
1.Flan Collection:指示調整用のデータセットを更に充実(2/2)まとめ
・Flan 2022を使って微調整したFlan-T5モデルは他の先行研究を上回る強力な汎用NLP推論器を実現できる事を示した
・単一タスクに特化した微調整を行ったT5よりFlanで微調整したT5の方が高いスコアを出す事もあり、収束も早かった
・Flan-T5のような指示調整モデルを使う事で従来の非指示型調整モデルよりも総合的に見た効率を高める事ができる
2.Flan Collectionの利点
以下、ai.googleblog.comより「Learning with queried hints」の意訳です。元記事は2023年2月1日、Shayne LongpreさんとAdam Robertsさんによる投稿です。
アイキャッチ画像はstable diffusionを自分でカスタムマイズしたモデルで生成したイラスト
指示調整手法の評価
ある指示調整コレクションを別のものに置き換えたときの全体的な効果を理解するために、Flan 2021、T0++、Super-Natural Instructionsなどの人気の高い指示調整コレクションを使って、同じサイズのT5モデルの微調整を行いました。
次に、各モデルを、各指示調整コレクションに既に含まれているタスクのセット、5つの思考の連鎖タスクのセット、そしてMMLUベンチマークから57の多様なタスクのセットで、ゼロショットと少数回ショットのプロンプトを使用して評価しました。いずれの場合も、新しいFlan 2022を使ったFlan-T5モデルは他の先行研究を上回り、より強力な汎用NLP推論器である事を実証しています。
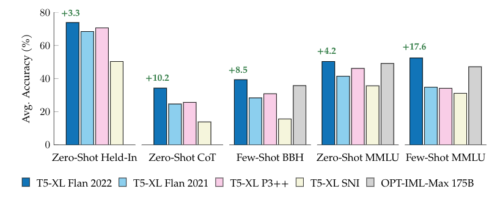
BigBench HardやMMLUなどのhold-in, chain-of-thought, hold-out評価スイートでの公開指示調整チューニングコレクションの比較。OPT-IML-Max(175B)以外のモデルは、30億パラメータを持つT5-XLを使用し、Google社内で学習させたものです。緑色の文字は、T5-XL(30億)の次善のモデルに対する改善度を示しています。
単一タスクに特化した微調整との比較
自然言語処理のアプリケーションでは、学習データが既に存在する単一のタスクに特化させた微調整モデルを使う事が良くあります。
そこで、私達はFlan-T5とT5モデルの比較を行うことを出発点として、3つの設定で比較します。
具体的には、ターゲットタスクに特化した微調整を行ったT5、ターゲットタスクに特化した微調整を行っていないFlan-T5、ターゲットタスクに特化した微調整を行ったFlan-T5です。
held-in、held-outのいずれのタスクにおいても、Flan-T5を微調整した方が、T5を微調整した場合よりも改善されることがわかりました。また、学習データが少ない場合、微調整を行っていないFlan-T5が微調整を行ったT5を上回る場合がありました。
Flan-T5は単一タスク用に微調整を行ったT5を上回りました。単一タスク用の微調整を行ったT5(青棒)、単一タスク用に微調整を行ったFlan-T5(赤)、さらに微調整を行わなかったFlan-T5(ベージュ)を比較
Flan-T5を出発点とした場合の利点は、学習が大幅に高速かつ安価であること、T5の微調整よりも収束が早く、通常、より高い精度でピークに達することです。このことは、特定のタスクでFlan-T5でT5同等以上の結果を得るためには、より少ないタスク固有の学習データで済む可能性を示唆しています。
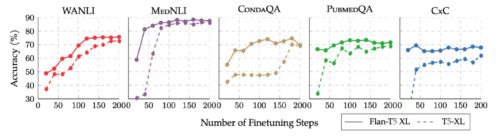
Flan-T5は単一タスクの微調整においてT5より早く収束します。
上図はFlanの微調整中には使われなかったデータを使った5つのタスクについての図です。Flan-T5の学習曲線は実線で、T5の学習曲線は破線で示されています。
自然言語処理分野では、Flan-T5のような指示調整モデルを単一タスクの微調整に用いることで、従来の非指示型調整モデル(non-instruction-tuned models)よりも大きなエネルギー効率を得ることができます。
事前学習と指示微調整は金銭的にも計算機資源的にも高価ですが、それは1回限りのコストであり、通常はその後の数百万回の微調整の実行で償却され、最も著名なモデルの場合、総計でより高価になる可能性があります。指示調整を施したモデルは、同等以上の性能を達成するために必要な微調整のステップ数を大幅に減らすという点で、有望な解決策となります。
まとめ
新しいFlan指示調整コレクションは、最も人気のある先行公開コレクションとその手法を統合し、新しいひな形と混合プロンプト設定におけるトレーニングに簡単な改良を加えました。
その結果、Hold-in、Chain of Think、MMLU、BBHのベンチマークにおいて、ゼロショットと少数回ショットのバリエーションで、Flan、P3、Super-Natural Instructionsを3~17%上回る性能が得られました。この結果は、この新しいコレクションが、新しい指示の一般化または単一の新しいタスクでの微調整に興味を持つ研究者や実務家にとって、より高性能な出発点として機能することを示唆しています。
謝辞
Jason Wei, Barret Zoph, Le Hou, Hyung Won Chung, Tu Vu, Albert Webson, Denny Zhou, Quoc V Leと本プロジェクトで協働できたことを光栄に思います。
3.Flan Collection:指示調整用のデータセットを更に充実(2/2)関連リンク
1)ai.googleblog.com
The Flan Collection: Advancing open source methods for instruction tuning
2)arxiv.org
The Flan Collection: Designing Data and Methods for Effective Instruction Tuning
3)github.com
google-research / FLAN

