
1.Spotlight:視覚情報のみを使ってアプリのユーザーインターフェースを理解して改善(2/2)まとめ
・Spotlightは、4つ下流タスクにおいて4つの従来手法を大幅に上回るスコアを達成する事ができた
・モデルが注目している領域を確認したところ、タスクによって注目領域を変えている事も確認できた
・最近の大規模な視覚-言語モデルと比較するとSpotlightは比較的小さく規模拡大による性能向上の余地を残している
2.Spotlightの性能
以下、ai.googleblog.comより「A vision-language approach for foundational UI understanding」の意訳です。元記事は2023年2月24日、Yang LiさんとGang Liさんによる投稿です。
アイキャッチ画像はstable diffusionのカスタムモデルによる生成でスポットライトを浴びる女優さんを連想させるように描いたイラスト
結果
2つのラベルなしデータセット(C4コーパスに基づく内製データセットと内製モバイルデータセット)、250万のモバイルUI画面と8000万のウェブページでSpotlightモデルを事前学習させます。
次に、4つの下流タスク(キャプション、要約、言葉に基づいて場所を理解、指定された場所がタップ可能か否かを予測(tappability))のそれぞれについて、事前に訓練されたモデルを個別に微調整します。
ウィジェット説明文付与と画面要約のタスクについては、CIDErスコアを報告します。これは、モデルのテキスト記述が、人間の評価者によって作成された参照データセットとどれだけ似ているかを測定するものです。
言葉に基づいた場所の理解(command grounding)は、ユーザからの指示に応答してモデルがターゲットの位置を特定できた割合を示す精度を報告しています。タップ可能性予測については、タップ可能なオブジェクトとタップ不可能な物体を見分けるモデルの能力を測定するF1スコアを報告します。
この実験では、Spotlightをいくつかのベンチマークモデルと比較しました。
Widget Captionは、ビュー階層と各UIオブジェクトの画像を使用して、オブジェクトのテキスト説明を生成します。同様に、Screen2Wordsは、ビュー階層とスクリーンショットに加え、補助的な機能(アプリの説明など)を使用して、画面の要約を生成します。同様に、VUTは、複数のタスクを実行するために、スクリーンショットとビュー階層を組み合わせています。最後に、オリジナルのTappabilityモデルは、ビュー階層とスクリーンショットから物体のメタデータを活用し、画面内のパーツがタップ可能か否かを予測します。
Tappabilityの後続モデルであるTaperceptionは、視覚のみを使ってタップ可能性予測アプローチを使用しています。私たちは、2つのサイズのViT、B/16版とL/16版を土台に使用した2つのSpotlightモデルのバリエーションを検証しました。Spotlightは、4つのUIモデリングタスクにおいて、最先端技術を大幅に上回りました。
| Model | Captioning | Summarization | Grounding | Tappability | |
| Baselines | Widget Caption | 97 | – | – | – |
| Screen2Words | – | 61.3 | – | – | |
| VUT | 99.3 | 65.6 | 82.1 | – | |
| Taperception | – | – | – | 85.5 | |
| Tappability | – | – | – | 87.9 | |
| Spotlight | B/16 | 136.6 | 103.5 | 95.7 | 86.9 |
| L/16 | 141.8 | 106.7 | 95.8 | 88.4 |
さらに、マルチタスクモデルはモデルのサイズやメモリ使用量を大幅に削減できるため、モデルに複数のタスクを同時に学習させるという、より困難な設定を追求しました。下表に示すように、実験の結果、私たちのモデルは依然として競争力のある性能を発揮していることがわかりました。
| Model | Captioning | Summarization | Grounding | Tappability |
| VUT multi-task | 99.3 | 65.1 | 80.8 | – |
| Spotlight B/16 | 140 | 102.7 | 90.8 | 89.4 |
| Spotlight L/16 | 141.3 | 99.2 | 94.2 | 89.5 |
Region Summarizerが、どのようにしてSpotlightが画面上のターゲット領域や関連領域にフォーカスすることを可能にしているのかを理解するために、ウィジェットの説明文付与タスクと画面要約タスクの両方について、attentionの重み(モデルがスクリーンショット上のどこに注目したかを示します)を分析しました。
下図では、ウィジェットの説明文付与タスクにおいて、モデルは左側のチェックボックス(赤い境界ボックスで強調しています)に対して「チェルシーチームを選択する」と予測しました。
右側のattentionヒートマップ(attentionの重みの分布を示す)を見ると、モデルはチェックボックスのターゲット領域だけでなく、左端のテキスト「Chelsea」にも注目して説明文生成を学習することがわかります。画面要約の例では、左のスクリーンショットから「学習アプリのチュートリアルを表示するページ」と予測します。この例では、対象領域は画面全体であり、画面上の重要な部分に注目して要約することを学習しています。
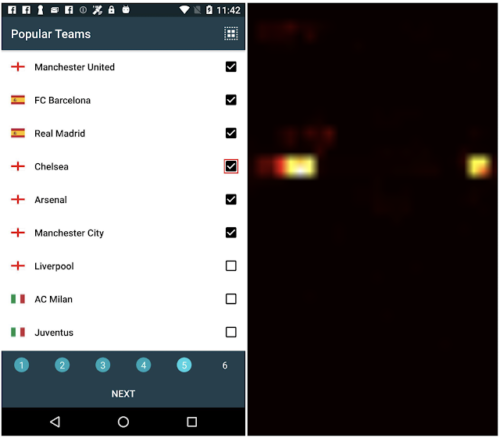
ウィジェットの説明文生成タスクでは、説明文生成時に、チェックボックス、すなわち対象物とその左のテキストラベルにモデルが注目している事を示すattentionヒートマップが示されています。図中の赤い境界ボックスは説明用です。
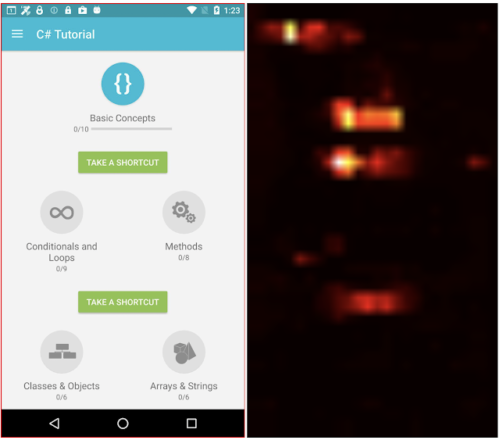
対象領域が画面全体を囲む画面要約タスクでは、要約生成に寄与する画面上の様々な場所にモデルが注目していることがattentionヒートマップで確認できます。
結論
私たちは、Spotlightがスクリーンショットと文書化されたビュー階層構造の両方を入力として使用する従来の方法を凌駕し、複数の代表的なUIタスクにおいて最先端の結果を確立することを実証します。
これらのタスクは、アクセシビリティ、自動化、インタラクションデザイン、評価など多岐にわたります。モバイルUI理解のための視覚のみのアプローチは、文書化されたビュー階層構造を使用する必要性を軽減し、アーキテクチャを容易に拡張することができ、汎用領域用に事前に訓練された大規模な視覚-言語モデルの成功から利益を得ることができます。
FlamingoやPaLIといった最近の大規模な視覚-言語モデルの取り組みと比較すると、Spotlightは比較的小さく、私たちの実験では、より大きなモデルがより良い性能をもたらすという傾向を示しています。Spotlightは、より多くのUIタスクに簡単に適用でき、多くの操作やユーザー体験タスクの最前線を前進させる可能性があります。
謝辞
インターネットの事前学習用データセットの処理に協力してくれたMandar JoshiとTao Li、論文の校正にフィードバックしてくれたChin-Yi ChengとForrest Huangに感謝します。本投稿のアニメーション図の作成に協力してくれたTom Smallに感謝します。
3.Spotlight:視覚情報のみを使ってアプリのユーザーインターフェースを理解して改善(2/2)関連リンク
1)ai.googleblog.com
A vision-language approach for foundational UI understanding
2)arxiv.org
Spotlight: Mobile UI Understanding using Vision-Language Models with a Focus

