
1.Open Images V7:新たに疎らなラベルであるポイントラベルを採用(1/2)まとめ
・Open Imagesは約900万枚の画像に様々なラベルを付与した大規模データセット
・この度、ポイントレベルラベルという新しい疎らな注釈を追加したV7が公開
・対象画像の特定のポイントが特定のクラスに属するかをYes/Noで表現したラベル
2.Open Images V7とは?
以下、ai.googleblog.comより「Open Images V7 — Now Featuring Point Labels」の意訳です。元記事は2022年10月25日、Rodrigo Benensonさんによる投稿です。
大規模モデルの設計では、入力データを全てのニューロンで処理するdense(密な)モデルから、入力データを属性によって振り分けて一部のニューロンのみで処理するように効率化して更なるモデルの規模拡大を目指すsparse(疎らな、まばらな)モデルにトレンドが変化してきているのを感じます。今回のお話を読むとデータセットでも同様に情報量をスパースにする代わりに量や規模のスケールアップを目指す手法がトレンドになりそうな気がします。
アイキャッチ画像はstable diffusionの1.5版の生成で円や四角をポイントで指しているトトロのはずなんですがトトロ自身が丸くなったり四角くなったり…
Open Imagesは、数千のオブジェクトカテゴリにまたがるラベルを持つ、約900万枚の画像をカバーするコンピュータビジョンデータセットです。世界中の研究者が、コンピュータビジョンモデルの訓練と評価にOpen Imagesを使用しています。
6千のカテゴリをカバーする画像レベルのラベルを含む2016年のOpen Imagesの最初のリリース以来、私達は注釈(annotations)を充実させ、データセットの潜在的な使用例を拡張するために複数のアップデートを提供してきました。
数回のリリースを通じて、すべての画像に画像レベルの2万以上のカテゴリーラベルを追加し、190万画像のサブセットには境界ボックス、視覚関係(visual relations)、インスタンスセグメンテーション、localized narratives(同期音声、マウストレース、テキストキャプション)を追加しました。
Open Images V7は、ポイントレベルラベル(point-level labels)という新しい注釈タイプによりOpen Imagesデータセットをさらに拡張し、利用可能な豊富なデータをよりよく探索できる、新しいオールインワン可視化ツールを含んでいます。
ポイントラベル
新しいポイントレベルラベルを収集するための主な戦略は、機械学習モデルからの質問を人間が検証する事です。
まず、MLモデルが注目すべき点を選択し「この点はカボチャの上ですか?」といったYES/NOで答えられる質問をします。次に、人間の注釈作業担当者が平均1.1秒かけてYES/NOの質問に回答しました。そして、同じ質問に対する異なる注釈者の回答を集約し、最終的に「はい」「いいえ」「わからない」のラベルを注釈された各点に割り当てました。

注釈作業の図
(画像:Lenore Edman、CC BY 2.0ライセンスに基づく)
各注釈対象画像に対して、お題となるクラスであるのか、ないのかを「はい」また「いいえ」のラベルで表現するポイントの集まりを提供します。これらのポイントは、セマンティックセグメンテーションタスクに使用できる疎な情報を提供します。私達は、5800クラスと1400万画像をカバーする合計3860万の新しいポイント注釈(「はい」のラベルを持つ1240万の注釈)を収集しました。
このように、ポイントラベルに着目することで、注釈の対象となる画像やカテゴリを拡大することができました。また、注釈作業担当者は、有用な情報を効率的に収集することに注力しました。この結果、従来のセグメンテーションと比較して、16倍以上のクラスと画像をカバーすることができました。
また、境界ボックス形式の注釈と比較して、9倍以上のクラスをカバーすることができました。PASCAL VOC、COCO、Cityscapes、LVIS、ADE20Kなどの既存のセグメンテーションデータセットと比較して、より多くのクラスとより多くの画像をカバーする注釈を提供することができました。
この新しいポイントラベル注釈は、モノ(車、猫、双胴船などの数えられる物体、things)とコト(草、花崗岩、砂利などの数えられない物体、stuff)の両方の位置情報を提供するOpen Imagesで初めてのタイプの注釈となります。今回収集されたデータは、人間作業者のおよそ2年分の注釈に相当します。
このような疎なデータは、セグメンテーションモデルの学習と評価の両方に適していることが、私達の初期実験で示されました。疎なデータに対して直接モデルを学習することで、密な注釈に対する学習と同等の品質に到達することができます。
同様に、従来のセマンティックセグメンテーションのIntersection-over-union(IoU)指標を疎らなデータ上で直接計算できることを示します。異なる手法間の順位は維持され、疎なIoU値はその密な版の正確な推定値になります。詳しくは論文をご覧ください。
以下、4つの画像例とそのポイントレベルのラベルを示し、これらの注釈が提供する豊富で多様な情報を説明します。丸印⭘は「はい」ラベル、四角印☐は「いいえ」ラベルです。
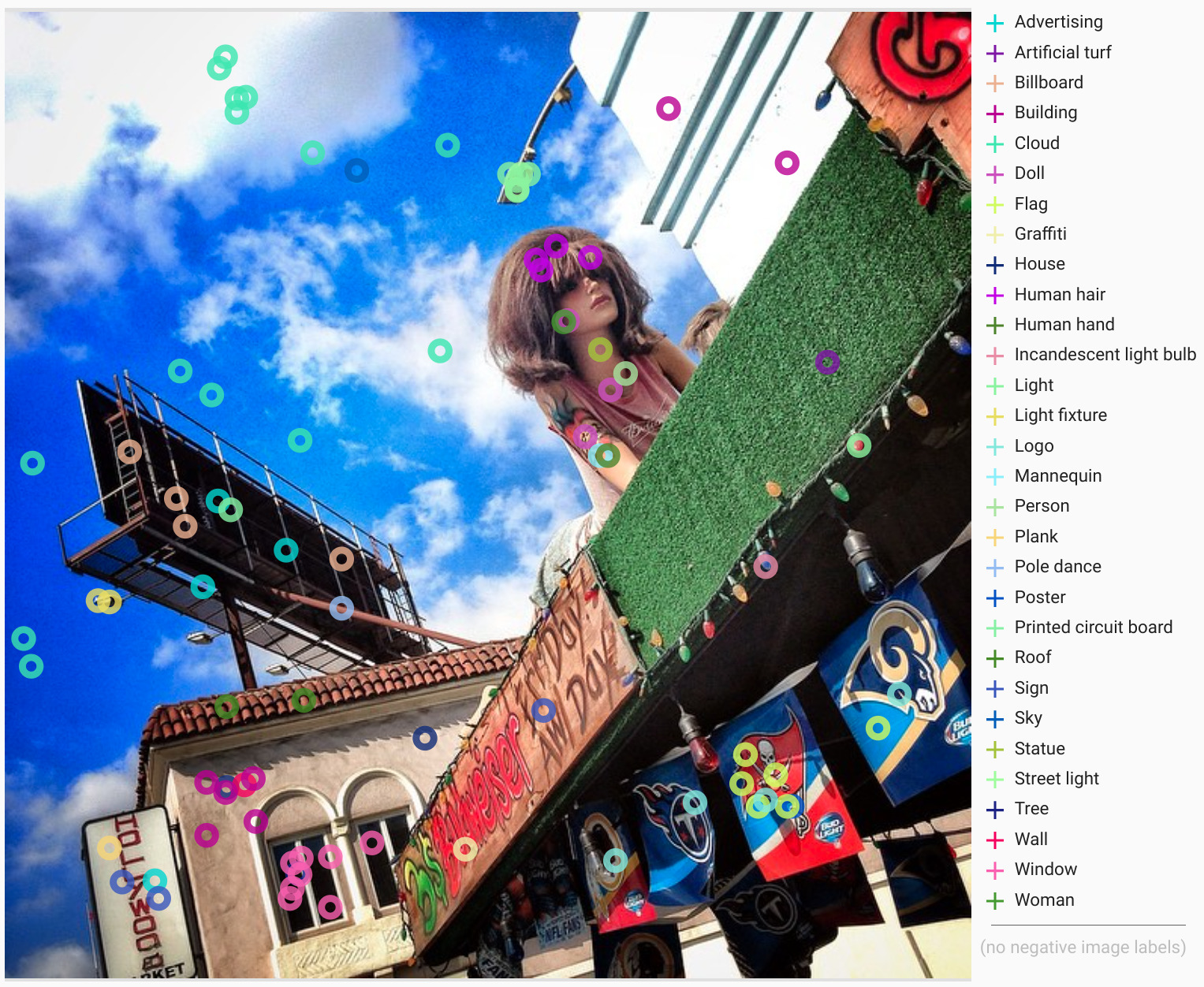

ポイントレベルのラベルを付けた4つの画像例
画像:Richie Diesterheft, John AM Nueva, Sarah Ackerman, 及びC Thomas, 全てCC BY 2.0 licenseの元で引用しています。
3.Open Images V7:新たに疎らなラベルであるポイントラベルを採用(1/2)関連リンク
1)ai.googleblog.com
Open Images V7 — Now Featuring Point Labels
2)storage.googleapis.com
From colouring-in to pointillism:revisiting semantic segmentation supervision(PDF)
Open Images Dataset V7 and Extensions

