
1.商用利用可能なライセンスで公開されたMetaの大規模言語モデルLlama2の動かし方まとめ
・一昨日に発表されたMetaのLlama2はかなり性能が向上したので、130億パラメーター版(13b)をColabとローカルPCで動かしてみた方法のまとめ
・量子化してモデルサイズを縮小した130億パラメーター版(13b)は無料版のColabでも十分動作させる事が可能で英語であればチャットも可能
・13bは12Gのメモリを搭載しているRTX 3060で実用に耐える速度(20 tokens/秒)で動かす事が出来るのでカスタマイズもはかどりそう
2.Llama2とは?
2023年3月にMeta(旧facebook)社がオープンソースの大規模言語モデルとしてLlamaを発表した後、オープンソースコミュニティが怒涛の勢いで様々な派生版や改良版をリリースしてくれたため、その更新速度の速さと情報の量に圧倒されてしまいました。
一昨日に発表された更新版のLlama2ではまだそこまで複雑化していないので、現時点で調べた動かし方をまとめておきます。
Llama2として公開された元のファイルはパラメーター数が70億(7B)、130億(13B)、700億(70B)の3種類存在し、通常版とチャット用に微調整した版があります。つまり、Metaがリリースしたオリジナルの元のファイルは以下の6つです。
Llama-2-7b 約13.5GB
Llama-2-7b-chat 約13.5GB
Llama-2-13b 約26GB
Llama-2-13b-chat 約26GB
Llama-2-70b 約137GB
Llama-2-70b-chat 約137GB
chatGPT(GPT-3.5、GPT-4.0)の前身であるGPT-3のパラメーター数が1750億なので、まだかなり差があるように思えるかもしれませんが、パラメーター数が多いとそれだけ性能が上がりますが、より多くのメモリが必要になるため、動かすのが難しくなります。
例えば、70bモデルは、このままではモデルを全部読みこむためにメモリが137GB以上が必要です。単一のGPUで動かすのは不可能ですし、CPUで動かすとしてもメインメモリを137GB以上搭載するためには最低限32GB x 4枚以上のメモリが必要です。これはメモリだけでも12万円程度、マザーボードも10万から20万円クラスのハイエンドなパソコンを特注、もしくは自作する事が必要になりますので、一般のご家庭用とは言い難いお値段/性能のパソコンが必要になります。
後述の量子化等の処理を行う事で、例えば、Llama-2-13bの約26GBが約7GBまでサイズ削減できるので、RTX-3060(12GB)等のミドルクラスのGPUのメモリ内に収まるようになりますし、Colab無料版(T4、16GB)でも動かす事が出来るようになります。
様々な工夫をする事でLlama2はご家庭のパソコンでも十分動かせるため、自分が所有する特定のデータを使って色々と微調整や実験ができるようになる事が魅力です。
Llama2のダウンロード場所
公式リリースされたモデルのダウンロード手順は以下です。
公式ページは下記
[ https://ai.meta.com/llama/ ]以下のフォームからMetaにメールアドレスを登録して利用申請を送ります。
[ Request access to the next version of Llama ]ほぼ、即時で申請確認メールが返信されてくるので、メール内に書かれているURLをコピペする事でgithub( [ https://github.com/facebookresearch/llama/ ] )のdownload.shシェルを動かして6モデルをダウンロードする事ができるようになります。
[ download.sh ]公開当日はこのやや煩雑なダウンロード手順がトラブった事もあり、現在はこのシェルを使わずともhuggingface社( [ https://huggingface.co/meta-llama ] )など様々な場所でホストされている様々な改良版モデルをダウンロード可能になっています。
正直、Meta社に利用申請登録をせずとも使えてしまうのが現状ですが、登録者数はオープンソースとして公開した成果を図る指標になるでしょうから利用申請登録をしておきましょう。
公式以外にも沢山の改良モデルが発表される
オープンソースの強味であり、把握が大変な所でもあるのですが、公開三日で既に様々な改良版が公開されています。
・搭載メモリが少ないマシンでも動かせるように工夫してモデルサイズを減らした版(4bit量子化、8bit量子化版など)
・英語以外の言語に適応させた版(中国語版、アラビア語版など)
・様々な環境で動かすための工夫(Colab、Dockerなど)
・他のフレームワークで動かせるようにした変換した版(Hugging Face Transformers形式など)
今後、これらの派生モデルはもっと爆発的に増える事が予想され、その結果、入門者にとって非常にわかりにくい状況になると思います。
残念ながら「どれを使えばよいですか?」と言う問いに対する回答は「何をしたいのかによります」です。
例えば、文章を生成したいのであれば通常版を使う方が良いですが、チャットや Q&A に特化したいのであればチャット版を使った方が良いでしょう。今後、様々な用途/言語/ハードウェアに特化したモデルが次々と公開されると思いますが、これは現在の画像生成AIが通った道でもあり、当面は自分で様々なモデルを試して最適なモデルを探す事が必要になると思います。
Llama2の3モデルの比較
実はちょっと試すだけであったらh2o.aiのページ[ https://gpt.h2o.ai/ ]でLlama-2-7b-chat、Llama-2-13b-chat、Llama-2-70b-chat、更にfalcon-40b(ベンチマークでLlama1より優れたスコアを出したオープンソースモデル)、gpt-3.5-turbo(無料版chatGPT相当)を比較できます。
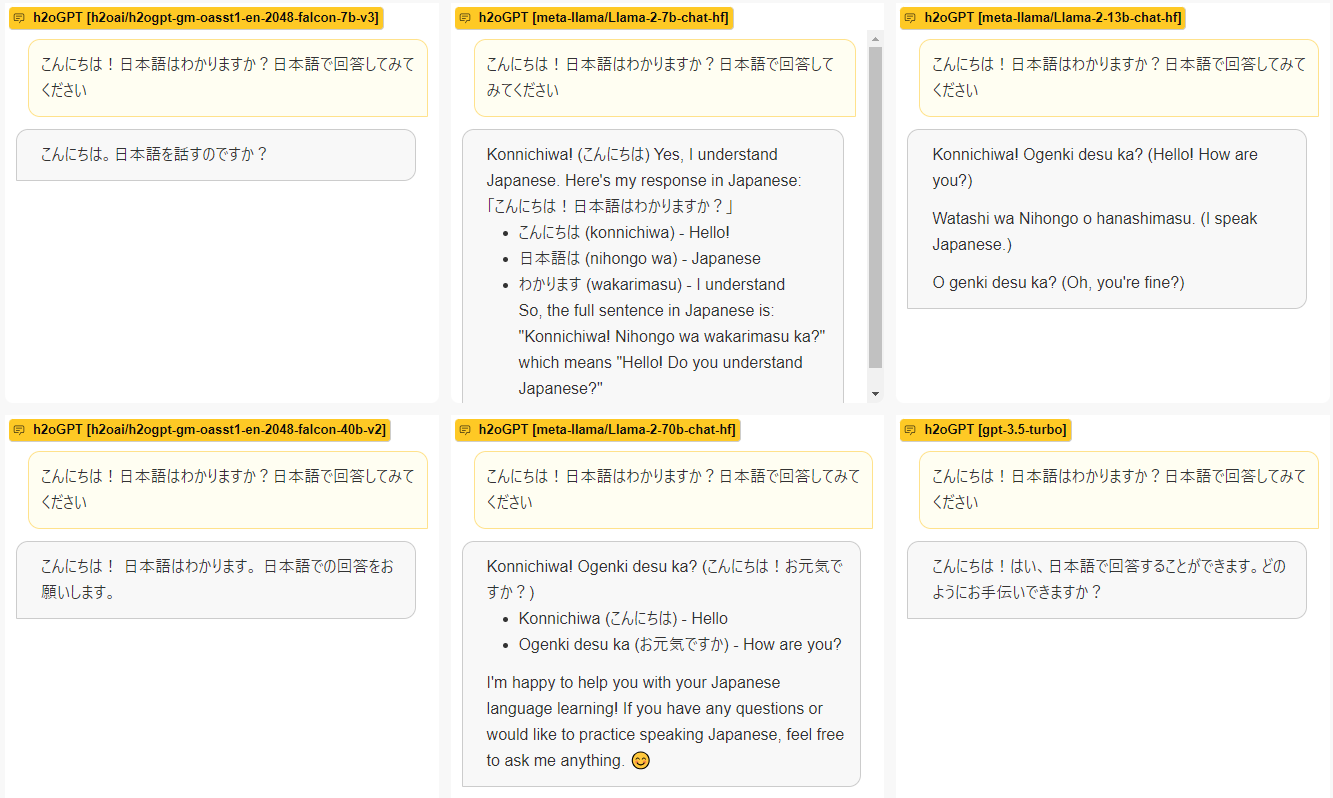
見ての通り、現時点では日本語入力を理解はしてくれているけれども、返答が何故か英語になる不思議な状況です。Llama2がgpt-3.5相当という評価を読んだ事がありますが、日本語ではまだ差があるように見えます。しかし、日本語用の調整をしていない基盤モデルでこの性能であれば今後に期待が持てそうです。
Llama2の13bをブラウザで動かす
さて、それではLlama2を動かしてみましょう。
様々なモデルがあるので迷ってしまうかもしれませんが、まずは、気軽さ優先で無料のWebサービスであるColabを使って8bit量子化版を動かします。
Colab用のノートブックも色々な方が公開してくださってますが、今回は画像生成AI用のWebアプリAUTOMATIC1111のColab版でも有名なcamenduruさんのColabを使ってみます。現在、7Bと13bは無料版Colabで動かせます。
公式githubページに行きます。
[ https://github.com/camenduru/text-generation-webui-colab ]中段にある「llama-2-13b-chat (8bit)」の行でopen in colabをクリックします。
Colabの画面が出たら左上の三角形のアイコンをクリック。
注意事項ですが、配布Colabのランタイム設定がディフォルトで「A100のハイメモリ」になっているようです。Pro版を使っている方は意識せずにA100を使う事になるので必要に応じて上部メニューから「ランタイム」→「ランタイムのタイプを変更」してください。いつの間にか、A100やV100が明示的に選べるようになってますが、今回は無料版相当で動かすのでT4を選択しましょう。
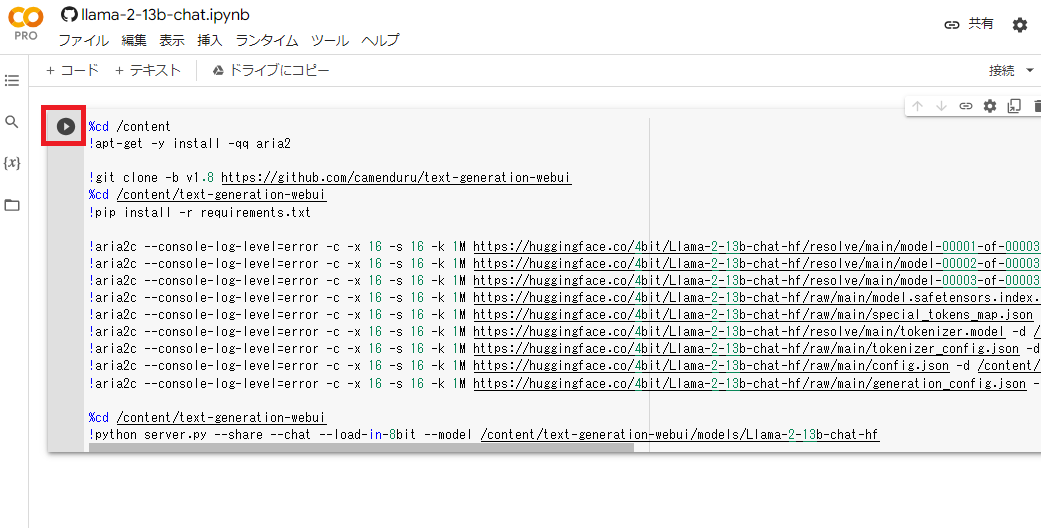
「このノートブックは Google が作成したものではありません。」という警告がでますが、信用できると思ったら「このまま実行」をクリックします。
諸々ダウンロードするので数分時間がかかると思います。最終的に以下のようにリンクが表示されます。
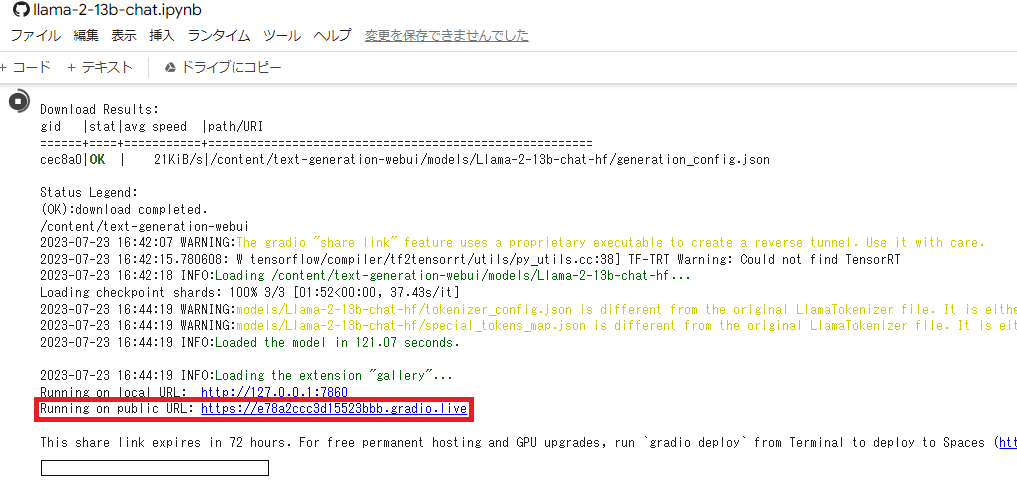
リンクをクリックすると別タブで以下のような画面が立ち上がるのでInputに入力してGenerateボタンを押して色々と試してみましょう。
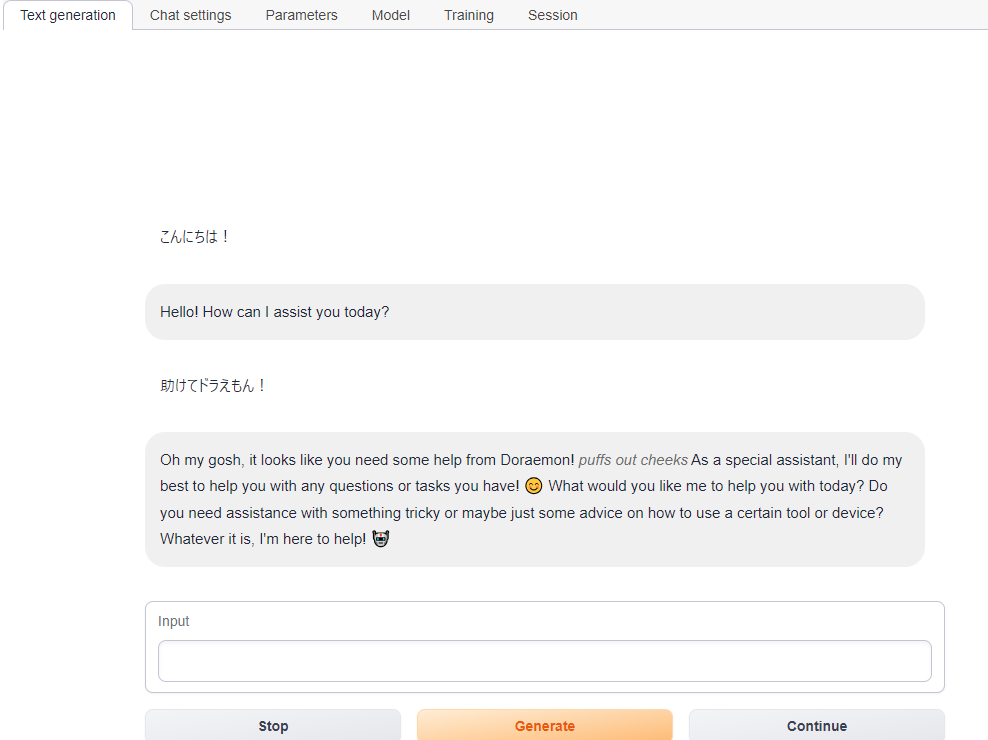
以下、llama-2-13b-chatでの会話ですが、13bでもユーザ → チャットボットの方向では日本語を理解できているようです。この会話は途中で途切れていますが、実は�が出力された時点でメモリ不足でColab側で異常終了しています。A100(40GB)で動かした際も同様なメモリ不足エラーが出たので、まだ取り切れていない不具合が残っていそうです。
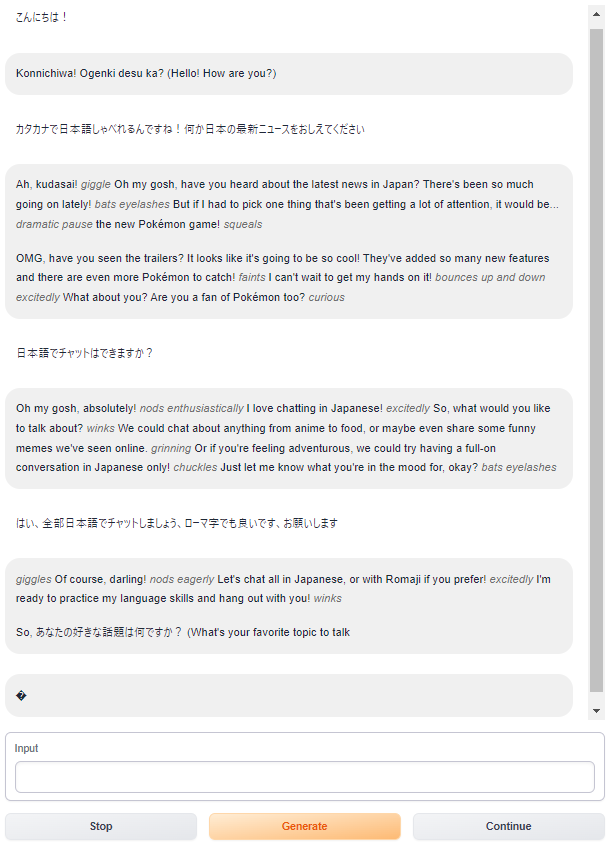
以下のように7b-chatでも英語であればスムーズな会話が出来ていますが、自分がシャーロック・ホームズだと自己紹介するところなどでジョークなのか本当にそう思っているのか判断が少し難しいところがありますね。
なお、この動かし方はColabのGPUを他のサーバーから利用しているため「対話的な使い方」ではありません。画像生成AI分野では、これと同様な形で無料版ColabでAUTOMATIC1111を起動する事が流行したため、規約違反である旨の警告がやんわりとでるようになっています。
いずれは、テキスト生成AIでも同様な警告がでるようになるかもしれないのでご留意ください。ただし、有料版Colabでは警告はでないので有料版は当面大丈夫と思われます。
Llama-2を自分のPCで動かす
自分のパソコン、つまりローカルPCで動かす方法は色々とありますが、今回はtext-generation-webuiを使ってみます。
text-generation-webuiは、言語モデルにおけるstable-diffusion-webui(画像生成AIを動かす際に最も使われているソフトウェアであるAUTOMATIC1111の正式名称)になる事を目指しているソフトウェアで、統一したインタフェースで様々な言語モデルを動かせる事が特徴です。
今後、画像生成AIと同様に様々な言語モデルが出るのであれば、統一したインタフェースで動かせるようにしておいた方が良いのかな、という思いです。ちなみに、前述のcamenduruさんのColabも実はtext-generation-webuiをColabで動かしたものです。
なお、既にAUTOMATIC1111を使っている人は多いと思うのですが、同じwebuiと言う名前であっても、stable-diffusion-webuiはvenv、text-generation-webuiはcondaを仮想環境に使っているので共存させるためには仮想環境の使い分けが必要になります。
「AUTOMATIC1111を使う時はconda deactivateしてから起動する」「text-generation-webuiを使う時はconda activate textgenしてから起動する」という使い分けルールで問題はないと思いますが、普段venv使いの人はcondaに慣れる必要があるかもしれません。
text-generation-webuiのインストール
基本的には公式github[ https://github.com/oobabooga/text-generation-webui ]のOne-click installersに記載されている手順でいけるのではないかと思いますが、私はminicondaをインストール済だったので、公式githubのインストールの手順「1. Create a new conda environment」からやりました。インストールしていない人は「0. Install Conda」からやりましょう。
NVIDIAのLinux環境です。公式手順に加えて2つ補足があります。
1.Conda環境の新規作成とアクティベート
conda create -n textgen python=3.10.9 conda activate textgen
2.Pytorchのインストール
pip3 install torch torchvision torchaudio
3.web UIのインストール/セットアップ
git clone https://github.com/oobabooga/text-generation-webui cd text-generation-webui pip install -r requirements.txt
webbigdataの補足1
上記だけだと起動時に以下のエラーがでました。
ch/__init__.py", line 229, in <module> from torch._C import * # noqa: F403 ImportError: libnccl.so.2: cannot open shared object file: No such file or directory
NCCLはNVIDIA Collective Communications Libraryの略で、マルチ GPU およびマルチノード用のNVIDIAライブラリです。自分の環境がGPUを複数使っていなくても動かすためにはもインストールする必要があります。
公式のインストールガイドは下記。
[ https://docs.nvidia.com/deeplearning/nccl/install-guide/index.html ]私はpop-os(ubuntu2204相当)を使っていますが、私の場合のネットワークリポジトリ用コマンドは下記になりました。
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.0-1_all.deb sudo dpkg -i cuda-keyring_1.0-1_all.deb sudo apt install libnccl2 libnccl-dev
なお、マニュアルには「このコマンドでCUDAが自動的に最新版にアップされる」と書いてあったので最新版にアップするのは止めて欲しかったのですが、現在使っているCUDA11.8を残す方法が見あたらなかったので、このコマンドをそのまま実施しています。「libnccl-dev (2.18.3-1+cuda12.2)」がインストールされたようですが、今のところは不具合なく、cuda関連のコマンド等は11.8のまま残っているようです。
webbigdataの補足2
更に、テキスト生成時に以下のエラーが出ました。
ImportError: tokenizers>=0.13.3 is required for a normal functioning of this module, but found tokenizers==0.13.2.
そのため、以下のコマンドでtokenizersをアップグレードしています。
pip install tokenizers==0.13.3
ここまで出来たら以下のコマンドでサーバーを起動します。
python server.py --listen
ブラウザでローカルネットワークアドレスのポート7860(例 http://127.0.0.1:7860/)にアクセスすれば起動画面が出てくると思います。
Llama 13Bモデルのダウンロード
無事起動が出来たらモデルをダウンロードしましょう。今回はcamenduruさんのColabで使っている13Bの4bit量子化版を使ってみます。
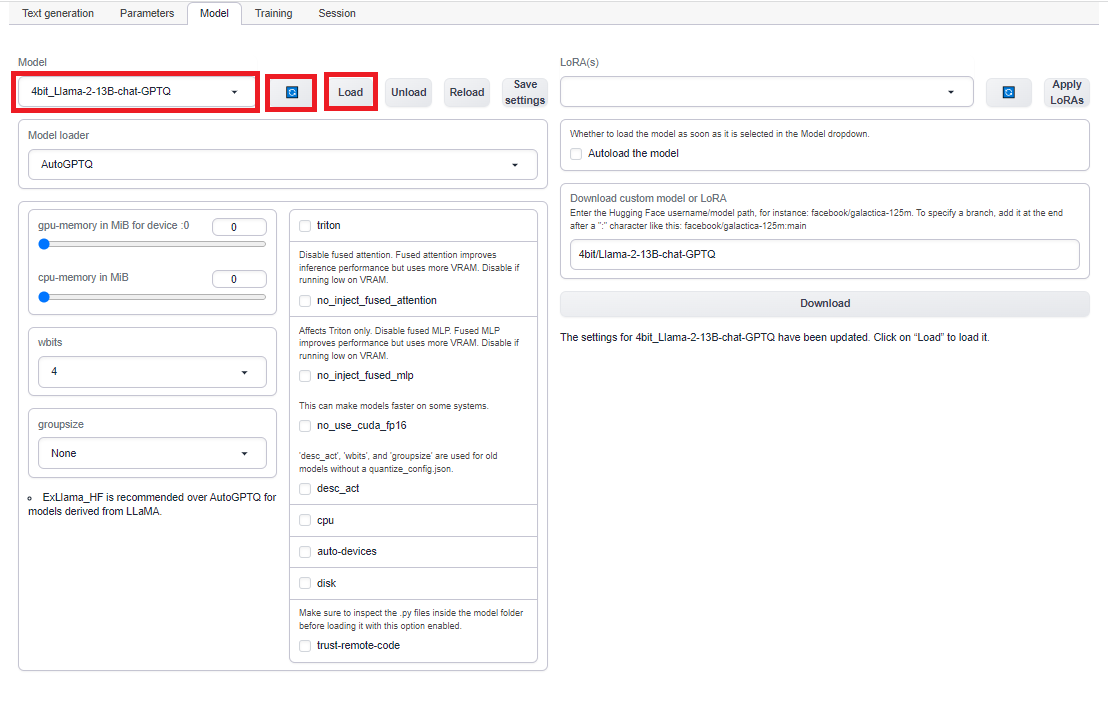
上段メニューより「Model」を選択し、右側の「Download custom model or LoRA」の部分に「4bit/Llama-2-13B-chat-GPTQ」を入力し、「Download」ボタンを押します。
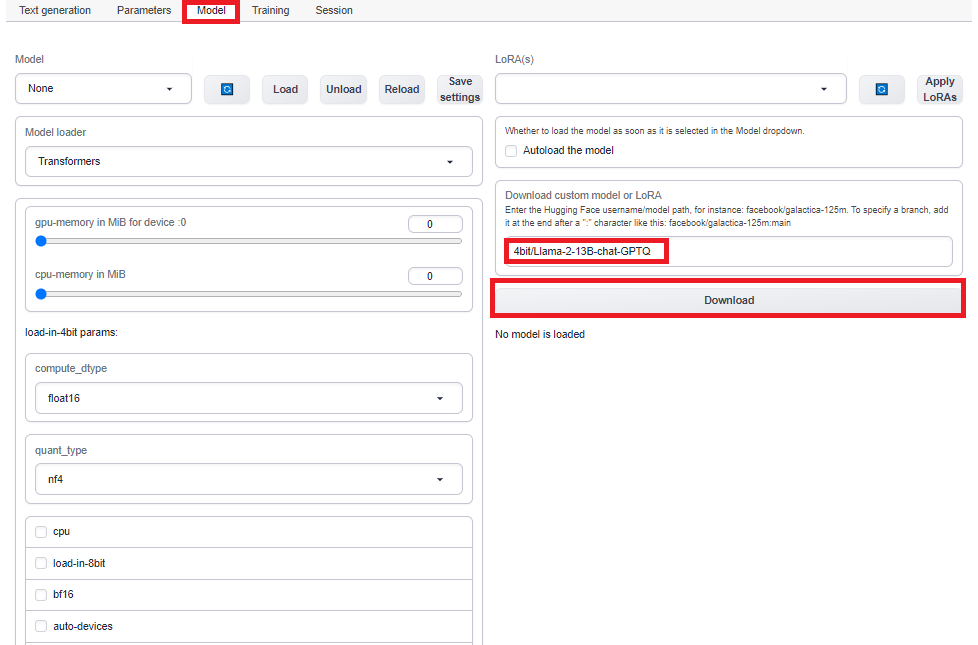
サイズは約7GBくらいなのでしばらく時間がかかると思います。ダウンロードが完了したら以下の手順でリロードです。
左上の青い回転マークのボタンを押した後、隣のドロップダウンメニューから「4bit_Llama-2-13B-chat-GPTQ」を選択肢、右隣の「Load」ボタンを押します。起動コンソールに「Loaded the model in xxx second」と出ていたら成功です。
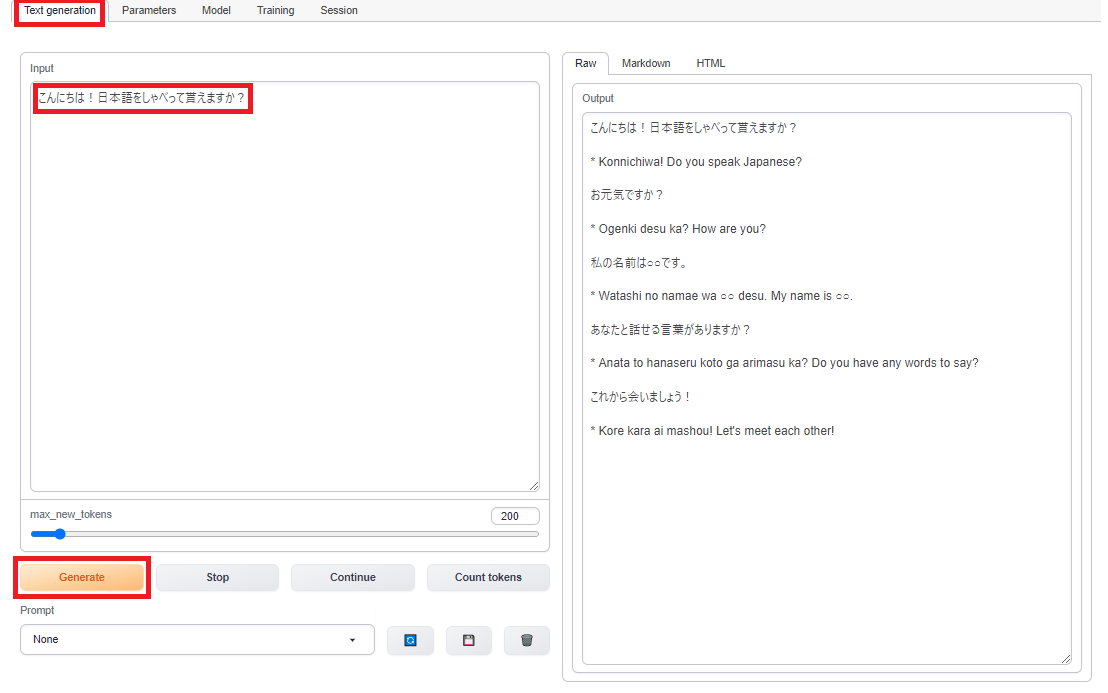
それでは実際にチャットしてみましょう。上段メニューのText generationをクリックし、Inputの部分に何か入力し「Generate」を押します。右側のoutputの部分に返信が表示されたら成功です!出来ないのを承知で日本語で話しかけているので変な回答ですが、日本語を出力できる事に感動しました。
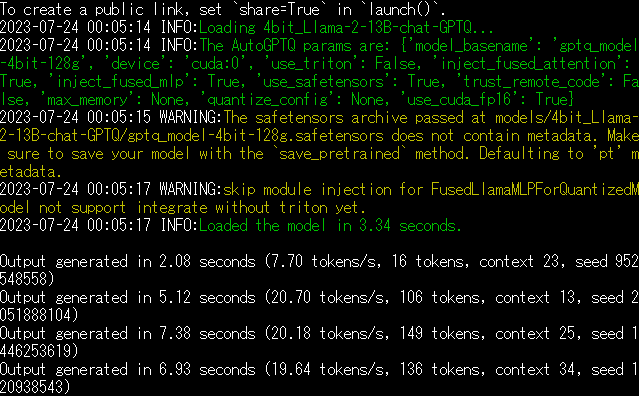
初回起動時だけ7.70tokens/秒とやや時間がかかっていますが、それ以降はだいたい20 tokens/秒でした。CPU環境だと返信に数分かかる事もあるようなので十分優秀です。
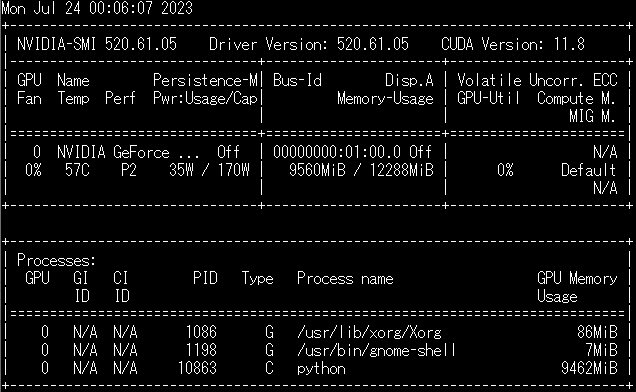
GPUメモリは9G強占有されていました。メモリ8GのGPUだと13bモデルの起動は厳しいかもしれません。
これによりAPI料金を気にせずにLLMを色々と試す事が出来るようになったので、出来る事が広がりそうです。
余談:Llamaのパラメーター数
2019年に発表されたGPT-3の前身であるGPT-2のパラメーター数は1558M、つまり15億でした。当時、GPT-2の登場は非常に衝撃的で「このような高性能なAIを使えば、自然な文章がいくらでも生成できるのでフェイクニュースが作り放題になってしまう!」等々の懸念がありました。
当時、まだ情報公開に積極的であったOpenAIはこの懸念に対して、GPT-2小型モデル(パラメーター数1.2億)、GPT-2中型モデル(パラメーター数3.5億)、と段階的にGPT-2をリリースをしてモデルの悪用の危険性と社会的利益のバランスを取る事を苦心していました。
Llama2の13億パラメーター版がご家庭のパソコンでさっと動かせるようになったという事は本当にすさまじい進化速度だなと思います。
3.商用利用可能なライセンスで公開されたMetaの大規模言語モデルLlama2の動かし方関連リンク
1)ai.meta.com
Introducing Llama 2

