
1.Scaled Q-learning:強化学習も大規模言語モデルみたいに事前学習をしたいです(1/2)まとめ
・強化学習は学習結果の流用が難しく、ゼロから学習するのは非常にお金がかかるので敷居を下げる様々な工夫が考案されている
・Scaled Q-learningは強化学習において事前学習を活用して汎用的に使えるバックボーンが実現できるかを調査した手法
・Transformersベースの手法や模倣学習と比較してScaled Q-learningは人間に迫るレベルを達成できた唯一の手法であった
2.Scaled Q-learningとは?
強化学習は学習結果の流用が難しく、更に、ゼロから学習するのは非常にお金がかかるという敷居の高さがありましたが、Reincarnating Reinforcement Learningや今回のScaled Q-learningが汎用的に使える事前学習モデルになるのであれば、以降、大きな変革が起きる可能性がありますね。
アイキャッチ画像はstable diffusionのカスタムモデルによる生成で「Q」で始まるイラスト化しやすい単語を探したところQípáo(チャイナドレス)とQueenくらいしかなかったので、チャイナドレスを着た女王っぽいイラストになりました。
強化学習(RL:Reinforcement learning)アルゴリズムは、ゲームをプレイしたり、ロボットが物体を拾ったり、あるいはマイクロチップの設計を最適化したりといった意思決定タスクを解決するためのスキルを学習します。
しかし、RLアルゴリズムを実世界で実行するには、高価な動的データ収集の仕組みが必要です。
多様なデータセットでの事前学習により、自然言語処理(NLP:Natural Language Processing)や視覚問題における個々の下流タスクで、データ効率が良い微調整が可能になることが証明されています。
BERTやGPT-3モデルがNLP用に汎用的な初期化を提供できるのと同様に、大規模なRL事前学習済みモデルは意思決定用に汎用的な初期化を提供することができます。
そこで、私達は問います。
RLを高速化するために同様の事前学習を行い、様々なタスクで効率的なRLのための汎用的な「バックボーン」を作ることはできないでしょか?
ICLR 2023で発表される「Offline Q-learning on Diverse Multi-Task Data Both Scales and Generalizes」では、以前に収集した静的データセットで価値関数を学習するために使用できるオフラインRLを、このような汎用的な事前学習法を提供するためにどのように拡張したかを説明します。私達は、多様なデータセットを用いたScaled Q-Learningが、新規タスクへの迅速な移行とタスクの新しいバリエーションでの高速オンライン学習を促進する特徴表現学習に十分であり、既存の特徴表現学習アプローチや、はるかに大きなモデルを用いるTransformerベースの方法よりも大幅に改善することを実証します。
Scaled Q-learning:保守的なQ-learningによるマルチタスク事前学習
汎用的な事前学習アプローチを提供するために、オフラインRLは規模拡大可能である必要があります。
これにより、オフラインRLで様々なタスクのデータで事前学習を行い、表現力豊かなニューラルネットワークモデルを利用して、個々の下流タスクに特化した強力な事前学習済みのバックボーンを獲得することを可能になります。
私たちは、オフラインRLの事前学習法として、CQL(Conservative Q-Learning)をベースにしました。CQLは、標準的なQ-learningの更新と、未知のアクションの値を最小化する追加の正則化を組み合わせた、シンプルなオフラインRL手法です。
離散的な行動では、CQLの正則化は標準的なクロスエントロピー損失と同等であり、これは標準的なディープQ-learningのシンプルな1行の修正です。いくつかの重要な設計上の決定がこれを可能にしています。
・ニューラルネットの大きさ
マルチゲームのQ-learningには、大規模なニューラルネットワークアーキテクチャが必要であることがわかりました。先行する手法では、比較的浅い畳み込みネットワークを使用することが多いのですが、ResNet 101と同規模のモデルが、より小さなモデルよりも大きな改善をもたらすことが分かりました。
・ニューラルネットワークアーキテクチャ
新規ゲームに有効な事前学習済みのバックボーンを学習するため、最終的なアーキテクチャでは、ニューラルネットワークのバックボーンを共有し、各ゲームのQ値を出力する分離した1層ヘッドを別々に使用しています。この設計により、事前学習中のゲーム間の干渉を回避しつつ、単一の共有特徴表現を学習するのに十分なデータの共有が可能になります。また、共有視覚のバックボーンは、学習された位置embedding(Transformerモデルに似ています)を利用して、ゲーム内の空間情報を追跡しています。
・特徴表現の正則化
最近の研究では、Q-learningは特徴表現崩壊の問題に悩まされる傾向があり、大規模なニューラルネットワークであっても効果的な特徴表現を学習できないことがあることが分かっています。
この問題に対処するため、私達は先行研究を活用し、Q-ネットワークの共有部分の最終層の特徴を正規化しました。さらに、Q-learningには、より豊かな特徴表現を提供し、下流のタスクパフォーマンスを向上させることが知られているカテゴリ分布型RL損失を利用しました。
マルチタスクAtariベンチマーク
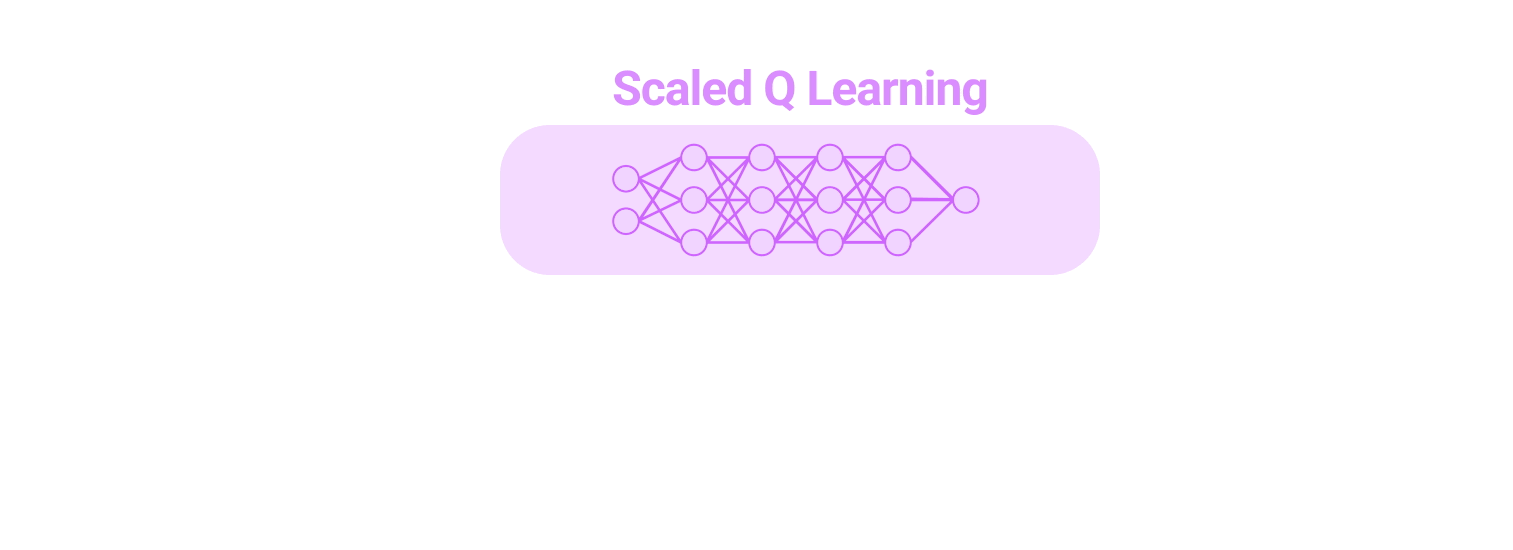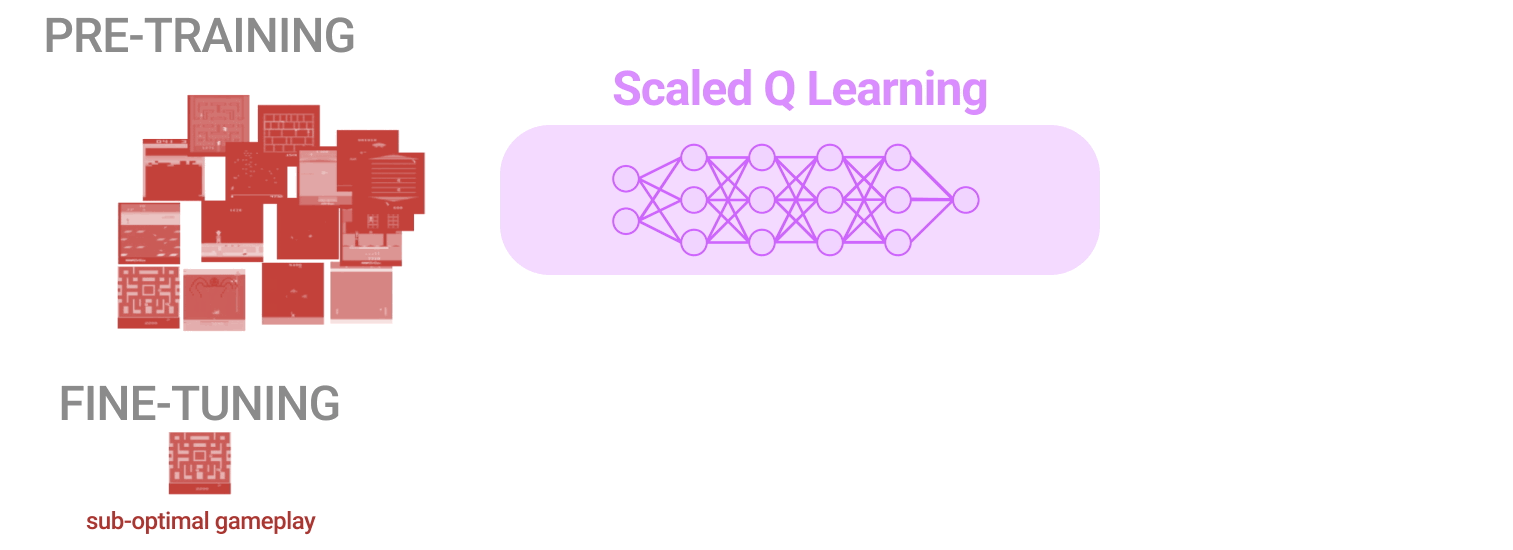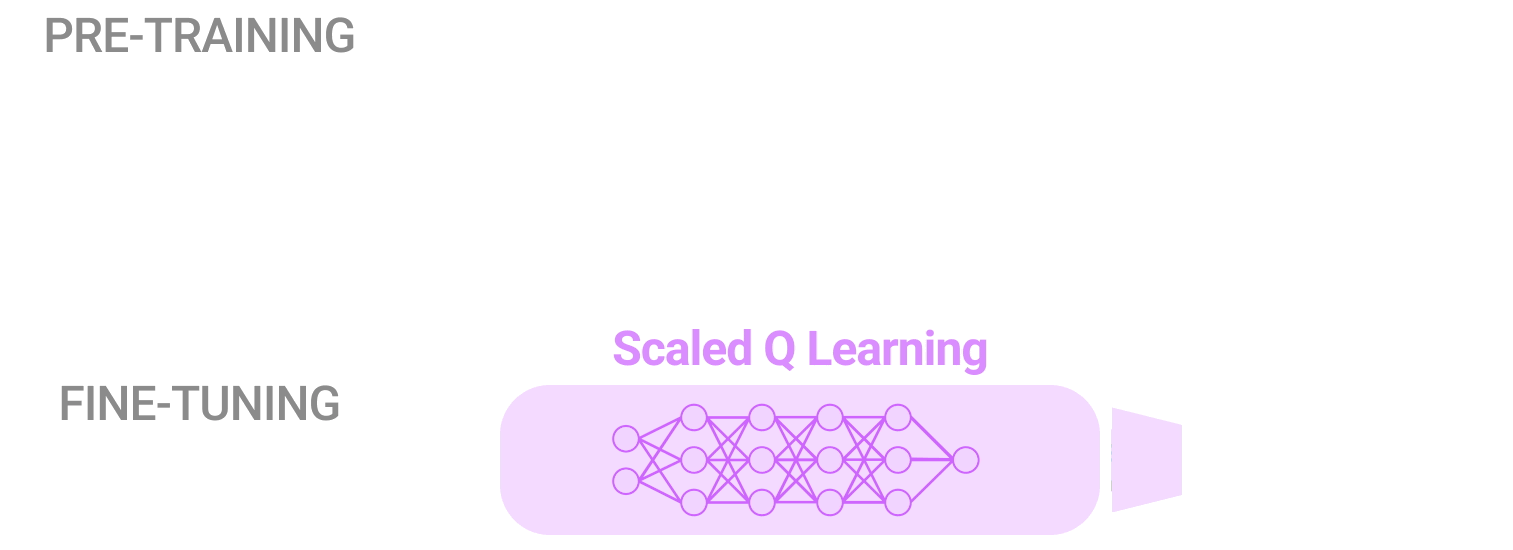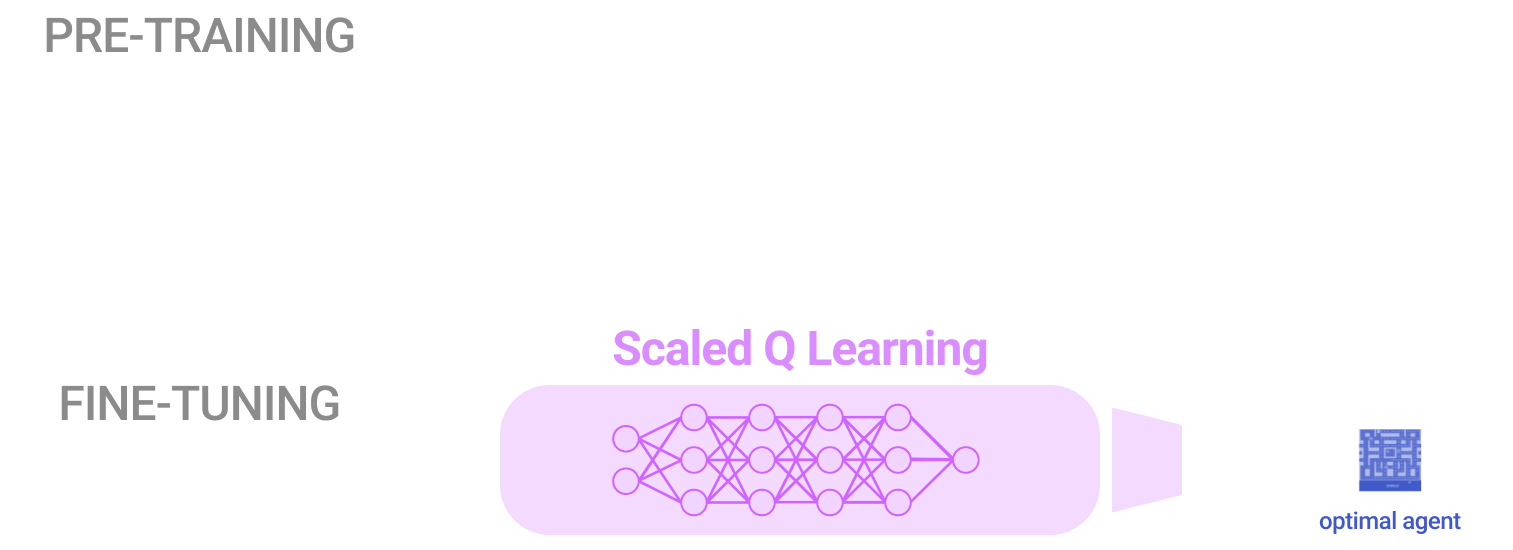
私達は、規模拡大可能なオフラインRLのためのアプローチを、Atariゲーム群で評価しました。
ここでは、低品質(すなわち、最適でない)プレイヤーによる異なったデータを用いて、単一のRLエージェントを訓練して、ゲームのコレクションをプレイすることを目標とします。そして、その結果得られたネットワークバックボーンを使用して、事前トレーニングゲームや全く新しいゲームの新しいバリエーションを迅速に学習します。
各ゲームは異なる戦略と異なる特徴表現を必要とするため、多くの異なるアタリゲームをプレイできる単一のポリシーを訓練することは、標準的なオンライン深層RL手法を用いても十分に困難です。
オフライン環境では、multi-game decision transformersなどの先行研究が、transformersのような大規模なニューラルネットワークアーキテクチャで規模拡大する試みとして、RLを完全に廃止し、代わりに条件付き模倣学習を利用することを提案したことがあります。
しかし、本研究では、CQLを採用し、以下に述べるいくつかの慎重な設計上の決定と組み合わせることで、この種のマルチゲーム事前学習がRLを介して効果的に行えることを示すものです。
ゲームプレイ時の性能
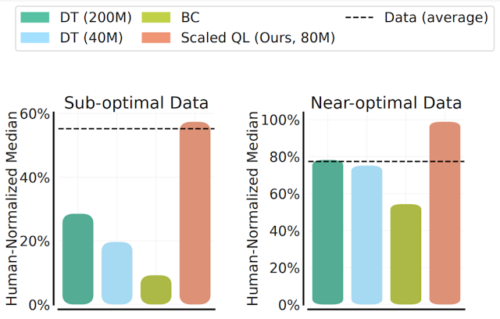
2つのデータ構成を用いて、Scaled Q-Learning法の性能と規模拡大可能性を評価します。
(1) 最適に近いデータ(near optimal data)。過去のRL実行のリプレイバッファに現れる全てのトレーニングデータからなります
(2) 低品質データ。リプレイバッファに含まれる試行の最初の20%のデータ(すなわち、高度に最適されていないポリシーのデータのみ)から構成されます。
以下の結果では、8000万パラメータのScaled Q-Learningモデルを、4000万または8000万(訳注:原文は80-millionですが、下図を見る限りおそらく2億です)パラメータモデルのmulti-game decision transformers(DT)、および行動クローニング(つまり模倣学習)のベースライン(BC)と比較しています。
この結果、Scaled Q-Learningはオフラインのデータにより改善され、正規化した人間のパフォーマンスの約80%を達成する唯一のアプローチであることが確認されました。
3.Scaled Q-learning:強化学習も大規模言語モデルみたいに事前学習をしたいです(1/2)関連リンク
1)ai.googleblog.com
Pre-training generalist agents using offline reinforcement learning
2)openreview.net
Offline Q-learning on Diverse Multi-Task Data Both Scales And Generalizes

