
1.instruct pix2pix:プロンプトだけを使ってAIでイラストの修正を行うまとめ
・思い通りの編集効果が出せない時はImage CFGやText CFGの値をチューニングすると期待通りの効果が出せる可能性がある
・本家githubには学習データの作り方や学習させ方も書いてあるのでお金をかければカスタムモデル専用のinstruct pix2pixも作成可能
・使いどころは考える必要がありますが、上手に使いこなせればイラスト生成後の編集作業を楽にしてくれるポテンシャルがある
2.instruct pix2pixとは?
2023年4月追記)ControlNet1.1が本記事で紹介しているpix2pixに対応しました。
instruct pix2pixも一か月くらい前に話題になっていたStable diffusionの拡張で、文章による指示(instruct)で画素(pixcel)単位で画像を直接編集して貰えると言うフレコミです。
画素単位と言うとちょっとわかりにくいですが要は「人間が修正して欲しい範囲を明示的に指定する必要がない」事がポイントです。
インペインティングのように修正して欲しい範囲のマスク画像を用意する必要はないので
「このイラストの場面を夜にして」とか「この人の背後に花をもっと増やして」とかできちゃうぜ!
というお話で、フムフム、中々凄そうですのぉ、と思いつつも検証まで手が回らず今日に至りました。
既存技術として一番近いのはヒントン先生をムリヤリ笑顔に修正できるImagicだと思います。しかし、Imagicは技術は凄いのですが、素材毎に微調整が必要で準備が大変だったせいかそんなに話題にはなっていなかった印象です。
pix2pixは、イラスト修正用の専用モデルを使ってプロンプトのみでイラストの修正を行う事が可能なので、自分でモデルを改めて微調整する必要はありません。
しかし、1つのモデルであらゆるイラストに対応するのは難しそうですし、最近はControlNetの方が話題になっており、直近ではあまりpix2pixの話題を聞かないので、現在の状況はどうなってるかを改めて確認してみました。
現在までの経緯
・単独で動くpix2pixの実装がtimothybrooksさんによって公開
・nmkdというstable diffusion用のGUIにpix2pixが取りこまれた(pix2pix機能に関してはAUTOMATIC1111より使いやすいとの評判アリ)
・KlaceさんがAUTOMATIC1111というstable diffusion用の人気が高いGUI向けにpix2pix拡張機能が公開
・AUTOMATIC1111のディフォルト機能にpix2pixが取りこまれた
・diffuserでも動かせるようになっている(InstructPix2Pix pipeline)
・無料で動かせるSPACEもhuggingfaceで公開中(末尾リンクあり)
という感じで、現在はAUTOMATIC1111で動かす際に改めて拡張機能をインストールする事は不要になっています。
AUTOMATIC1111でのpix2pixのインストール/セットアップ方法
AUTOMATIC1111でpix2pixを動かすためには専用モデルを所定のフォルダに設置するだけです。
(1)モデル「instruct-pix2pix-00-22000.safetensors」を以下のページにいって赤枠の「download」を押してダウンロード
「 https://huggingface.co/timbrooks/instruct-pix2pix/blob/main/instruct-pix2pix-00-22000.safetensors 」
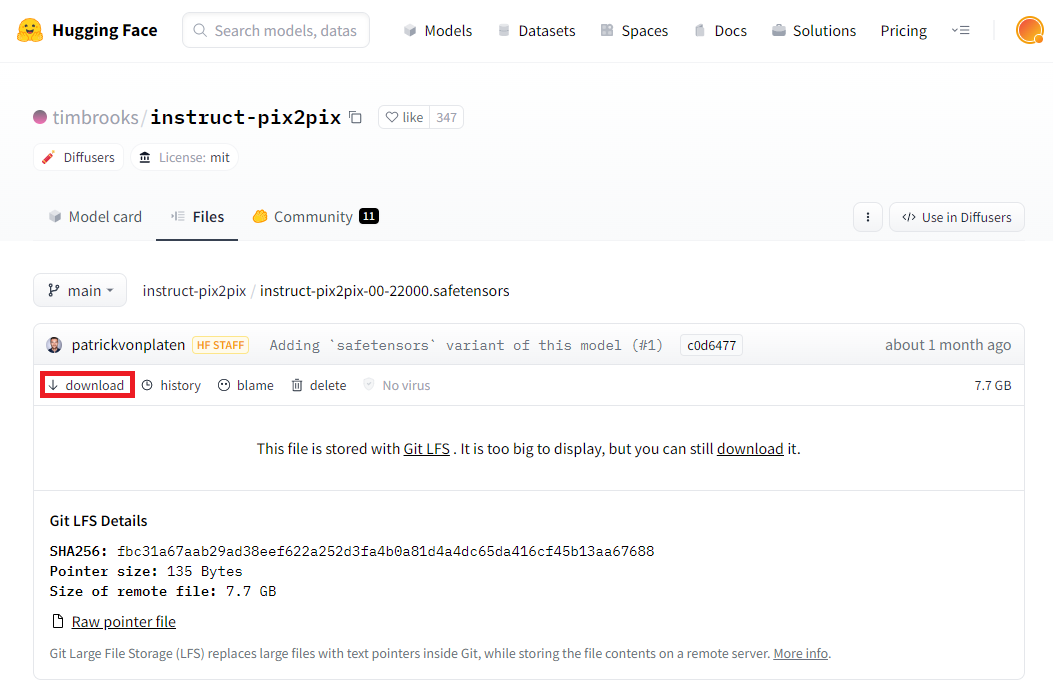
7.7GBもあるので頑張ってダウンロードしてください。また、ダウンロード完了後に必ずサイズを確認してください。
(2)modelsフォルダにダウンロードしたファイルを移動
AUTOMATIC1111をインストールしたフォルダ内の「stable-diffusion-webui/models/Stable-diffusion」以下にダウンロードしたinstruct-pix2pix-00-22000.safetensorsを移動します。
(3)AUTOMATIC1111を起動する
左上のドロップダウンメニューでinstruct-pix2pix-00-22000.safetensorsを選択し、img2imgタブを押します。
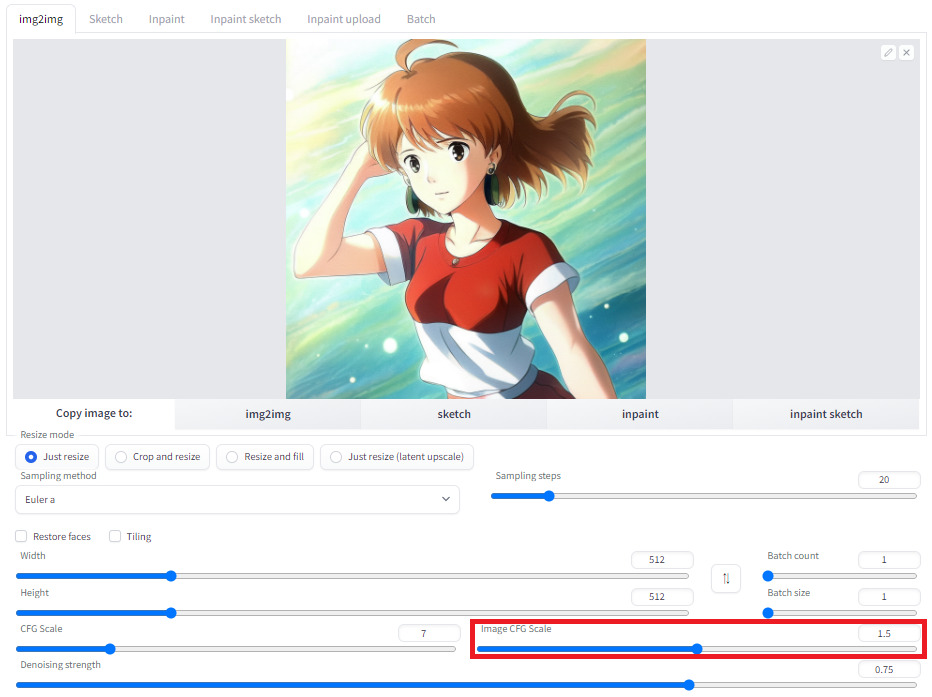
4)img2imgタブでImage CFG Scaleというバーの表示を確認する
pix2pixモデルが選択された事をAUTOMATIC1111が自動認識すると通常のモデルを選択している際には表示されない「Image CFG Scale」というバーが表示されているはずなので、それを確認してください。出てこない場合はもしかしたらAUTOMATIC1111のバージョンが古い可能性があるのでVersionUpを検討してください。
5)効果を加えたい画像をアップロードして、効果を描写したプロンプトを記入してGenerateボタンを押す

例:「彼女を大理石でできたローマ彫刻にします(Make it a marble roman sculpture.)」 ↓

instruct pix2pixを使ってみた感想と使用方法のヒントなど
instruct-pix2pix-00-22000.safetensorsはstable diffusion 1.5をベースにしているそうで、stable diffusion 2.1ベースのモデル(例えば、Waifu Diffusion 1.5)が作成したイラストに対してはあまり編集効果を発揮できないようでした(比較的簡単に思えるプロンプトでもほとんどが無視されてしまう。しかし、後述するImage CFGやText CFGのチューニングを念入りに行ったとは言い難いのと、後から考えてみると768 x 768サイズだったので、これが影響している可能性もあります)。
また、解像度512 x 512で学習しているため、アイキャッチ画像のような解像度を上げた画像の一部分だけを書き換える事も現時点では難しいようです。
当然の事ながらDreamBoothで自分で持ち込んだ概念、例えば、テトという概念はinstruct pix2pixは知らないので、テトを後から追加する事は出来ません。
ただし、本家のgithubには学習データの作り方や学習のさせ方まで丁寧に書いてくれているので、数十万円くらいかければ、自分のカスタムモデル専用のinstruct pix2pixをネイティブトレーニングする事も可能そうです。
公式サイトに書かれているinstruct pix2pixを使用する際の注意点は以下です。
希望する結果が得られない場合は、いくつかの理由が考えられます。
(1)イメージがあまり変わらない
Image CFGの重みが高すぎる可能性があります。この値は、出力が入力にどの程度似ているかを示します。モデルがイラストを編集する際に元の画像からより大きな変更が必要になる可能性がありますが、Image CFGの重みがそれを許可していない可能性があります。または、Text CFG の重みが低すぎる可能性があります。この値は、テキストの指示をどれだけ聞くかを決定します。デフォルトのImage CFG の 1.5 とText CFG の 7.5 は出発点としては適切ですが、全てのケースで最適であるとは限りません。以下を試してみましょう。
・Image CFG の重みを減らす、または
・Text CFG の重みを増やす
(2)逆に、元の画像の細部が保持されないほど画像が変化してしまう
以下を試してみましょう。
・Image CFG の重みを増やす、または
・Text CFG の重みを減らす
(3)「Randomize Seed」を設定し、生成を複数回実行して、異なるランダム シードで結果を生成してみてください。
(4)「Randomize CFG」を設定して、毎回新しい Text CFG と Image CFG 値を使ってイラストを編集する事もできます。
(5)プロンプトを言い換えると、結果が改善されることがあります。
(例えば「彼を犬に変えてください(turn him into a dog)」vs.「彼を犬にしてください(make him a dog)」vs.「犬のように(as a dog)」)。
(6)Sampling steps数を増やすと、結果が改善されることがあります。
(7)顔が変に見えますか?
Stable Diffusionのオートエンコーダーは、画像内の小さな顔を扱う事には苦労します。以下を試してみましょう。
・顔がフレームの大部分を占めるように画像をトリミングします。
instruct pix2pixのデモ
以下、stable diffusion 1.5ベースのカスタムモデルで作成したイラストに対してinstruct pix2pixをやってみた結果です。
元画像

窓を開ける(open a window.)

サングラスをかける(put on a pair of sunglasses.)

彼女の服の色を緑に変える(Change the color of her clothes to green.) 服の色は変えやすい色と変えにくい色があるようでした。

彼女の肩にピカチューを乗せる(Place Pikachu on her shoulder.) 何度もトライしましたがどうしても右側の棚っぽいところに設置しようしてました。

彼女をモナ・リザにする(Make her Mona Lisa.)

彼女をスカーレット・ヨハンソンにする(Make her Scarlett Johansson.)

彼女をレディー・ガガにする(Make her Lady Gaga.)

彼女をエマ・ワトソンにする(Make her Emma Watson.)

彼女をニコラス・ケイジにする(Make her Nicolas Cage.)

う~ん、凄い!
使いどころは工夫する必要がありますが、人力でレタッチを行うより全然早くて強力ですね。
instruct pix2pix、上手に使いこなせれば生成後編集を楽にしてくれる強力なツールになる気がします。
3.instruct pix2pix:プロンプトだけを使ってAIでイラストの修正を行う関連リンク
1)www.timothybrooks.com
InstructPix2Pix Learning to Follow Image Editing Instructions
2)github.com
timothybrooks / instruct-pix2pix (本家のリポジトリ)
Klace / stable-diffusion-webui-instruct-pix2pix (旧:拡張機能のデポジトリ)
3)huggingface.co
timbrooks / instruct-pix2pix(無料で試してみたい方はこちら)
4)nmkd.itch.io
NMKD Stable Diffusion GUI – AI Image Generator

