
1.イラスト生成AIのStable DiffusionはどのGPUで実行するのが最速か?まとめ
・StableDiffusionでイラストを生成する際の実行時間をNvidia、AMD、IntelのGPUで比較した結果
・NvidiaのGPUの性能はやはり高いがライブラリの最適化次第で状況はかなり変わる可能性がある
・やりたい事とそのために必要なメモリ量、予算との兼ね合いを考えてGPUを選択していく事が大事
2.NVIDIAとAMDとINTELのAI実行時のGPU性能比較
以下、老舗のハードウェア評価サイトであるtomshardwareより「Stable Diffusion Benchmarked: Which GPU Runs AI Fastest (Updated)」の意訳です。元記事は2023年1月26日、 Jarred Waltonさんによる投稿です。
元記事内にも注記されてますが、私が読んで注意点と思ったのは以下です。
・実行環境やソフトウェアのチューニングの度合がかなり違う
→今後のソフトウェアアップデートで状況がガラリと変わる可能性がある
・解像度512で大量の画像を生成する使い方は実践的ではないかもしれない
→そして解像度を上げたり、モデルの微調整を始めると搭載メモリ量が問題になってくる
お値段や使用OSの差もありますので、その人の使い方次第で評価はガラリと変わってしまうと思います。
なお、「Stable Diffusionを動かすパソコンを選ぶ際の基礎知識」でも書きましたが、私はRTX 3060 12GBを使っています。そして、モデルの微調整なども頻繁に行う私の使い方だと「もう少しGPUメモリがあったらなぁ」と感じる事はあるのですが「もっと早いGPUが欲しいなぁ」と感じる事はあまりない(もちろん、早い方が良いのは当然ですが価格も跳ね上がる)ので、今のところは、重要なのはメモリ搭載量とセットアップ/トラブル解決の容易さと思っています。
とはいえ、GPUのベンチマークと言えばゲームや配信前提の比較が多く、AI実行環境の観点から比較してくれたデータ且つAMD、Intelまで含めた数値はあまり見たことがないので、StableDiffusion以外の汎用的な人工知能学習用途のハードウェア選択の際にも参考にできる貴重な比較資料で力作と思います。
更に余談ですが、データセンター向けのNVIDIAの新世代GPU H100(約500万円弱)だとStable Diffusionがほぼリアルタイムで動画のようにイラスト生成できるようになるらしいです。しかし、現世代のNVIDIA A100(約200万円強)でも、安いクラウド/Cola pro+でも1時間単価130円くらいなので、H100は円安考えると500円/h近くになると推測されるので(2023年10月追記:現在、GPUの価格が高騰しており比較的安価なクラウドでもH100は$4.50、一ドル150円換算では675円です)、当面は気軽に使える価格帯にはならなさそうです。
やはり市場占有後に好き放題に価格上げていく作戦を取られると消費者の立場だと辛いですね。AMD、Intelには頑張って欲しいところです。
アイキャッチ画像はstable diffusionのカスタムモデルによる生成で、よくあるハードウェアのサイバーパンク風なパッケージを意識して生成したイラスト
ChatGPTによる貧弱なアドバイスの生成、自動運転車、AIを使っていると非難されるアーティスト、AIによる医療アドバイスなど、人工知能と深層学習は、最近、常にニュースの見出しを飾っています。これらのツールのほとんどは、学習時は多くのハードウェアを備えた複雑なサーバーが必要になりますが、学習したネットワークを使用して推論を実行することは、グラフィックカード上のGPU(Graphics Processing Unit)を使用して、パーソナルコンピューター上で行うことができます。しかし、消費者向けGPUは、AIの推論を行うのに、どの程度の速度が必要なのでしょうか?
最新のNvidia、AMD、そしてIntel GPUで、人気のAI画像作成ソフト「Stable Diffusion」をベンチマークし、その実力を検証してみました。もし、あなたが自分のPCでStable Diffusionを動かそうとしたことがあるなら、それがどれほど複雑で、あるいは単純なことなのか、なんとなくわかるかもしれません。
簡単にまとめると、NvidiaのGPUは、ほとんどのソフトウェアがCUDAやその他のNvidiaのツールセットを使用して設計されているので、根本を支配しているということです。しかし、だからといって、他社のGPUでStable Diffusionを動作させることができないわけではありません。
私たちは、最終的に3つの異なるStable Diffusionプロジェクトをテストに使用しました。これは、1つのパッケージがすべてのGPUで動作するわけではないからです。Nvidiaでは、Automatic 1111のwebuiバージョンを選択しました。AMD GPUはNod.aiのSharkバージョンでテストしました。
Nvidia GPU(VulkanとCUDAモードの両方)のパフォーマンスをチェックしたところ、…物足りなさを感じました。IntelのArc GPUを動作させるのは、サポートがないため、もう少し困難でしたが、Stable Diffusion OpenVINOは、いくつかの非常に基本的な機能を提供してくれました。
免責事項があります。
私たちは、これらのツールのいずれも自ら作成したわけではありません。Windowsで簡単に実行でき、適度に最適化されていると思われるものを探しました。Nvidia RTX 3000シリーズのテストは比較的、最適に近い性能を引き出す良い仕事をしていると確信しています。特に、xformersを有効にすると、性能がさらに20%程度向上します。(ただし、精度が落ちるのでイラストの品質に影響が出る可能性があります)。一方、RTX 4000シリーズの結果は最初は低かったのですが、George SV8ARJ氏がAutomatic 1111に修正を提供しており、その修正を適用してPyTorch CUDA DLLを交換することで性能に健全なブーストを与えました。
AMDの結果も賛否両論です。RDNA 3 GPUの性能は非常に高く、RDNA 2 GPUはどちらかといえば平凡な印象です。Nod.aiは、RDNA 2用の「チューニング」モデルをまだ開発中で、これが利用可能になれば性能はかなり(2倍になる可能性もある)向上すると伝えています。最後に、Intel GPU では、最終的な性能は AMD のオプションとほぼ同じに見えますが、実際にはレンダリングにかかる時間が大幅に長くなります。
また、ソフトウェアプロジェクトの選択により、異なるStable Diffusionモデルを使っています。Nod.aiのSharkバージョンはStable Diffusion2.1、Automatic 1111とOpenVINOはStable Diffusion1.4を使っています。(ただし、Automatic 1111ではStable Diffusion2.1を有効にすることが可能です)。
繰り返しになりますが、もしあなたがStable Diffusionの内部知識をお持ちで、私たちが使ったものよりもよく動くかもしれない別のオープンソースプロジェクトを推薦したい場合は、コメントでお知らせください。またはスタッフにメールを送るだけでもかまいません。
私たちのテスト・パラメータはすべてのGPUで同じですが、Intel版にはネガティブ・プロンプトのオプションはありません。(少なくとも、私たちは見つけることができませんでした)。
私たちが選んだ以下の設定は、3つのSDプロジェクトすべてで動作させるために選択した事に注意してください。スループットを向上させることができるいくつかのオプションは、Automatic 1111のビルドでのみ利用できますが、これについては後で説明します。以下、該当する設定です。
プロンプト
postapocalyptic steampunk city, exploration, cinematic, realistic, hyper detailed, photorealistic maximum detail, volumetric light, (((focus))), wide-angle, (((brightly lit))), (((vegetation))), lightning, vines, destruction, devastation, wartorn, ruins
ネガティブプロンプト
(((blurry))), ((foggy)), (((dark))), ((monochrome)), sun, (((depth of field)))
Steps
100
Classifier Free Guidance
15.0
Sampling Algorithm
Eulerシリーズ (Automatic 1111:Ancestral, AMD:Shark Euler Discrete)
サンプリングアルゴリズムは、出力に影響を与えることはあっても、性能に大きな影響を与えることはないようです。Automatic 1111は最も多くの選択肢を提供しますが、Intel OpenVINOビルドは何の選択もできません。
AMD RX 7000/6000シリーズ、Nvidia RTX 40/30シリーズ、Intel Arc AシリーズGPUのテスト結果は以下のとおりです。Nvidia GPUには、デフォルトの計算モデルを使用した結果(黒で表示)と、Facebookが開発しているの高速な「xformers」ライブラリを使用した結果(緑で表示)の2つがあることに注意してください。
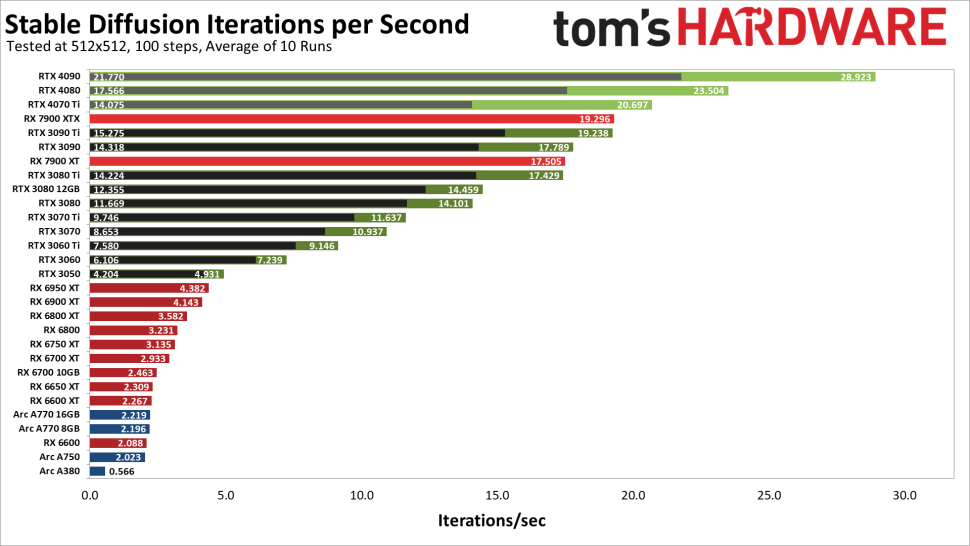
予想通り、NvidiaのGPUは、AMDやIntelのものと比べて、時には圧倒的な差をつけて優れた性能を発揮します。
TorchのDLL修正を行ったRTX 4090は、xformerを使用したRTX 3090 Tiよりも50%、xformerを使用しない場合では43%高い性能を発揮します。各画像の生成には3秒強かかり、RTX 4070 Tiでも3090 Tiを超える事ができます(ただし、xformersを無効にした場合はできません)
Nvidia GPUの最上位カードからは、3090から3050まで、かなり一貫した形で性能が落ち込んでいきます。一方、AMDのRX 7900 XTXはRTX 3090 Tiと(追加の再テスト後に)同点、RX 7900 XTはRTX 3080 Tiと同点となっています。7900カードはかなり良さそうですが、すべてのRTX 30シリーズのカードは、AMDのRX 6000シリーズのパーツに(今のところ)勝って終わっています。最後に、Intel Arc GPUはほぼ最下位で、A770だけがRX 6600を何とか上回っています。この不一致についてもう少し詳しく説明しましょう。
適切な最適化により、RX 6000シリーズのカードでは性能が倍増する可能性があります。Nod.aiによれば、近日中にRDNA 2用のモデルをチューニングする予定であり、その時点で全体の立ち位置が理論上の性能とより良い相関を持ち始めるはずだそうです。Nod.aiに関してですが、Nod.aiのプロジェクトを使っていくつかのNvidia GPUのテストも行ないましたが、Vulkanモデルでは、NvidiaのカードはAutomatic 1111で実行するよりも大幅に遅かったです。(4090で15.52 it/s、4080で13.31、3090 Tiで11.41、3090で10.76。他のカードは先に有効化しなければならなかったのでテストできませんでした)
チューニングモデルを使った7900カードの性能から、Nvidiaのカードが、どれだけTensorコアの恩恵を受けられるのかも気になるところです。4090は仕様上、RX 7900 XTXの5倍以上、疎らな行列演算を効率化するスパーシティ(Scarcity)の分を差し引いても2.7倍の性能を持っています。実際には、今の4090は、私たちが使ったバージョンではXTXの約50%しか速くありません。(精度が低くなるxformersを省けば、わずか13%に低下)。これは、IntelのArcカードにも当てはまります。
特に、FP16 XMX(行列)演算をサポートしているため、通常のFP32演算の最大4倍のスループットが得られるはずですが、IntelのArc GPUは現在非常に残念な結果を出しています。私たちが使用した現在のStable Diffusion OpenVINOプロジェクトも、改善の余地が大いにあるものと思われます。ちなみに、Arc GPU上でStable Diffusionを実行したい場合は、「stable_diffusion_engine.py」ファイルを編集して「CPU」を「GPU」に変更する必要があります。そうしないと、計算にグラフィックカードを使用しないため、大幅に時間がかかります。
全体として、今回固定したバージョンを使用すると、NvidiaのRTX 40シリーズのカードが最も速く、次に7900カード、そしてRTX 30シリーズGPUの順となります。RX 6000 シリーズは性能が低く、Arc GPU は全体的に貧弱な印象です。ソフトウェアのアップデートで状況が一変する可能性もありますし、AIの普及を考えると、より良いチューニングが行われるのは時間の問題だと思われます。(あるいは、より良いパフォーマンスを実現するためにすでにチューニングされている適切なプロジェクトがあるかるかもしれません)。
繰り返しになりますが、これらのプロジェクトがどの程度最適化されているかは明らかではありません。また、これらのプロジェクトが、NvidiaのTensorコアやIntelのXMXコアなどを十分に活用しているかどうかも不明です。そこで、さまざまなGPUの最大理論性能(TFLOPS)を見てみるのも面白いのではないかと考えました。次のグラフは、各GPUの FP16 の理論性能を示しています。(該当する場合、テンソル/マトリクスコアを使用しています。また、Nvidia の結果には、Scarcity(基本的に、行列の半分が0になっている乗算をスキップする機能。深層学習ワークロードではかなり頻繁に発生する)も含まれています)
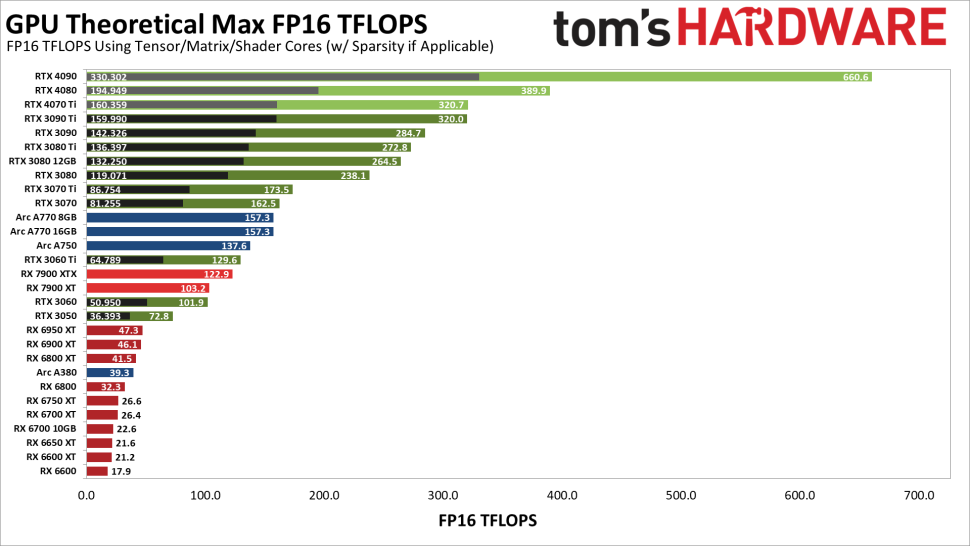
NvidiaのTensorコアは明らかにパンチ力を持っています。(灰色と黒のバーはScarcityなしです)。例えば、RTX 4090(FP16を使用)はRTX 3090 Tiに対して仕様上では最大106%高速ですが、私達のテストでは、xformerなしで43%高速で、xformerを使用すると50%高速になりました。また、私達が利用したStable Diffusionプロジェクト(Automatic 1111)は、Ada Lovelace GPUの新しいFP8命令を使用しないと仮定しており、RTX 40シリーズで再び性能が倍増する可能性があることにご注意ください。
一方、Arc GPUを見てください。その行列演算スコアは、RTX 3060 TiとRX 7900 XTXに近い性能を発揮するはずで、A380はRX 6800近辺にいます。
実際には、Arc GPUはそれらに近いところにいません。最速のA770 GPUはRX 6600とRX 6600 XTの間に位置し、A750はRX 6600のすぐ後ろに位置し、A380はA750の4分の1程度の速度です。つまり、どれも期待される性能の4分の1程度です。XMXコアが使われていないのであれば、納得がいきますね。
Arcの内部比率は、だいたい合っているように見えますが、A380の理論上の演算性能はA750の4分の1くらいで、今のStable Diffusionの性能はそこに着地しています。おそらく、Arc GPU は演算にシェーダーを使用し、全精密 FP32 モードで、追加の最適化が出来ていないのでしょう。
もうひとつ注目すべきは、AMD の RX 7900 XTX/XT の理論演算が、RX 6000 シリーズと比較して大きく向上していることです。6000番台のチューニングモデルがその差を縮めるかどうか、見ものですね。メモリ帯域は、少なくとも今回使用した512×512のターゲット解像度では重要な要素ではなく、3080の10GBと12GBのモデルは比較的近いところに位置しています。
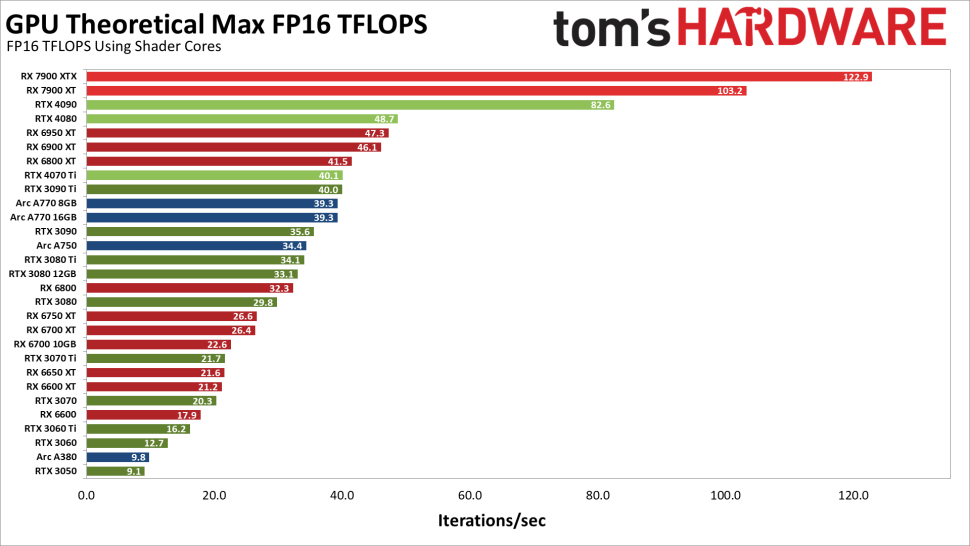
以下は、理論上のFP16の性能です。さまざまなGPUがシェーダ計算を介してできることだけに焦点を当てます。
NvidiaのAmpereアーキテクチャとAdaアーキテクチャは、FP32と同じ速度でFP16を実行します。これは、FP16をTensorコアを使ってコーディングできるようにしているためです。これに対してAMDとIntelのGPUは、FP16のシェーダ計算でFP32の2倍の性能を発揮しています。
明らかに、FP16計算のこの2番目の見方は、TensorとMatrixコアを使ったグラフよりも実際のパフォーマンスにマッチしていません。しかし、おそらく、行列計算のセットアップにさらなる複雑さがあるため、完全なパフォーマンスを得るには、何か特別なものが必要なのでしょう。そこで、最後のグラフをご覧ください。
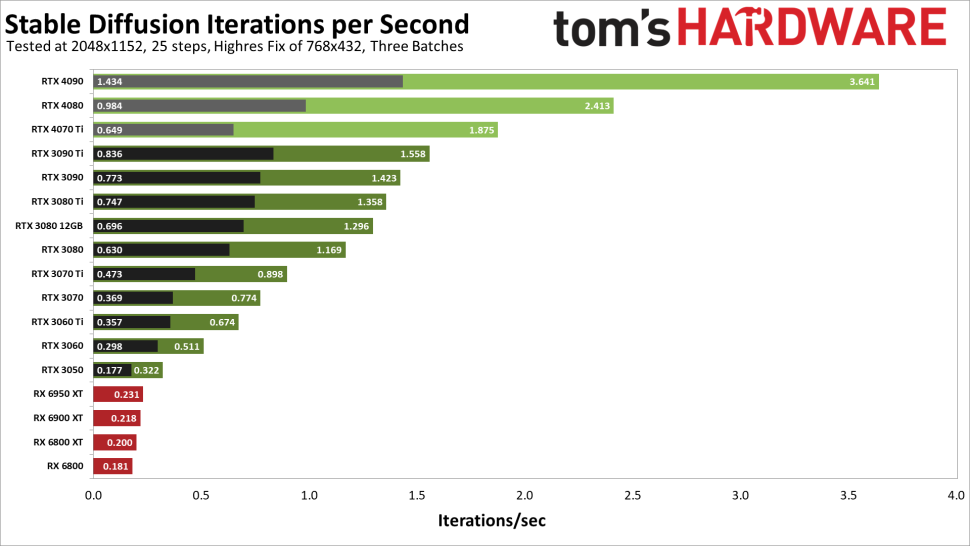
この最後のグラフは、より高い解像度でテストを行った結果を示しています。AMD RX 6000 シリーズのカードでは Linux を使用しなければならず、RX 7000 シリーズではより新しい Linux カーネルが必要で、それを動作させることができなかったため、新しい AMD GPU のテストは行っていません。しかし、Torch DLLを置き換えたRTX 40シリーズの結果をご覧ください。
RTX 4090は、3090 Tiに対してxformerなしで72%、xformerありでなんと134%も高速化されています。4080もxformersあり/なしで3090 Tiに55%/18%の差をつけています。4070 Tiは興味深いことに、xformersなしだと3090 Tiより22%遅いですが、xformersありだと20%速いです。
目標とした解像度が2048×1152と複雑なため、実行時間が長いため、潜在的な計算資源をより活用できるようになり、Tensorコアが十分に力を発揮できるようになったようです。
結論ですが、今回の比較はせいぜいStable Diffusionのパフォーマンスのスナップショットです。
プロジェクトの頻繁な更新、さまざまなトレーニング・ライブラリのサポートなど、さまざまなことが確認されています。来年には、さまざまなGPUに対してより最適化されたコードで、このトピックをさらに再検討する予定です。
著者
Jarred Waltonは、Tom’s Hardwareのシニアエディターで、GPUに関するあらゆる情報を扱っています。2004年から技術ジャーナリストとして活動し、AnandTech、Maximum PC、PC Gamerに記事を書いています。最初のS3 Virge「3D decelerators」から今日のGPUまで、Jarredはすべての最新グラフィックトレンドを把握し、ゲームパフォーマンスについて尋ねるべき人物です。
3.イラスト生成AIのStable DiffusionはどのGPUで実行するのが最速か?関連リンク
1)www.tomshardware.com
Stable Diffusion Benchmarked: Which GPU Runs AI Fastest (Updated)
2)github.com
AUTOMATIC1111 / stable-diffusion-webui(Nvidia)
nod-ai / SHARK (AMD)
bes-dev / stable_diffusion.openvino (Intel)

