
1.匿名化した確率的勾配降下法で広告の効果測定を行う(2/2)まとめ
・バッチサイズはノイズの量の削減などDP-SGDの学習の様々な側面に影響する
・大きなサイズのバッチ学習によりプライベートモデルの有用性が大幅に向上する
・DP-SGDを用いたプライベートモデルは通常のモデル比較してほぼ遜色がない
2.DP-SGDの性能
以下、ai.googleblog.comより「Private Ads Prediction with DP-SGD」の意訳です。元記事は2022年12月7日、Krishna Giri NarraさんとChiyuan Zhangさんによる投稿です。
アイキャッチ画像はstable diffusionの生成
ラージバッチトレーニング
バッチサイズはDP-SGDの学習の様々な側面に影響を与えるハイパーパラメータです。
例えば、バッチサイズを大きくすることで、同じプライバシー保証の条件下で学習中に加えるノイズの量を減らすことができ、学習時の変動を小さくすることができます。また、バッチサイズは、サブサンプリング確率や学習ステップなど、他のパラメータを介してプライバシー保証に影響を与えます。
バッチサイズの影響を定量的に示す簡単な式は存在しません。しかし、バッチサイズとノイズスケールの関係はプライバシーアカウンティングによって定量化されます。特定のバッチサイズを使用した場合に、与えられたプライバシー予算枠(ε)の下で必要なノイズスケール(標準偏差で測定)を計算することができます。
下図は、2つの異なるシナリオにおけるそのような関係を図にしたものです。最初のシナリオは、固定エポック、つまり、学習データセットを使用する回数を固定するものです。この場合、バッチサイズが大きくなると学習ステップ数が減少し、モデルが学習不足になる可能性があります。2つ目の、よりわかりやすいシナリオは、固定トレーニングステップ(fixed steps)を使用します。
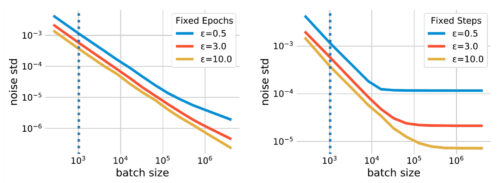
バッチサイズとノイズスケールの関係
プライバシーアカウンティングでは、与えられたプライバシー予算枠を満たすために、ノイズの標準偏差を必要とすます。この標準偏差はバッチサイズが大きくなるにつれて減少します。結果、バッチサイズを比較対象の非プライバシー手法(縦点線で示す)よりも大幅に大きくすることで、DP-SGDによって付加されるガウスノイズの規模を大幅に縮小することができます。
バッチサイズを大きくすることで、ノイズスケールを小さくできることに加え、DP-SGDで必要とされる、各サンプルごとの勾配のノルムクリッピングをより大きな閾値で行うことも可能になります。ノルムクリッピングステップは平均勾配推定にバイアスをもたらすので、この緩和はそのようなバイアスを軽減します。
以下の表は、Criteoデータセットにおいて、標準バッチサイズ(1,024サンプル)と大規模バッチサイズ(16,384サンプル)を用い、大きなクリッピングと学習エポック数を増やしたpCTRの結果を比較したものです。
その結果、大きなサイズのバッチ学習によりモデルの有用性が大幅に向上することが確認されました。なお、大きなクリッピングは大きなバッチサイズでのみ可能です。また、言語およびComputer Vision分野におけるDP-SGDの学習においても、大規模なバッチ学習が不可欠であることがわかりました。
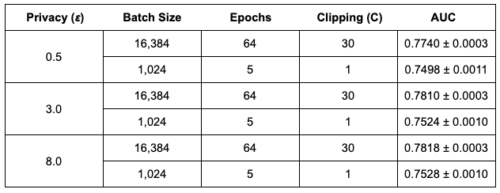
大規模バッチ学習の効果
3種類のプライバシー予算枠(ε)において、大きなバッチサイズ(16,384)でpCTRモデルを学習した場合、通常のバッチサイズ(1,024)に比べてAUCが著しく高くなることが分かります。
サンプルごとの高速な勾配ノルム計算
DP-SGDで使用されるサンプル単位の勾配ノルム計算は、しばしば計算量とメモリの増加を引き起こします。
この計算により、(GPUなどの)アクセラレータにおける標準的なバックプロパゲーションの効率は失われ、各サンプルごとの勾配を具体化せずにバッチの平均勾配を計算することになります。
しかし、ある種のニューラルネットワーク層の場合、効率的な勾配ノルム計算アルゴリズムにより、サンプルごとの勾配ベクトルを実体化することなく、サンプルごとの勾配ノルムを計算することができます。また、私達はこのアルゴリズムは、広告予測問題を解くためのembedding層と完全連結層に依存するニューラルネットワークモデルを効率的に扱うことができることにも注目します。
この2つの考察を組み合わせて、私達はこのアルゴリズムを用いてDP-SGDアルゴリズムの高速版を実装します。
pCTR上のFast-DP-SGDは、非プライベートな比較対象手法と同じ数の学習サンプルと同じ最大バッチサイズを1つのGPUコアで扱えることを示します。
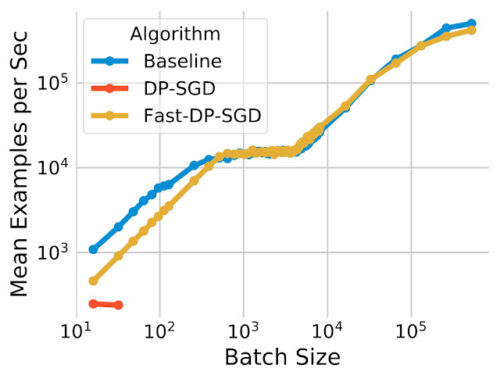
私達の高速実装(Fast-DP-SGD)のpCTR上での計算効率
非プライベートな比較対象手法と比較すると、非常に小さなバッチサイズを除いて、学習スループットは同程度です。また、JAXジャストインタイム(JIT)コンパイルを利用した実装とも比較しました。JITコンパイルはすでに素のDP-SGD実装よりもはるかに高速です。
私達の実装は高速であるだけでなく、メモリ効率も優れています。JITベースの実装では64以上のバッチサイズを扱うことができませんが、私達の実装では最大50万バッチまで扱うことができます。
メモリ効率は、大規模バッチ学習を可能にするために重要です。大規模バッチ学習は上記で示されたように実用性を高めます。
まとめ
DP-SGDを用いたプライベート広告予測モデルが、比較対象とした非プライベート手法と比較して、計算量、メモリ消費量ともに最小限に増加に抑えたまま、実用性の高いモデルを学習することが可能であることを示しました。私たちは、事前学習などの手法により、実用性ギャップをさらに縮小する余地があると考えています。実験の詳細については、論文をご覧ください。
謝辞
本研究は、Carson Denison、Badih Ghazi、Pritish Kamath、Ravi Kumar、Pasin Manurangsi、Amer Sinha、Avinash Varadarajanとの共同作業により実施されました。また、Silvano BonacinaとSamuel Ieongには、多くの有益な考察をいただきました。
3.匿名化した確率的勾配降下法で広告の効果測定を行う(2/2)関連リンク
1)ai.googleblog.com
Private Ads Prediction with DP-SGD
2)arxiv.org
Private Ad Modeling with DP-SGD
3)petsymposium.org
Connect the Dots: Tighter Discrete Approximations of Privacy Loss Distributions

