
1.SRRとSPADE:自己教師/半教師あり学習で完全教師あり学習を凌駕する異常検知(2/2)まとめ
・多くの半教師あり学習法は、ラベル付きデータとラベル無しデータが同じ分布を持つと仮定しているが現実は異なる事が多い
・SPADEはラベル無しデータの擬似ラベルを推定するために1クラス分類器のアンサンブルを利用して異常値を検出する
・これにより分布の差異や新しいタイプの異常など幅広いシナリオに最先端のスコアを達成する異常検知性能を示す事が可能
2.SPADEとは?
以下、ai.googleblog.comより「Unsupervised and semi-supervised anomaly detection with data-centric ML」の意訳です。元記事は2023年2月8日、Jinsung YoonさんとSercan O. Arikさんによる投稿です。
アイキャッチ画像は、Waifu Diffusion 1.5 Betaのカスタムモデルによる生成
SPADE:擬似ラベル付与とアンサンブルで異常検知する半教師あり学習
多くの半教師あり学習法(例:FixMatch、VIME)は、ラベル付きデータとラベル無しデータが同じ分布を持つと仮定しています。しかし、実際には、ラベル付きデータとラベル無しデータが異なる分布から来るという分布のミスマッチがよく起こります。
そのようなケースの一つが、正でラベルなし(PU:Positive and Unlabeled)、または、負でラベルなし(NU:Negative and Unlabeled)の設定です。これは、ラベル付きデータ(正または負)とラベルなしデータ(正と負の両方)のサンプル間の分布が異なっている場合です。
分布シフトのもう一つの原因は、ラベリング後に未ラベルのデータが追加で収集されることです。例えば、製造工程が進化し続けることで、対応する欠陥が変化し、ラベリング時の欠陥の種類が未ラベリング時の欠陥の種類と異なることがあります。
また、金融詐欺の検知やアンチマネーロンダリングなどのアプリケーションでは、犯罪行動が新に作り出される可能性があるため、データのラベリング処理後に新たな異常が現れることがあります。
最後に、ラベル付け作業者がラベル付けを行う場合、簡単なサンプルは自信を持ってラベルをつけるため、簡単なサンプルはラベル付きサンプル、難しいサンプルはラベルなしサンプルに振り分けられる可能性が高くなります。
例えば、クラウドソーシングに基づくラベリング作業では、(確信度の指標として)ラベルについてある程度の同意が得られたサンプルだけがラベル付き集合に含まれるものがあるためです。

分布の不一致を伴う3つの一般的な実世界シナリオ(青枠:正常なサンプル、赤枠:既知/容易な異常サンプル、黄枠:新しい/困難な異常サンプル)
標準的な半教師付き学習法は、ラベル付きデータとラベルなしデータが同じ分布から来ることを前提としているため、分布の不一致がある場合の半教師付き異常検出(AD:Anomaly Detection)手法には最適とは言えません。
SPADEはラベル無しデータの擬似ラベルを推定するためにOCCのアンサンブルを利用します。これは、与えられた正のラベル付きデータとは独立して行われるため、ラベルへの依存度が低くなります。そのため、分布の不一致がある場合に特に有効です。
さらに、SPADEは部分マッチングを用いて、ラベル付き検証データに依存することなく、擬似ラベルのための重要なハイパーパラメータを自動的に選択します。これは、ラベル付きデータが限られている場合に非常に重要な機能です。
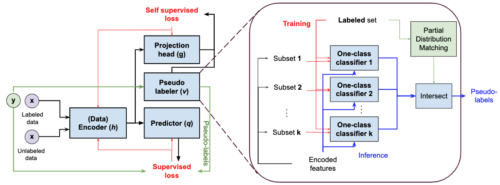
SPADEのブロック図(提案する擬似ラベラーの詳細ブロック図を拡大したもの)
SPADEの結果
私達は、分布の不一致を伴う半教師付き学習の様々な実環境におけるSPADEの利点を示すために、広範な実験を行いました。画像データ(MVTecを含む)、表形式データ(Covertype、Thyroidを含む)の複数のADデータセットを検討しました。
SPADEは様々なシナリオにおいて、最先端の半教師付き異常検知性能を示します。
(i)新しいタイプの異常
(ii)ラベル付けが容易なサンプル
(iii)ラベル付けされていない正のサンプル
といった幅広いシナリオにおいて、最新の半教師付き異常検知性能を示します。
以下に示すように、新しいタイプの異常を検出した場合、SPADEは平均で5%のAUCで最先端技術を上回る性能を示しました。
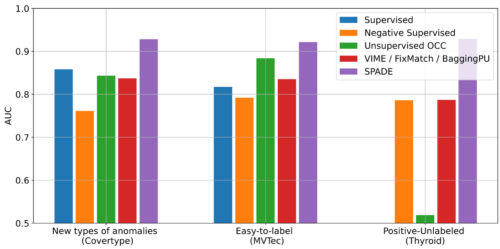
様々なデータセット(Covertype、MVTec、Thyroid)において、3つの異なるシナリオでのADの性能をAUCの観点で示します。いくつかの比較対象手法は、いくつかのシナリオにしか適用できません。他の比較対象手法やデータセットでの詳細な結果は論文に記載されています。
また、実世界の金融詐欺検出データセットでSPADEを評価しました。Kaggleクレジットカード詐欺とXente詐欺検出です。
これらのデータセットでは、異常は進化し(すなわち、その分布は時間とともに変化する)、進化する異常を識別するためには、新しい異常に対するラベリングを継続し、ADモデルを再トレーニングする必要があります。しかし、ラベリングにはコストと時間がかかります。SPADEは、ラベリングを追加しなくても、ラベル付きデータと新たに収集したラベルなしデータの両方を用いてADの性能を向上させることができます。
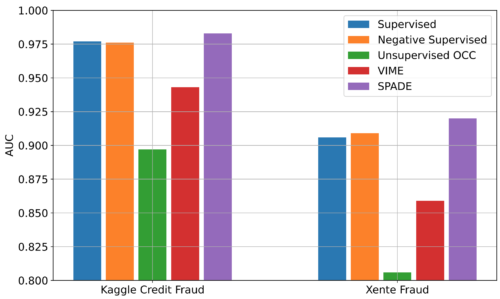
ラベリング率10%の2つの実世界不正検知データセットを用いた、時間で変動する分布に対するADの性能。その他の比較対象手法は論文に記載されています。上記のように、SPADEは両データセットにおいて、ラベル付けされていないデータを活用し、進化する分布に対して堅牢であることを示し、一貫して代替案を上回りました。
結論
異常検出(AD:Anomaly Detection)は、金融システムのセキュリティ脅威の検出から製造機械の欠陥動作の特定まで、実世界のアプリケーションにおいて重要な意味を持つ幅広い用途を持っています。
ADシステムを構築する上で困難かつコストがかかる点として、異常が稀であり、人が容易に検出できないことが挙げられます。
そこで、学習用の手動ラベルを必要としない高性能なADを実現するために、正統派ADフレームワークであるSRRを提案しました。SRRは、あらゆる1クラス分類器(OCC:One-Class Classifier)と柔軟に統合でき、生データや学習可能な特徴表現に対して適用することができます。
半教師付きADも非常に重要な課題です。多くのシナリオで、ラベル付きサンプルとラベルなしサンプルの分布は一致しません。SPADEは、OCCのアンサンブルを用いた堅牢な擬似ラベリング機構と、教師あり学習と自己教師あり学習を適切に組み合わせる方法を導入しています。さらに、SPADEは、データ効率の良いADの重要な要素である検証セットなしで、重要なハイパーパラメータを選択する効率的な手法を導入しています。
全体として、SRRとSPADEは、様々な種類のデータセットにおける様々なシナリオにおいて、一貫して他の選択肢を凌駕することを実証しています。
謝辞
Kihyuk Sohn, Chun-Liang Li, Chen-Yu Lee, Kyle Ziegler, Nate Yoder, そして Tomas Pfisterの貢献に対して感謝します。
3.SRRとSPADE:自己教師/半教師あり学習で完全教師あり学習を凌駕する異常検知(2/2)関連リンク
1)ai.googleblog.com
Unsupervised and semi-supervised anomaly detection with data-centric ML
2)openreview.net
Self-supervise, Refine, Repeat:Improving Unsupervised Anomaly Detection(PDF)
SPADE: Semi-supervised Anomaly Detection under Distribution Mismatch(PDF)

