
1.PlaNet:画像入力から世界モデルを学ぶ強化学習(2/3)まとめ
・エージェントは特定の操作によってボールの位置やゴールまでの距離がどのように変化するか想像出来る
・大量の計算が必要な画像作成を省略し将来の報酬を予測するだけでよいので高速に実行可能
・PlaNetは従来のモデルフリーの手法に比べて圧倒的に少ない学習回数で同等の精度を実現
2.Deep Planning Networkとは?
以下、ai.googleblog.comより「Introducing PlaNet: A Deep Planning Network for Reinforcement Learning」の意訳です。元記事は2019年2月15日、Danijar Hafnerさんによる投稿です。Deep Planning Networkは隠れ層でプランニングを行うため、結果を出力する必要がなく、効率的に学習を進める事が出来るので今後のトレンドとなっていきそうです。前編はこちら。後編はこちら。
的確に潜在ダイナミクスモデルを学習させるために、我々は以下の手法を取り込みました。
再帰状態空間モデル(Recurrent State Space Model):
決定論的要素と確率論的要素を合わせ持つ潜在的ダイナミクスモデル。堅牢なプランニングのためには様々な将来を予測しながら、長時間にわたって情報を記憶する必要があります。私たちの実験は、両方の要素がプランニングのパフォーマンス向上にとって重要であることを示しています。
潜在的オーバーシュート目標(Latent Overshooting Objective):
マルチステップ予測を訓練するために、潜在的ダイナミクスモデルの標準的なトレーニング目標を一般化します。潜在空間におけるワンステップ予測とマルチステップ予測の間の整合性を取る事によってこれを実現します。これは、長期予測を改善し、そしてあらゆる潜在的配列モデルと適合性がある、迅速かつ効果的な目標に繋がります。
将来の画像を予測することでモデルを学習させる事ができますが、画像(前述の図の台形)のエンコードとデコードにはかなりの計算が必要であり、プランニングが遅くなります。しかし、アクションシーケンス(一連のアクション)を評価するには、画像そのものではなく将来の報酬を予測するだけでよいので、潜在状態空間でのプランニングは高速に実行可能です。
例えば、エージェントは画像を生成しなくても、特定の操作によってボールの位置とゴールまでの距離がどのように変化するかを想像する事ができます。これにより、大きなバッチサイズでは、エージェントがアクションを選択するたびに、10,000通りの一連のアクションを想像する事ができます。
そして、見つかった最良のアクションシーケンスの最初のアクションを実行し、次のステップで再びプランニングします。
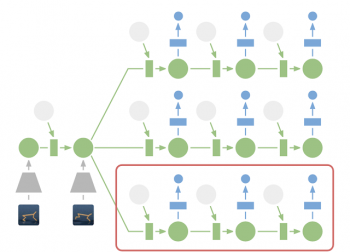
潜在空間でのプランニング:プランニングのために、過去の画像(灰色の台形)を現在の隠れ層(緑色)にエンコードします。そこから、私達は効率的に複数のアクションシーケンスに対する将来の報酬を予測します。前述の図にあった大量の計算を必要とする画像デコーダ(青い台形)がなくなったことに注意してください。次に、見つかった最良のシーケンスの最初のアクションを実行します。(赤い枠線)
世界モデルに関するこれまでの手法と比較すると、PlaNetはポリシーネットワークなしで機能します。純粋にプランニングのみでアクションを選択するので、即時にモデルを改善して恩恵を受ける事ができます。技術的な詳細については、オンラインリサーチペーパーまたはPDFをご覧ください。
PlaNetとモデルフリー手法の比較
私達は継続的なコントロールタスクに関してPlaNetを評価しました。エージェントには画像観測と報酬のみが与えられ、さまざまな課題に関するタスクで評価されました。
・カートポールタスク。カメラが固定されているので、カートは見えなくなる可能性があります。 したがって、エージェントは複数のフレームにわたって情報を収集して記憶しなければなりません。
・2つの別々のオブジェクトとそれらの間の相互作用を予測する必要があるフィンガースピンタスク。
・正確に予測するのが難しい地面との接触を含むチーターランニングタスク。複数の可能な未来を予測できるモデルを求めます。
・ボールがキャッチされ時のみ報酬信号が発生する報酬が疎なカップタスク。これには、正確な一連の行動を計画するために、将来にわたって正確な予測が必要です。
・模擬ロボットが地面に横たわっている状態から開始し、最初に立ち上がって歩く事を学ばなければならないという歩行タスク。

PlaNetエージェントは、さまざまな画像ベースの制御タスクでトレーニングされました。このアニメーションはエージェントが取り組んだタスクの入力イメージです。部分的な観測性、地面との接触、ボールを捕まえるための疎な報酬、そして挑戦的な二足歩行ロボットの制御など、タスクにはさまざまな課題があります。
私たちの研究は、世界モデルを学習したプランニングが、イメージベースのモデルフリータスクよりも優れているという最初の実例の1つです。
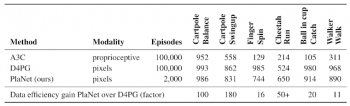
以下の表は、PlaNetと、A3CエージェントおよびD4PGエージェントを比較したものです。A3CエージェントとD4PGエージェントは最近のモデルフリー強化学習の進歩の組み合わせとして有名です。以下の基準値は、DeepMind Control Suiteを参考にしています。
PlaNetは、すべてのタスクで明らかにA3Cを凌駕し、D4PGに近い最終パフォーマンスを平均して5000%少ないトレーニング回数で達成しています。
(PlaNet:画像入力から世界モデルを学ぶ強化学習(1/3)からの続きです。)
(PlaNet:画像入力から世界モデルを学ぶ強化学習(3/3)に続きます。)
3.PlaNet:画像入力から世界モデルを学ぶ強化学習(2/3)関連リンク
1)ai.googleblog.com
Introducing PlaNet: A Deep Planning Network for Reinforcement Learning
2)planetrl.github.io
Learning Latent Dynamics for Planning from Pixels
3)arxiv.org
DeepMind Control Suite

コメント