナビゲーションの実現
サンプリングベースのプランナーは、ロボットの動きを近似することによって長距離ナビゲーションの課題に取り組みます。
たとえば、確率論的ロードマップ(PRM:probabilistic roadmaps)は、ロボットの位場所をサンプリングし、到達可能な経路と結び付け、広い空間でロボットが取り得る動きをロードマップに落とし込みます。ICRA 2018でBest Paper in Service Roboticsを受賞した私達の2つ目の論文では、PRMと手動でチューニングした強化学習ベースのローカルプランナー(AutoRLなし)を組み合わせて、ロボットをローカル環境で1回訓練し、その後、異なる環境に適応させました。
まず、ロボットごとに、一般的なシミュレーション環境でローカルプランナーポリシーをトレーニングします。次に、そのポリシーに関するPRM(PRM-RLと呼ばれます)をデプロイ環境のフロアプランに基づいて構築します。建物内に配置したい任意の「ロボット+環境設定」ごとに、同じフロアプランを使用できます。
PRM-RLを構築する際は、強化学習ベースのローカルプランナー(ロボットが受けるノイズも考慮に入れる能力を持ちます)が、ノード間を確実かつ一貫してナビゲートできる場合にのみ、サンプリングされたノード同士を接続します。これはモンテカルロシミュレーションによって行われます。
結果のロードマップは、特定のロボットの機能と地理的要因の両方に合わせて調整されています。形状が同じでもセンサーとアクチュエーター(駆動装置)が異なるロボット同士のロードマップは、接続性が異なります。ロボットはコーナーを回って移動できるので、ノードから明確に直線で見通せないノードも接続先に含めることができます。壁や障害物の近くにあるノードは、センサーノイズのためにロードマップに含まれる可能性が低くなります。実行時に、RLエージェントはロードマップの地点情報から地点情報にナビゲートして進んでいきます。
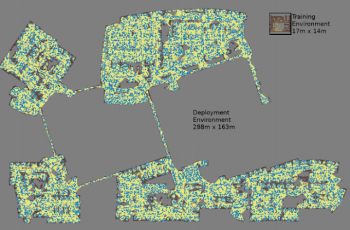
ランダムに選択されたノードペアごとに3つのモンテカルロシミュレーションを用いてロードマップが構築されます。

最大の地図は288メートル×163メートルです。11億の衝突判定を必要とするクラスタ内の300のワーカーにより4日間にわたって収集された、約700,000のエッジを含みます。
3.AutoRL:自動強化学習による長距離ロボットナビゲーションの実現(2/3)関連リンク
1)ai.googleblog.com
Long-Range Robotic Navigation via Automated Reinforcement Learning
2)ieeexplore.ieee.org
Learning Navigation Behaviors End-to-End With AutoRL
3)ai.google
PRM-RL: Long-range Robotic Navigation Tasks by Combining Reinforcement Learning and Sampling-based Planning
4)arxiv.org
Long-Range Indoor Navigation with PRM-RL
