
1.2022年のGoogleのAI研究の成果と今後の展望~ディープラーニング用モデルの効率を向上させるアルゴリズム編~(3/3)まとめ
・大規模モデルは高い性能だが製品展開する上で法外に高いコストがかかる可能性があるためサービス効率を向上させる戦略が必要
・「蒸留」は巨大な教師モデルを使って生徒モデルを学習させる効果的な手段であり、推論コストを大きく削減する事が出来る
・「適応型計算」は簡単なサンプルはさっと推論し、難しいサンプルの際にモデルの全能力を使用する事で計算量を減らす手法
2.蒸留と適応型計算
以下、ai.googleblog.comより「Google Research, 2022 & beyond: Algorithms for efficient deep learning」の意訳です。元記事は2023年2月7日、Sanjiv Kumarさんによる投稿です。
蒸留の話は昨年、ai.googleblog.com内ではほとんど出てきてなかった気がします。
アイキャッチ画像は、Waifu Diffusion 1.5 Betaのカスタムモデルによる生成
効率的な推論
ニューラルネットワークのサイズを大きくすることは、その予測精度を向上させる上で驚くほど効果的であることが証明されています。しかし、大規模なモデルの推論コストは、製品展開する上で法外に高い可能性があるため、実世界でこの利点を実現するのは困難です。
このため、精度を犠牲にすることなく、サービス効率を向上させるための戦略が動機づけられています。2022年、私達はこれを実現するための様々な戦略、特に「知識蒸留(knowledge distillation)」と「適応型計算(adaptive computation)」に基づく戦略を研究しました。
蒸留(Distillation)
蒸留は、シンプルかつ効果的なモデル圧縮手法であり、大規模なニューラルモデルの潜在的な適用可能性を大幅に拡大することができます。蒸留は、お勧め広告などの実用的なアプリケーションで広く有効であることが証明されています。蒸留法のほとんどの使用例では、基本的なレシピを与えられた領域に直接適用しています。しかし、どんな時に、なぜ、それがうまくいくはずなのかについては、限定的な理解に留まっています。今年の私達の研究は、蒸留を特定の設定に合わせることと、蒸留の成功を支配する要因を正式に研究することです。
アルゴリズムの面では、教師ラベルのノイズを注意深くモデル化することで、学習サンプルを再重み化する原理的なアプローチと、教師ラベルを持つデータの部分集合をサンプリングする堅牢な方法を開発しました。
「Teacher Guided Training」では、新しい蒸留のフレームワークを提示しました。固定されたデータセットに教師が注釈付けを行うという受動的な使い方ではありません。注釈を付けるべき有益なサンプルの選択するために、積極的に教師を利用します。これにより、蒸留プロセスは限られたデータやロングテール設定において輝きを放ちます。
また、クロスエンコーダ(例:BERT)から因数分解してデュアルエンコーダに蒸留するための新しいレシピを研究しました。これは、[query, document]のペアの関連性をスコアリングするタスクにとって重要な設定です。
私達は、クロスエンコーダーとデュアルエンコーダー間の性能差の理由を研究し、これはデュアルエンコーダーのモデル容量制限ではなく、汎化の結果である可能性がある事に注目しました。蒸留のための損失関数を慎重に構築することで、これを緩和し、クロスエンコーダーとデュアルエンコーダーの性能差を小さくすることができます。
その後、EmbedDistillでは、教師モデルからのembeddingsをマッチングさせることで、デュアルエンコーダの蒸留をさらに改善することを検討しました。この戦略は、大規模なデュアルエンコーダモデルから小規模なデュアルエンコーダモデルへの蒸留にも用いることができ、その場合、教師モデルの文書embeddingsを継承して凍結することが非常に効果的であることが証明されています。
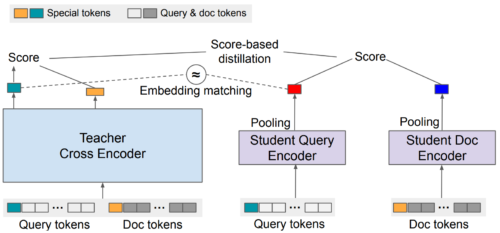
EmbedDistillでは、教師から生徒への蒸留は、最終的な予測値の一致に加えて、生徒のembeddingsの形状を教師のembeddingsと一致させる新しい損失関数を設計することによって行われます。
理論面では「生徒が教師のラベルをどれだけうまく予測できるか?」を示す教師複雑度(supervision complexity)のレンズを通して、蒸留に新しい視点を提供しました。
これは、ニューラルタンジェントカーネル(NTK:Neural Tangent Kernel)理論に基づき、能力差が蒸留に影響を与える可能性があること、例えば、能力差が非常に大きい教師が作ったラベルは生徒にとって純粋なランダムラベルと同じように見える可能性があることなど、概念的な洞察を提供します。
さらに、蒸留により、教師モデルが「難しい」と判断したサンプルを生徒が学習しきれない(underfit)可能性があることを示しました。直感的には、これは生徒が限られた能力を合理的にモデル化できるサンプルに集中させるのに役立つと思われます。
適応型計算(adaptive computation)
蒸留は推論コストを削減する効果的な手段ですが、それは全てのサンプルに対して一律に行われます。しかし、直感的には、いくつかの「簡単な」サンプルは、「難しい」サンプルよりも本質的に少ない計算を必要とするかもしれません。適応型計算の目標は、このようなサンプルに依存した計算を可能にする機構を設計することです。
「Confident Adaptive Language Modeling(CALM)」は、T5などのTransformerベースのテキスト生成器に早期終了機能を導入して制御します。この適応型計算では、モデルはデコーディングステップごとに使用するTransformerレイヤーの数を動的に変更します。
早期終了ゲートは、統計的性能保証を満たすように等級付けされた決定閾値を持つ信頼度指標を使用します。この方法では、最も困難な予測に対してのみ、デコーダ差イヤーの全スタックを計算する必要があります。簡単な予測であれば、数個のデコーダレイヤを計算するだけで済みます。実際、このモデルは平均して約3分の1のレイヤーを予測に使用し、同じレベルの生成品質を維持しながら2~3倍のスピードアップを実現しています。
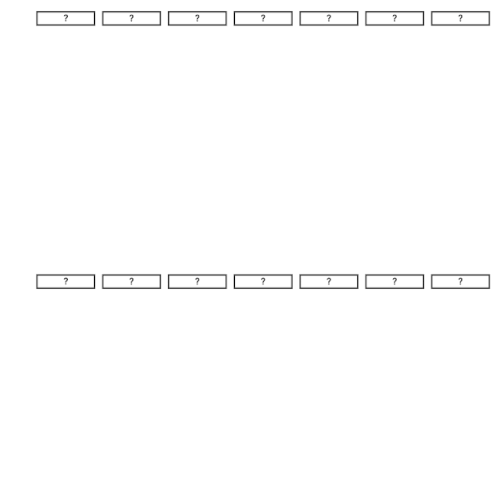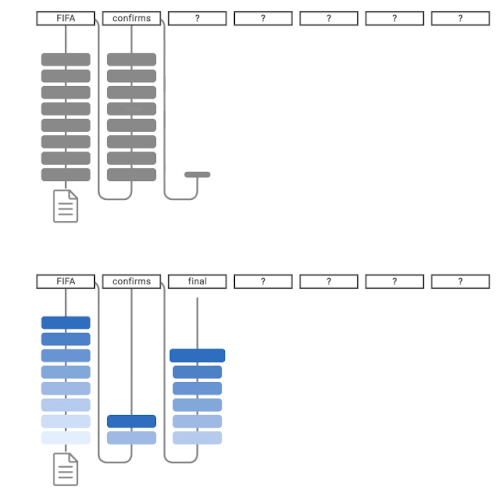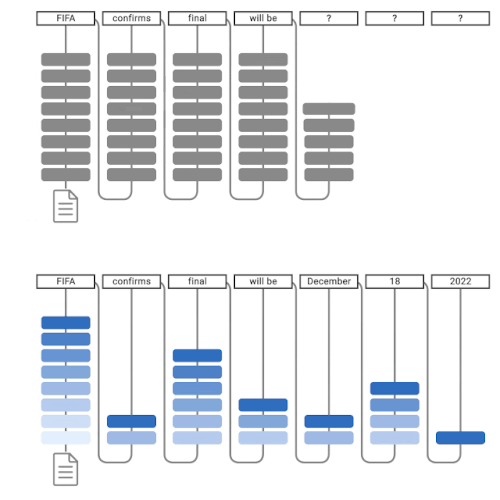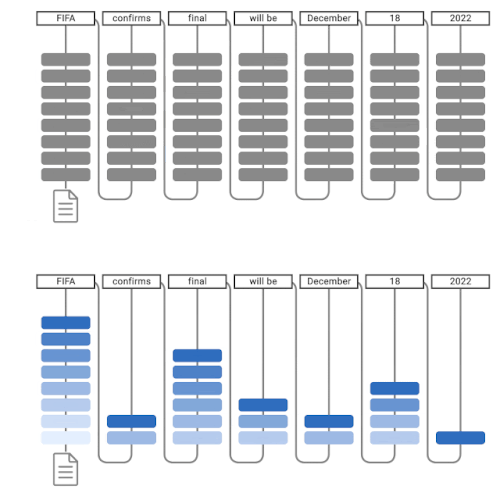
通常の言語モデルによるテキスト生成(上)、CALMによるテキスト生成(下)
CALMは早期の予測を試みます。十分な自信がある場合(濃い青色)には、予測をスキップして時間を節約します。
汎用的な適応型計算の仕組みとして、2つ以上のベースモデルをカスケード(cascade)、つまり連ねる手法があります。カスケードを使用する際の重要な問題は、現在のモデルの予測を単純に使用するか、下流のモデルに予測を委ねるかを決定することです。
予測を延期するタイミングを学習するためには、延期を決定するための教師として適切な信号を活用することができる適切な損失関数を設計する必要があります。
私達はこの目的のために既存の損失関数を正式に研究しました。その結果、ラベルスムージングを暗黙のうちに適用しているため、学習サンプルに適合しない場合があることを示しました。
私達は、遅延ルールのポストホック学習により、この問題を軽減できることを示しました。この手法は、モデル内部を一切修正する必要がありません。
検索用途の標準的な意味検索技術では、大規模モデルによって生成された各embeddingsに対して固定的な表現を用います。つまり、下流のタスクやそれに関連する計算環境、制約に関係なく、特徴表現のサイズや能力はほぼ固定されています。
マトリョーシカ特徴表現学習(MRL:Matryoshka Representation Learning)は、展開環境に応じて特徴表現を適応させる柔軟性を導入します。つまり、リソースに制約のある環境では、特徴表現の上位数点の座標のみを使用し、より豊かで精度が要求される環境では、より多くの座標を使用できるように、特徴表現の座標内に自然な順序を持たせるのです。
ScaNNのような標準的な近似最近傍探索技術と組み合わせることで、MRLは同じ再現率と精度指標で最大16倍低い計算量を実現することができます。
まとめ
大規模MLモデルは、いくつかの領域で革新的な成果を上げていますが、これらのモデルを実世界で実用化するためには、学習と推論の両方における効率化が重要なニーズとして浮上しています。
Google Researchは、新しい基礎技術を開発することで、大規模MLモデルの効率化に多大な投資を行ってきました。これは継続的な取り組みであり、今後数ヶ月の間、MLモデルをさらに堅牢かつ効率的にするための中核的な課題を探求していきます。
謝辞
効率的なディープラーニングの研究は、Google Researchの多くの研究者の協力のもとで行われました。
以下の研究者が含まれます。including Amr Ahmed, Ehsan Amid, Rohan Anil, Mohammad Hossein Bateni, Gantavya Bhatt, Srinadh Bhojanapalli, Zhifeng Chen, Felix Chern, Gui Citovsky, Andrew Dai, Andy Davis, Zihao Deng, Giulia DeSalvo, Nan Du, Avi Dubey, Matthew Fahrbach, Ruiqi Guo, Blake Hechtman, Yanping Huang, Prateek Jain, Wittawat Jitkrittum, Seungyeon Kim, Ravi Kumar, Aditya Kusupati, James Laudon, Quoc Le, Daliang Li, Zonglin Li, Lovish Madaan, David Majnemer, Aditya Menon, Don Metzler, Vahab Mirrokni, Vaishnavh Nagarajan, Harikrishna Narasimhan, Rina Panigrahy, Srikumar Ramalingam, Ankit Singh Rawat, Sashank Reddi, Aniket Rege, Afshin Rostamizadeh, Tal Schuster, Si Si, Apurv Suman, Phil Sun, Erik Vee, Ke Ye, Chong You, Felix Yu, Manzil Zaheer, 及び Yanqi Zhou。
1.2022年のGoogleのAI研究の成果と今後の展望~ディープラーニング用モデルの効率を向上させるアルゴリズム編~(3/3)関連リンク
1)ai.googleblog.com
Google Research, 2022 & beyond: Algorithms for efficient deep learning
2)arxiv.org
On the Factory Floor: ML Engineering for Industrial-Scale Ads Recommendation Models
Teacher Guided Training: An Efficient Framework for Knowledge Transfer
EmbedDistill: A Geometric Knowledge Distillation for Information Retrieval
Neural Tangent Kernel: Convergence and Generalization in Neural Networks
3)openreview.net
Matryoshka Representation Learning(PDF)

