
1.SRRとSPADE:自己教師/半教師あり学習で完全教師あり学習を凌駕する異常検知(1/2)まとめ
・従来の異常検知は完全にラベル付けされたデータに対して有効だが、ラベル付けは非常に手間がかかるため必ずしも現実的な設定ではない
・ラベルなしデータから1クラス分類器を構築するためにはラべルなしデータから陽性(異常)である可能性の高いサンプルを除外することが重要となる
・SRRはラベルなしデータを精緻化し、異常の可能性が高いサンプルを除外することで、ラベル精度を向上させながら、深層特徴表現を繰り返し学習する
2.SRRとは?
以下、ai.googleblog.comより「Unsupervised and semi-supervised anomaly detection with data-centric ML」の意訳です。元記事は2023年2月8日、Jinsung YoonさんとSercan O. Arikさんによる投稿です。
両手法ともアンサンブルを使って異常を検出するというアイディアがあったま良くて、やっぱり、アンサンブルって重要なんだな、という思いと、更にSPADEは教師有り設定を凌駕しており、機械学習はラベル付け作業という新しい職を生み出している的な言説を小一時間問い詰めたい気持ちになりました。
アイキャッチ画像は、Waifu Diffusion 1.5 Betaのカスタムモデルによる生成で、見ての通り教師のイラスト。
正常なデータから異常を区別するタスクである異常検出(AD:Anomaly Detection)は、製造業における視覚センサーを使った不良品の検出、金融取引における不正行為、またはネットワークセキュリティの脅威検出など、多くの実世界のアプリケーションで重要な役割を担っています。
データの種類(陰性(正常) vs 陽性(異常)、negative(normal) vs positive(anomalous))や可用性(ラベルの有無)によって、ADタスクにはさまざまな課題があります。
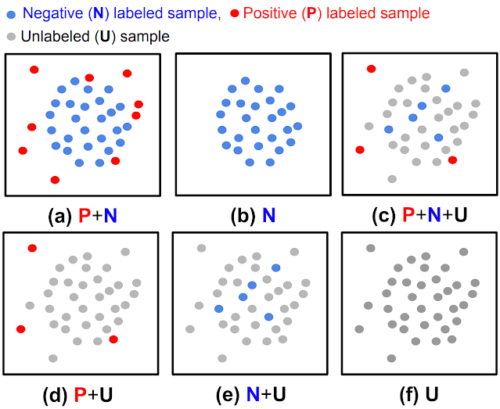
(a)完全教師あり型異常検出、(b)通常型異常検出、(c, d, e)半教師あり型異常検出、(f)教師なし型異常検出
これまでの研究では、完全にラベル付けされたデータ(上図(a)または(b))に対して有効であることが示されていましたが、実際にはラベルの入手は非常に面倒なため、このような設定はあまり一般的ではありません。
多くの場合、ユーザが使えるラベルの予算は限られており、学習時にラベル付きサンプルがないこともあります。さらに、ラベル付きデータがあったとしても、ラベルの付け方に偏りがあり、分布に違いが生じる可能性があります。このような実世界のデータの課題は、異常の検出における先行手法の達成可能な精度を制限しています。
本記事では、Transactions on Machine Learning Research(TMLR)に掲載されたADに関する私達の最近の論文のうち、教師なしおよび半教師ありの設定で上記の課題に対処した2つの論文を取り上げます。
データ中心アプローチを用いて、両者で最先端の結果を示しています。「Self-supervised, Refine, Repeat: Improving Unsupervised Anomaly Detection」では、ラベルを用いない自己教師あり学習と1クラス分類器(OCC:One-Class Classifier)出力の一致に基づく反復的データ洗練の原理に依拠した、新しい教師なしADフレームワークを提案します。
「SPADE: Semi-supervised Anomaly Detection under Distribution Mismatch」では、ラベル付きサンプルが少なく、分布の不一致がある場合でも、堅牢な性能を実現する新しい半教師付きADフレームワークを提案します。
SRRによる教師なし異常検出:自己教師で、精緻化し、繰り返す
1クラス(正常)分布の決定境界を発見すること(すなわちOCC学習)は、ラベル付けされていない学習データが2クラス(正常と異常)を含むため、完全教師なし環境では困難です。
この課題は、ラベル付けされていないデータの異常比率が高くなるにつれて、さらに悪化します。ラベルなしデータからOCCを構築するためには、ラベルなしデータから陽性(異常)である可能性の高いサンプルを除外することが重要であり、このプロセスはデータの精緻化(data refinement)と呼ばれます。精緻化されたデータは、異常比率が低く、優れた異常検知モデルが得られることが示されている。
SRRでは、まずラベルのないデータを精緻化します。そして、異常の可能性が高いサンプルを除外することで、未ラベルデータの精緻化度を向上させながら、精緻化されたデータを用いて深層特徴表現を繰り返し学習します。
この精緻化の際、OCCはラベル無し訓練データの不連続な部分集合を使って訓練されたアンサンブルを使用します。もし、アンサンブル内のすべてのOCCが一致した場合、陰性(正常)と予測され、データは精緻化データに含まれます。最後に、精緻化された訓練データは、異常予測を生成するための最終的なOCCを訓練するために使用されます。
SRRの学習
データ精緻モジュール(OCCsアンサンブル)、特徴表現学習器、および最後にOCCを用います。
(緑/赤の点はそれぞれ正常/異常のサンプルを表します)
SRRの結果
意味的な異常検出(CIFAR-10, Dog-vs-Cat)、実世界の製造業の視覚的異常検出(MVTec)、医療(Thyroid)またはネットワークセキュリティ(KDD 1999)の異常検出などの実世界の表解析ベンチマークなど、異なるドメインの様々なデータセットで広範囲な実験を実施しました。浅いモデル(例えばOC-SVM)と深いモデル(例えばGOAD、CutPaste)の両方の手法を検討します。実世界のデータの異常比率は様々であるため、ラベルのない学習データの異常比率を変えてモデルを評価し、SRRがADの性能を大きく向上させることを示します。
例えば、CIFAR-10において、SRRは10%の異常比率で、最先端の1クラスディープモデルと比較して15.0以上の平均精度(AP:Average Precision)を向上させることができました。
同様に、MVTecでは、従来の最適なOCCはAUCが6.0以上低下する一方で、SRRは10%の異常率でAUCが1.0未満となり、堅実な性能を維持しています。最後に、Thyroid(表形式データ)の異常比率2.5%の設定において、SRRは最新の1クラス分類器を22.9 F1スコアで上回りました。
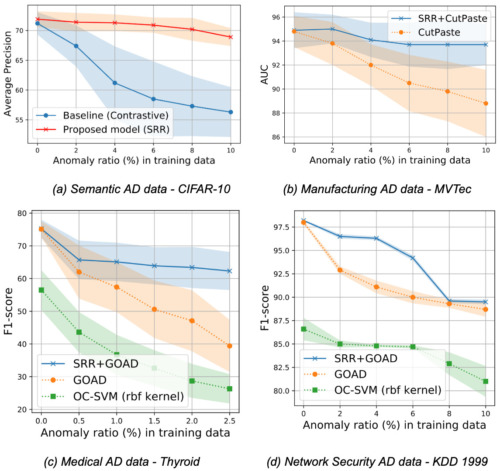
様々な領域において、SRR(青線)は完全教師なし設定において、様々な異常比率で異常検知性能を大幅に向上させます。
3.SRRとSPADE:自己教師/半教師あり学習で完全教師あり学習を凌駕する異常検知(1/2)関連リンク
1)ai.googleblog.com
Unsupervised and semi-supervised anomaly detection with data-centric ML
2)openreview.net
Self-supervise, Refine, Repeat:Improving Unsupervised Anomaly Detection(PDF)
SPADE: Semi-supervised Anomaly Detection under Distribution Mismatch(PDF)

