
1.PaLM-E:ロボットは邪魔をされても引き出しからポテチを取り出すくらいはできるようになっている(2/2)まとめ
・PaLM-Eはロボット操作タスクと視覚・言語タスクを共通の特徴表現で括ることで、汎化モデルを学習する新しいパラダイムを提供する
・PaLM-Eが個々のタスクで個々のモデルをトレーニングする場合と比較して、性能低下することなく、3種のタスクのセットに同時に対処可能
・PaLM-EはFlamingoやPaLIなど、視覚言語のみのモデルの中で最も優れたモデルと比較しても、競争力のあるモデルである事がわかった
2.PaLM-Eの性能
以下、ai.googleblog.comより「PaLM-E: An embodied multimodal language model」の意訳です。元記事は2023年3月10日、Danny DriessさんとPete Florenceさんによる投稿です。
アイキャッチ画像はPaLM-EのイメージをchatGPT先生に伝えて作って貰ったプロンプトを私が修正してカスタムStable Diffusion先生に作って貰ったイラスト
大規模学習で得た知識をロボットに転移する
PaLM-Eは、ロボット操作タスクと視覚・言語タスクを、画像とテキストを入力とし、テキストを出力するという共通の特徴表現で括ることで、汎化モデルを学習する新しいパラダイムを提供します。PaLM-Eは、視覚と言語の両領域から有意で有用な知識転移を達成し、ロボット学習の有効性を向上させるという重要な結果を得ました。
汎用的な視覚-言語タスクからの知識の有用な知識転移は、より効果的なロボット学習をもたらすことが、3つの異なるロボットの実施形態と領域において示されました。
結果は、PaLM-Eが、個々のタスクで個々のモデルをトレーニングする場合と比較して、性能低下することなく、大規模なロボット、視覚、言語タスクのセットに同時に対処できることを示しています。
さらに、視覚-言語データは、実際にロボットタスクの性能を大幅に向上させます。この転移により、PaLM-Eは、タスクを解くために必要な事例数の観点から見て、ロボットタスクを効率的に学習することができます。
結果
PaLM-Eを3つのロボット環境(うち2つは実際のロボット)で評価し、さらに視覚的質問応答(VQA:Visual Question Answering)、画像へのキャプション付け、汎用的な言語タスクなどの一般的な視覚-言語タスクも評価しました。PaLM-Eがロボットの意思決定を行う事が必要なタスクの場合、テキストを低レベルのロボットアクションに翻訳する低レベルな言語-アクションポリシーとペアにして実行しています。
下の最初の例では、ある人がモバイルロボットにポテトチップスの袋を持ってくるように頼んでいます。このタスクを成功させるために、PaLM-Eは引き出しを見つけて開けるという計画を作成し、タスクを実行しながら計画を更新することで現実世界が変化する事に対応します。
2つ目の例では、ロボットは緑色のブロックをつかむように要求されています。そのロボットはブロックを見たことがないにもかかわらず、PaLM-Eはそのロボットの学習データを超えて汎化するステップバイステップの計画を生成します。


PaLM-Eは、キッチン環境で動作する移動ロボットを制御します。
左:タスクはポテトチップスの袋を取ることです。PaLM-Eは、ポテトチップスの袋を引き出しに戻すというような邪魔に対して堅牢であることがわかる。右:初見のブロック(緑色の星)を取り上げる計画を実行する最終ステップ。この機能は、視覚モデルと言語モデルからの転移学習によって促進されています。
下の2つ目の環境では、同じPaLM-Eモデルが、別のタイプのロボットで「ブロックを色ごとにコーナーに並べ替える」といった非常に長期目線が必要な精密なタスクを解決しています。例えば、「青い立方体を右下に押す」、「青い三角形もそこに押す」といった具合に、画像を直接見て、テキストで表現した短い行動の順番を生成するのです。
Googleの最新モデルでも、自律的に完了させることが困難であった長期的なタスクが可能になりました。また、赤いブロックをコーヒーカップに押し付けるなど、学習時にやった事がなかった新しいタスクへの汎化(ゼロショット汎化)能力も実証しています。

PaLM-Eは卓上ロボットを制御し、長期目線が必要なタスクを成功させます
第3のロボット環境は、タスク&モーションプランニング(TAMP:Task And Motion Planning)の分野から着想を得ており、非常に多くの行動順が取れる状況をロボットに突きつける、組み合わせ的に難しい計画タスク(物体の再配置)を研究しています。
PaLM-Eは、TAMPのエキスパートプランナーから得たわずかな学習データで、これらのタスクを解決できるだけでなく、より効果的に解決するために、視覚と言語の知識伝達を活用することができることを示しました。


PaLM-Eでタスク&モーションプランニング環境の計画を作成
視覚と言語に関する総合的な知識を持つモデルであるPaLM-Eは、FlamingoやPaLIなど、視覚言語のみのモデルの中で最も優れたモデルと比較しても、競争力のあるモデルであることがわかります。
特に、PaLM-E-562Bは、視覚理解だけでなく、世界の外部知識も必要とする難易度の高いOK-VQAデータセットにおいて、これまで報告された中で最も高い数値を達成しました。さらに、この結果は、そのタスクだけに特化した微調整を行わなない汎用のモデルとして到達しています。
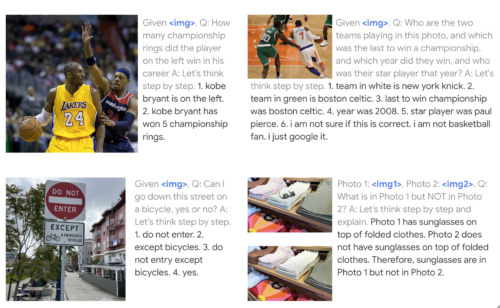
PaLM-Eは、これまで言語のみの領域で実証されてきた、回答プロセスをより小さなステップに分解する視覚的な思考の連鎖推論などの能力を示しています。また、単一画像のプロンプトに対してのみ学習させたモデルでありながら、複数の画像に対して推論を行う能力も示しています。ニューヨーク・ニックスとボストン・セルティックスの画像はCC-by-2.0に基づき、kowarskiによってFlickrに投稿されたものです。コービー・ブライアントの画像はPublic Domainです。その他の画像は、私たちが撮影したものです。
まとめ
PaLM-E は、視覚、言語、ロボット工学を同時に扱う汎用的なモデルを訓練し、視覚と言語からロボット工学の領域へ知識を伝達することができるという境界を押し広げるものです。さらに、PaLM-Eでニューラルネットによる風景の特徴表現をどのように活用するか、また、モデル規模が大きくなったPaLM-Eで、言語能力の致命的な忘却がどの程度少なくなるかなど、論文でさらに詳しく調査されたトピックがあります。
PaLM-E は、他のデータソースを活用したより高性能なロボットの構築への道筋を示すだけでなく、マルチモーダル学習を用いた他の幅広い応用への鍵となる可能性があり、これまでは別々に見えていたタスクを統合する能力も備わっています。
謝辞
この研究は、GoogleのRobotics at GoogleチームやBrainチームなど複数のチーム、およびベルリン工科大学との共同作業で行われました。
共著者: Igor Mordatch、Andy Zeng、Aakanksha Chowdhery、Klaus Greff、Mehdi S. M. Sajjadi、Daniel Duckworth、Corey Lynch、Ayzaan Wahid、Jonathan Tompson、Fei Xia、Brian Ichter、Karol Hausman、Tianhe Yu、Quan Vuong、Evgen Chebotar、Wenlong Huang、Pierre Sermanet、Sergy Levine、Vincent Vanhoucke、Marc Toussiant。
Dannyは、ベルリン工科大学のMarc Toussaintが指導する博士課程の学生です。また、Xi Chen、Etienne Pot、Sebastian Goodman、Maria Attarian、Ted Xiao、Keerthana Gopalakrishnan、Kehang Han、Henryk Michalewski、Neil Houlsby、Basil Mustafa、Justin Gilmer、Yonghui Wu、Erica Moreira、Victor Gomes、Tom Duerig、Mario Lucic、Henning MeyerおよびKendra Byrnなどの同僚に助言と助けに感謝したいです。
3.PaLM-E:ロボットは邪魔をされても引き出しからポテチを取り出すくらいはできるようになっている(2/2)関連リンク
1)ai.googleblog.com
PaLM-E: An embodied multimodal language model
2)palm-e.github.io
PaLM-E: An Embodied Multimodal Language Model

