
1.Scaled Q-learning:強化学習も大規模言語モデルみたいに事前学習をしたいです(2/2)まとめ
・Scaled Q-Learningは強化学習であるにも関わらず規模を拡大する事が有利になるべき乗スケーリング特性を持っている
・オフラインデータで初期化してから微調整を評価する設定では従来手法を大幅に上回る性能を発揮する事ができる
・Scaled Q-learningは視覚的特徴表現を提供するのではなく、実際にゲームの動きの特徴表現を学習している事が示唆される
2.Scaled Q-learningの性能
以下、ai.googleblog.comより「Pre-training generalist agents using offline reinforcement learning」の意訳です。元記事の投稿は2023年2月24日、Yang LiさんとGang Liさんによる投稿です。
アイキャッチ画像はstable diffusionのカスタムモデルによる生成
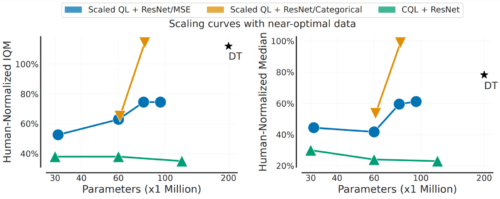
さらに、以下に示すように、Scaled Q-Learningは性能面でも向上していますが、規模拡大が有利に働く特性も享受しています。
これは、ネットワークサイズが大きくなるにつれて、事前学習した言語モデルや視覚モデルの性能が向上するのと同じです。一般的に「べき乗スケーリング(power-law scaling)」と呼ばれるものを享受するため、Scaled Q-learningの性能も同様のスケーリング特性を持つことを示します。
これは驚くべきことではないかもしれませんが、RLではこのような規模拡大は困難であり、モデルサイズが大きくなると性能が悪化することが多いのです。このことは、Scaled Q-Learningと上記の設計上の選択を組み合わせることで、オフラインRLが大規模モデルを利用する能力をよりよく発揮できることを示唆しています。
新しいゲームや亜種への微調整
このオフライン初期化からの微調整を評価するために、2つの設定を検討しました。
(1)ゲームプレイの2M遷移(2M transitions of gameplay)に相当する、あるゲームからの少量のオフラインデータで、全く見たことのない新しいゲームに微調整を行う。
(2)ゲームの新しい亜種への微調整(オンライン設定)
オフラインのゲームプレイデータからの微調整は、以下の図のようになります。
なお、この条件は、新しいゲームのオフラインデータが比較的高品質であるため、模倣型手法であるDecision Transformerや行動クローンには一般に有利です。
それでも、ほとんどの場合、Scaled Q-learningは代替的なアプローチよりも改善され(平均80%)、MAEやCPCなどの専用の特徴表現学習法も、オフラインデータを使用して価値関数ではなく視覚特徴表現を学習するのみであることがわかります。
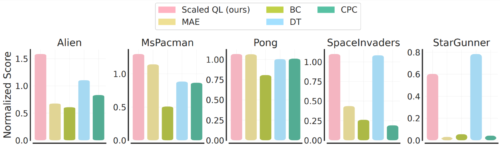
オンライン設定では、Scaled Q-learningを用いた事前トレーニングにより、さらに大きな改善が見られます。この場合、MAEのような特徴表現学習法は、オンラインRL中に最小限の改善しかもたらしませんが、Scaled Q-Learningは、事前トレーニングのゲームに関する事前知識をうまく統合し、2万回のオンライン対話ステップ後に最終スコアを大幅に向上させることができます。
これらの結果は、マルチタスクオフラインRLで一般的な価値関数バックボーンを事前トレーニングすることで、オフラインとオンラインの両方で、下流タスクのRL性能を大幅に向上させることができることを示しています。
なお、このような微調整は非常に難しいです。様々なAtariゲーム、さらには同じゲームの亜種でさえ、外観や動きが大きく異なります。例えば、「ブレイクアウト」の場合、下図のような亜種ではターゲットブロックが消えてしまい、コントロールが難しくなっています。
しかし、Scaled Q-learningが、特にMAEやCPCのような視覚特徴表現学習技術と比較して成功していることは、モデルが単に優れた視覚的特徴表現を提供するのではなく、実際にゲームの動きの特徴表現を学習していることを示唆しています。
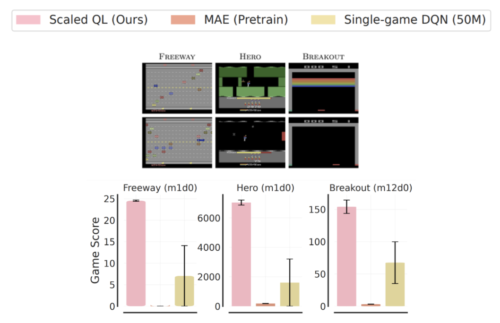
Freeway、Hero、Breakoutの各ゲームをオンラインRLで微調整したもの
各図の下段には微調整に使用した新しい亜種が、上段には事前学習で使用した元のゲームが示されています。Scaled Q-Learningによる微調整は、MAE(視覚特徴表現学習法)および単一ゲームDQNによるゼロからの学習を大幅に上回っています。
結論とお持ち帰り頂きたい事
私達は、CQLアルゴリズムをベースとした、規模拡大可能なオフラインRLの事前学習法であるScaled Q-Learningを発表し、マルチタスクトレーニングのための効率的なオフラインRLを可能にする方法を実証しました。
この研究は、高価で複雑なシミュレーションベースのパイプラインや大規模な実験に代わる、より実用的なRLエージェントの実世界でのトレーニングを可能にするための最初の進歩です。
おそらく長期的には、同様の研究により、大規模なオフライン事前訓練から、広範囲に適用可能な探索および対話的スキルを開発する、汎用的で有能な事前訓練済みRLエージェントが実現されるでしょう。
ロボット工学(いくつかの初期結果を参照)やNLPなどの領域で、より現実的なタスクの広い範囲でこれらの結果を検証することは、今後の研究の重要な方向性です。オフラインRL事前訓練は多くの可能性を秘めており、今後の研究でこの分野の多くの進歩が見られると期待しています。
謝辞
この研究は、Aviral Kumar、Rishabh Agarwal、Xinyang Geng、George Tucker、Sergey Levineによって行われました。評価用のマルチゲーム判定変換コードベースとマルチゲームAtariベンチマークを手伝ってくれたSherry Yang、Ofir Nachum、Kuang-Huei Lee、イラストとアニメーションを提供してくれたTom Smallに感謝します。
3.Scaled Q-learning:強化学習も大規模言語モデルみたいに事前学習をしたいです(2/2)関連リンク
1)ai.googleblog.com
Pre-training generalist agents using offline reinforcement learning
2)openreview.net
Offline Q-learning on Diverse Multi-Task Data Both Scales And Generalizes

