
1.2023年6月時点の技術でイラスト生成AIで二次元キャラクターのコスプレ画像を作成するまとめ
・Stable Diffusionは拡張機能により以前よりだいぶ進化しておりモデルや微調整結果をより細かくコントロールする事が出来るようになっている
・各レイヤー群の機能を探求する事によってだいぶ柔軟にスタイルや概念を制御できるようになり着せ替えやコスプレも従来より楽になっている
・レイヤー毎に機能分解して必要な機能のみを取り出してマージや微調整で強化していくという手法は大規模言語モデル(LLM)に展開されていくかもしれない
2.Stable Diffusionの最近の進化
アイキャッチ画像はstable diffusionのカスタムモデルによる生成でスペースオペラ風のナウシカとそれでもやっぱり肩に乗せるのが難しいテト
2023年8月更新)Stable Diffusion XLに対応したAUTOMATIC1111のVersion1.5以降ではsd-webui-lora-block-weightの書式が変更されており、本記事内のプロンプトをそのままコピペするとエラーになります。エラーが出た場合は公式githubサイトで変更点を確認してください。
過去にも何度かStable Diffusionを使って世界的な観点からはそれほど有名ではないキャラクターにプロンプトで表現する事が難しい衣装に着せ替えるチャレンジをしているのですが、最近、技術的に大きな進歩があったように感じたので再トライしてみました。
なお、世界的に有名 or 世界的に人気 or 最近流行の版権キャラクターのイラストを生成するだけでしたら専用のモデル/微調整(LoRA/Embeddings)を公開されている事も多くなってきたので、ここまで深堀りする必要はないです。
(1)画像内の物体が何であるかを認識した上での修正が出来るようになってきた
描いて欲しい画像をプロンプトで指示すると、想定外の場所に想定外の効果が発生してしまったり、テト仮面のように概念同士が混ざってしまい、思う通りの画像を生成できない事がよくあります。
私の知る限り、これを軽減する従来手法手法は以下の1)と2)です。
1-1)指定した範囲に限定してプロンプトを適用させる
In-Painting、Out-Paintingなどに代表される「画像のこの部分にはこのプロンプト」と範囲を指定してプロンプトを適用する手法です。本サイトで紹介した事はありませんがsd-webui-regional-prompterやComfyUIなどのように画像を分割して範囲毎にプロンプトを指定して複数の概念を違和感なく共存させる拡張機能も幾つかあります。
弱点としては、各分割範囲のつなぎ目に微妙な違和感が出てしまう事があります。
「12時間寝ずにぶっ続けでInPaintingで修復した私のAIアートを見てください!」と熱意にあふれる投稿を見たことがありますが、納得の行く出来栄えまで持っていくのはとても時間がかかる事があります。
1-2)画像全体に対してプロンプトで編集効果を加える
instruct pix2pixのように「AをBにする」or「Aする」とプロンプトで画像全体に編集効果を加えるパターンです。
例:「(場面を)夜にする」「人を笑顔にする」など。
1)のように効果を加える場所を人が指定する必要がなくイラスト全体に効果を加える事が出来るので手間は省けますが、弱点として思ったような編集効果が実現できないケースが多々ある事です。
モデルが既に概念として認識できている実体/編集効果に対してのみ有効なので、ディフォルメされたアニメ系イラストでは顔が顔として認識されない事も多く、こちらも試行錯誤が必要になります。
1-3)修復箇所を自動で認識して適切な感じに修正する
そしてこれが最近の進歩です。
イラスト内の人間の体、顔、手などを自動で認識し、その箇所を違和感を感じさせないレベルでControlNetなどで自動修復(In-painting)する事が出来るようになってきています。
具体的にはadetailerやControlNet Tileなどですが、「その場所に何が描かれているか?」を自動認識してくれているので「人物に対して適用させたいプロンプトが背景にも適用されてしまう」等を避ける事ができるので想定外の場所に想定外の物体が出現する割合を低減できます。
また、2)と違うのは、認識用のニューラルネットワークは画像分類用途で実績のあるモデル(YoloやMediaPipe)を使っているので、画像内の顔や手、人物を認識する精度が高い事です。
弱点としては、手や顔や人物以外の部分は(まだ)自動的に認識してくれないので、例えば「動物を肩に乗せているイラスト」等はまだ簡単には実現出来ません。
しかし、これにより、顔を差し替えて好みのキャラクターに様々な服を着てもらう事が従来より容易になり、コスプレ/着せ替え系のイラストの生成が作りやすくなりました。

以前、作成した同様なナウシカの鬼滅の刃蟲柱隊服イラストはDreamBoothで概念を2つ取りこんで一発生成したイラストだったのでかなり手間がかかりました。今回の手法は、一度作成したイラストを顔だけ違和感なく書き換えるので概念の融合が起きにくく、以前に比べればだいぶ楽です。
(2)レイヤーのどの段階で何が行われているかの探求が進んでいる
ニューラルネットワークは人間の脳のようにレイヤー(層)が重なりあった構造をしています。
各レイヤー内で何が行われているのかは昔から探求されており、イラスト生成AIが流行する前から研究されていた画像分類AIでは「初めの方のレイヤーでは画像内の大枠を認識し、先に進むに連れて段々と先端部分などの細かい部分を認識しているようだ」と言う事がわかっています。
イラスト生成AIでも、おそらくこの構造は一緒です。そのため、拡張機能のsd-webui-lora-block-weightなどを使って
「初期段階、つまり大枠の作成段階ではモデル1 or LoRA1を重視して、後半の絵柄や色合い決定段階はモデル2 or LoRA2を重視する」
と言うテクニックが段々と洗練されてきています。
具体的には「二次元イラスト用モデル/LoRAに存在する概念(服)をリアル系イラスト用モデル/LoRA内で使用する」事などが出来るようになってきています。

しかし、レイヤー毎の探求は必要な拡張機能や前提条件、組み合わせが多いのと、綺麗なイラストが描けるケースと描けないケースの違いがまだはっきりとわかりません。「このようにすれば綺麗なイラストを確実に生成できます」的なHowTo記事も書きにくく、色々な方が試行錯誤している段階で情報も出そろってきていないのが現状と思います。
2-1)sd-webui-lora-block-weightの使用例
以下、アイキャッチ画像の場合はどのように探求していったかの事例です。公式githubページの解説も確認しつつ、参考にしてみてください。
AUTOMATIC1111とのその拡張機能であるsd-webui-lora-block-weightを使います。
インストールは他の拡張機能と同様です。
「Extensions」タブより「Install from URL」をタブを選択し、「URL for extension’s git repository」に「https://github.com/hako-mikan/sd-webui-lora-block-weight.git」を入力して「INSTALL」ボタンを押し、インストール後に再起動します。
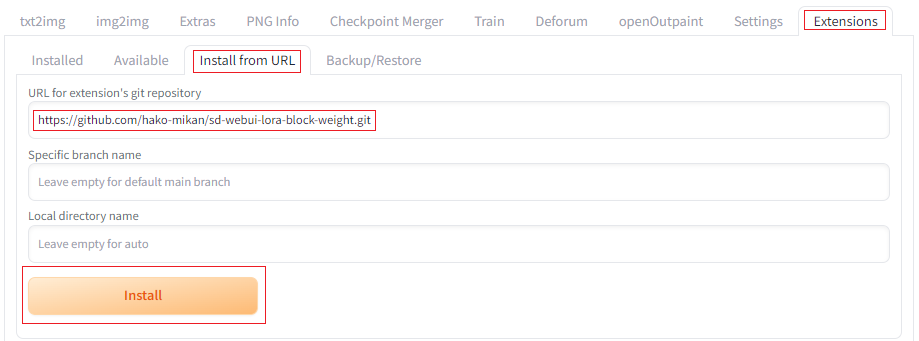
そうすると、txt2imgタブの下部にsd-webui-lora-block-weightに関連するメニューが表示されるようになるので、付属するXYZ plot機能を使って機能を探っていきます。
なお、AUTOMATIC1111はディフォルトでXYZ plot機能が搭載されていますが、そちらが有効になっているとsd-webui-lora-block-weightに付属するXYZ plot機能が使えないのでONにしていたらOFFにしてください。
まず、確認したいプロンプト + LoRAをプロンプトを入力するフォーム内に書きます。
下記は、新しい書式では
<lora:lora_teto:1:1:lbw=XYZ>
になるはずですが、検証出来ていません。
今後も仕様は変わる可能性があるので書式についてはsd-webui-lora-block-weightの公式githubサイトをご確認ください。
<lora:lora_teto:1:XYZ>
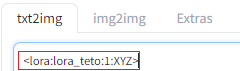
青文字部分は私の自作LoRAを指定しているので試したいLoRAに差し替えてください。赤(LoRAの強度)とオレンジ(対象レイヤ群)は差し替えられる部分なのでこのままです。
sd-webui-lora-block-weightのXYZ Plotの▼をクリックして以下のように設定していきます。
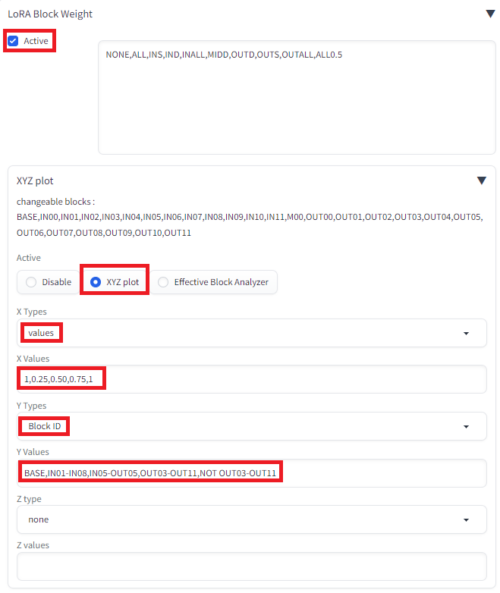
Xで指定しているValuesがLoRAの強度、Yで指定しているBlock IDが対象レイヤ群です。
結果は以下。

そうすると、右端のLoRAの強度1はスタイルが劣化してしまっていますし、左端は崩れる、もしくはスタイルがあまり変化していません。
なので、強度を真ん中の0.5から0.75に絞って、且つBASEを消す事にしましょう。
つまり、プロンプトは以下のように変えます。
<lora:lora_teto:0.55:XYZ>
そして、sd-webui-lora-block-weightの設定は
X Valuesを「0.55,0.65,0.75」です。赤文字部分が一致している必要があります。
Y Valuesは「IN01-IN08,IN05-OUT05,OUT03-OUT11,NOT OUT03-OUT11」です。XYZはそのままで大丈夫です。
また、対象を絞ったので、Z軸を「Original Weights」にして「NONE」と「ALL」を追加してみます。これは元のモデルの重みをどのように設定するかです。

結果は以下
Original Weights ALL

Original Weights NONE

Original WeightsをALLにすると元モデルの影響が強まり異星人っぽくなってしまうのでOriginal Weights NONEにしましょうか。
また、右端と下段は崩れてしまっているケースがあるので更に範囲を絞りましょう。
結果は以下です。

お、だいぶ良い感じに絞れてきましたね。OUT03-OUT11はテト(冬毛)が消えてしまっているので、INが重要なのかもしれませんね。ではレイヤー群をもう少し細分化してみましょう。
・・・
と言う感じで試行錯誤していくとLoRAをより細かくコントロール出来るようになって表現力があがっていきます。
ただ、アイキャッチ画像とこのサンプルのスタイルがだいぶ違いますよね。
理由はこの作業をしている時にin painting用のモデルで画像を生成しようとすると「Sizes of tensors must match except in dimension 1. Expected size 1 but got size 2 for tensor number 1 in the list.」と言うエラーメッセージが出て画像が生成できなくなっている事に気づき、各ライブラリを更新したり、拡張機能のON/OFF/再インストールをしたり、in painting用のカスタムモデルを作り直したりして原因を確かめようとしていたら、いつの間にか全然違うスタイルの絵が生成されるようになっている事に気づいたんですよね。
私の勘違いの可能性もあるのですが、画像のサイズを変更するだけでガラッと傾向が変わる事などもあり、そのくらいデリケートで再現性確保が難しいテクニックではあります。
なお、in painting用モデルが動かなかった理由は最近のAUTOMATIC 1111で導入された最適化の仕組みであるNGMS(Negative Guidance minimum sigma)を0.3以上に設定していたからのようで、既に本家githubに不具合報告があがっていました。
Negative Guidance minimum sigmaは「Settings」→「Optimizations」から設定可能で「画像生成処理の後半ではネガティブプロンプトはほとんど無視されるので処理をスキップして高速化しましょう」という設定です。なので、おまじない的に設定した人や公開画像等から取りこんだプロンプト内に「NGMS」の設定がされていた場合は、(Controlnetではない単体の)インペインティングが動かなくなっている可能性があるので確認しておきましょう。私は物凄い悩んでかなり無駄な時間を過ごしました。
余談ですが、人工知能は画像分野が先行し、言語分野が後追いして来た歴史があります。
そのため、レイヤー毎に機能分解して必要な機能のみを取り出してマージや微調整で強化していくという手法はchatGPT等の直近で流行っている大規模言語モデル(LLM)の微調整にも応用されるようになっていくのではないかと思ってます。
(3)ナウシカ要素検出能力検定
さて以上で、小難しい話はおしまいです。
実際に上記のテクニックや自作及び一般公開してくれているLoRA等を試行錯誤して組み合わせて作った様々なイラストを使ってナウシカ分類器としての能力をテストできるようにしてみました。
以下、全て風の谷のナウシカの要素を入れ込んだイラストですが、皆さんはどのレベルまでナウシカとして認識できますか?
ナウシカ要素検出能力検定レベル1




ナウシカ要素検出能力検定レベル2




ナウシカ要素検出能力検定レベル3




ナウシカ要素検出能力検定レベル4




ナウシカ要素検出能力検定レベル5


特定のキャラクターをキャラクターとして認識できるか否かの境目って中々難しいですね。
自分でやっていて思うのですが、赤い髪をして青い服を着た人ってだけでは必要十分ではなく、
・人間は特定のキャラクターを特定のキャラクターとして認識する際に服装や色を手がかかりとしているがそれだけではなさそう
・他のキャラクターと重複する要素を入れ込んだイラストは認識難度があがる
と言う気がします。
一般的な感覚だとレベル1がギリギリ認識できる範囲でレベル2以降は言われなきゃわからないし、言われても別キャラクターにしか見えないかもしれません。
レベル5まで認識可能なレベルになると逆に優れたナウシカ要素検出機能というより、過学習して幻覚を見はじめている説もあります。
3.2023年6月時点の技術でイラスト生成AIで二次元キャラクターのコスプレ画像を作成する関連リンク
1)github.com
comfyanonymous / ComfyUI
Bing-su / adetailer
hako-mikan / sd-webui-lora-block-weight
hako-mikan / sd-webui-regional-prompter

