
1.SadTalker:任意の音声に合わせて口パクする動画を一枚絵から生成(Colab、Spaceあり)まとめ
・任意の音声に合わせて口パクする動画を一枚絵や動画から生成するAIであるSadTalkerが誰でも動かせる形で公開された
・SadTalkerはCVPR 2023で発表予定の最新AI技術でDocker、Colab、Spaceなど様々な形で動かす事ができる
・顔の認識に失敗すると動画ができないケースがあるがイラストなどでもかなり幅広く顔の認識はしてくれる
2.SadTalkerとは?
任意の音声ファイルに合わせて一枚絵の口パク簡単に動画化して動かせる!
と聞いて、え、ほんと?と思ったのですが、まずは以下をご覧ください。
Stable Diffusionで作成したイラスト

SadTalkerで動画化(with 英語音声)
Stable Diffusionで作成したイラスト

SadTalkerで動画化(with 日本語音声)
Stable Diffusionで作成したイラスト

SadTalkerで動画化(横顔)
おっおー、凄いですね、ホントの動画と言われても信じてしまいそうなレベルです。現時点でも相当な水準ですが、これが出来るであれば、あれも出来そう、と様々な応用範囲を思いつきそうですね。
SadTalkerはCVPR 2023で発表予定の最新AI技術で、Docker(公式githubをご覧ください)、Colab+Gradio、Spaceなど様々な動かし方が発表されており、かなり気軽に動かす事ができるので、今後、インターネット上で大流行しそうです。
ただ、イラストの場合、顔の認識に失敗するケースがあるようで、以下の絵柄では動画の作成に失敗しました。チューニングすればどうにかなりそうではありますが、まだ深堀出来ていません。(顔と認識されるものが複数あるとダメ?)



SadTalkerのローカル環境での動かし方
基本、ほぼ公式の手順で動きます。かなりあっさり動いたので拍子抜けしたくらいです。
AUTOMATIC1111 stable-diffusion-webuiでの動かし方
Updateで、全身画像やAUTOMATIC1111の拡張機能として動作させる事ができるようになったそうです。
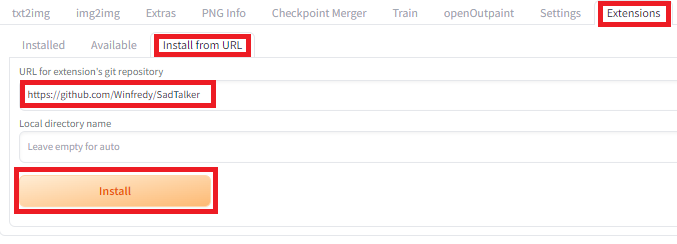
Extensionsタブ -> install from URL -> 「https://github.com/Winfredy/SadTalker」
でインストールできます。
linuxのconda環境でのSadTalkerのインストール
linuxのconda環境前提ですが、以下です。
git clone https://github.com/Winfredy/SadTalker.git cd SadTalker/ conda create -n sadtalker python=3.8 conda activate sadtalker conda install ffmpeg pip install dlib-bin # [dlib-bin is much faster than dlib installation] conda install dlib # 公式の手順と変えたのは以下だけです。 # pytorchのインストールは公式を見て自分の環境に合わせてインストールコマンドを確認した方が良いです conda install pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidia pip install -r requirements.txt pip install git+https://github.com/TencentARC/GFPGAN
SadTalkerのセットアップ
一括ダウンロードコマンドも用意されているの以下で関連モデルを一括ダウンロードできます。全部で4Gくらいです。
bash ./scripts/download_models.sh
SadTalkerのサンプルスクリプト
これも公式サイトのサンプルでほぼそのまま動きます。「./sample/dummy1.wav」と「./sample/sample-1.png」は自分で用意するなり、examples配下にテスト用に使えるサンプルファイルが幾つかあるので.wavなどを用意するのが難しかったら適宜拝借しましょう。日本語の音声(examples/driven_audio/japanese.wav)もあったので本投稿でも拝借しています。
python inference.py --driven_audio ./sample/dummy1.wav \ --source_image ./sample/sample-1.png \ --batch_size 2 \ --expression_scale 1.0 \ --result_dir ./result1 \ --still \ --preprocess crop \ --enhancer gfpgan
成功すると–result_dirで指定したフォルダ以下に日付時刻名フォルダができ、その下に動画ファイルができます。
前述した通り、アニメ系イラストの場合、顔の認識に失敗するケースがあるようですが、その場合は以下のエラーが出ました。
x_full_frames, crop, quad = self.croper.crop(x_full_frames, xsize=pic_size) TypeError: cannot unpack non-iterable NoneType object
このエラーの場合、最初のフレームの特定に失敗するためか、
–result_dir/YYYY_MM_DD.hh.mm.ss/first_frame_dir
に何もファイルが出来きませんでした。
ColabやSpaceもあり、シンプルなインタフェースで非常に強力なので、今後はこれを使ったエイプリルフールネタなどが激増しそうだな、と思います。
試してみたいと思ったは関連リンクよりhuggingface、またはColabをお試しください。
3.SadTalker:任意の音声に合わせて口パクする動画を一枚絵から生成(Colab、Spaceあり)関連リンク
2)github.com
Winfredy / SadTalker
3)huggingface.co
vinthony/SadTalker (気軽に試してみたい方はこちら)
4)colab.research.google.com
SadTalker:quick_demo.ipynb (Colabに慣れている方はこちら)
