
1.弱いヒントを使って多腕バンディット問題を改善(1/2)まとめ
・カジノに設置されているレバーが一本付いているスロットマシンを「one‐armed bandit(隻腕の悪党)」と呼称する
・レバーが複数ついているスロットマシンでどのレバーを引くのが一番後悔が少なくなるかを探るのが多腕バンディット問題
・従来は最悪のケースに対する最適化に重点を置いており、実世界に利用可能データがあっても考慮していなかった
2.多腕バンディット問題の難しさ
以下、ai.googleblog.comより「Learning with queried hints」の意訳です。元記事は2023年1月25日、Sreenivas GollapudiさんとKostas Kolliasさんによる投稿です。
多腕バンディット問題(multi-armed bandit problem)とは最適化理論関連で良く出てくる名称で、banditが直訳すると山賊や無法者なので「沢山の腕を持つ山賊の問題」であり、意味がさっぱりわかりません。
しかし、実は、カジノなどによくあるレバーが一本付いているスロットマシンを(おそらくお金をむしり取られるので)「one‐armed bandit(隻腕の悪党)」と呼称する習わしに由来していて「レバーが複数ついているスロットマシンがあるとしたらどのレバーを引くのが一番後悔が少なくなるか?」というのが多腕バンディット問題(multi-armed bandit problem)です。
弱いヒントとは、Q「猫と犬はどうやって見分けますか?」A「にゃーって鳴くのが猫です」的な厳密ではないけれども、大勢を判別するには十分な、ゆるい情報の事で、弱い教師(Weak Supervision)のアイディアから来ているものと思います。
アイキャッチ画像はstable diffusionを自分でカスタムマイズしたモデルによる生成で、AIだったら意図せずとも多腕になってしまう事はあるので多腕の山賊は描ける!と思ったら、意図的に多腕にした綺麗な絵は、それはそれで難しい事がわかって綺麗さを優先したイラスト
多くのコンピュータアプリケーションでは、オンライン方式で到着したリクエストに対応するために、システムが決定を下す必要があります。
例えば、運転者の要望に応えるカーナビの例を考えてみましょう。
このような環境では、問題の重要な側面について本質的な不確実性が存在します。例えば、経路の特徴に関するドライバーの好みは未知であることが多く、経路内の渋滞情報も不確かである可能性があります。オンライン機械学習の分野では、このような設定を研究し、不確実性の下での意思決定問題に対する様々な技術を提供しています。
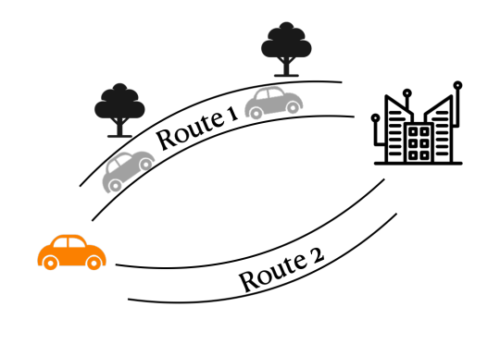
ナビゲーションアプリは、ユーザーの要求をどのような経路に決定するかを決定しなければなりません。ユーザの満足度は、2つの経路の(不確かな)渋滞度と、経路がいかに景色が良いか、安全か、などの様々な経路の特徴に関するユーザの未知の嗜好に依存します。
この枠組みで非常によく知られている問題は多腕バンディット問題(multi-armed bandit problem)です。
システムはn個の利用可能な選択肢(arm)の集合を持ち、各回(各ユーザ要求)時にその中から選択するよう求められます。例えば、カーナビでは事前に計算された代替経路の集合から選択します。
ユーザーの満足度は、ユーザーの好みや経路の一部の渋滞などの未知の要素に依存する報酬によって測定されます。T回にわたるアルゴリズムの性能は、後悔によって、後知恵で最良の行動と比較されます。(つまり、最良の選択をした際の腕の全報酬と、アルゴリズムがT回実行後に実際に得た報酬との差)
多腕バンディット問題の専門家版では、アルゴリズムの実行後だけでなく、各回の後にすべての報酬が観察されます。
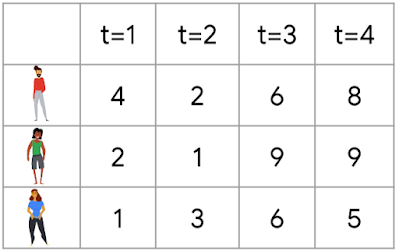
専門家問題の一例
表は、各回 = 1, 2, 3, 4 において、3人の専門家に従った場合に得られる報酬を示しています。後から見て一番良い専門家(つまり比較の基準となる専門家)は真ん中の専門家で、総報酬は21です。例えば、最初の2回で専門家1を選択し、最後の2回で専門家3を選択したとすると(各回の報酬を観察する前に選択する必要があることを思い出してください)、報酬17を得る事になり、後悔は21 – 17 = 4に等しくなってしまいます。
このような問題は広く研究されており、既存のアルゴリズムでは劣線形(sublinear)の後悔を達成することができます。例えば、多腕バンディット問題では、既存の最良のアルゴリズムは、√Tのオーダーの後悔を達成することができます。
しかし、これらのアルゴリズムは最悪のケースに対する最適化に重点を置いており、実世界の豊富な利用可能データを考慮に入れてはいません。データがあれば、このような問題を解決するために、アルゴリズム設計を支援する機械学習モデルを訓練することが可能です。
論文「Online Learning and Bandits with Queried Hints」(ITCS 2023にて発表)では、弱いヒントを与えてくれるMLモデルが、バンディット的な設定においてアルゴリズムの性能を大幅に向上させる方法を示します。
多くのMLモデルは、関連する過去のデータを用いて正確に学習されます。例えば経路探索のアプリケーションでは、特定の過去データを用いて道路の一部に発生する遅延を推定し、運転者から得た過去のフィードバックを用いて特定の経路の品質を学習することができます。
このようなデータを用いて学習したモデルは、場合によっては非常に正確なフィードバックを与えることができます。しかし、私達のアルゴリズムは、モデルからのフィードバックがあまり明確でない弱いヒントの形であっても、強い保証を実現します。
3.弱いヒントを使って多腕バンディット問題を改善(1/2)関連リンク
1)ai.googleblog.com
Learning with queried hints
2)arxiv.org
Online Learning and Bandits with Queried Hints

