
1.匿名化した確率的勾配降下法で広告の効果測定を行う(1/2)まとめ
・プライバシーと使い勝手の良さを両立するMLアルゴリズムが求められている
・最も広く使われているアルゴリズムはDP-SGDと呼ばれるSGDの拡張版
・DP-SGDは計算負荷とモデル精度の低下をもたらし適用が難しいと思われていた
2.DP-SGDとは?
以下、ai.googleblog.comより「Private Ads Prediction with DP-SGD」の意訳です。元記事は2022年12月7日、Krishna Giri NarraさんとChiyuan Zhangさんによる投稿です。
アイキャッチ画像はstable diffusionの生成+DALL E2アウトペインティングでジブリとルーカスがコラボした架空の映画の広告
広告テクノロジー提供者は、機械学習(ML:Machine Learning)モデルを広く使用して、最も関連性の高い広告を予測してユーザーに提示し、その広告の効果を測定しています。
オンラインプライバシーへの注目が高まる中、より優れたプライバシーと使い勝手のトレードオフを実現するMLアルゴリズムを特定する機会が訪れています。
差分プライバシー(DP:Differential Privacy)は、証明可能なプライバシー保証を持つMLアルゴリズムを責任を持って開発するための一般的なフレームワークとして登場しました。DPはプライバシーに関する文献で広く研究され、産業界や米国国勢調査で採用されています。
直感的な説明をすると、DPフレームワークは、ユーザーレベルでの個人情報を保護しつつ、MLモデルが集団全体の特性を学習することを可能にします。
MLモデルの学習では、アルゴリズムにデータセットを入力とし与えると、学習済みのモデルが出力として生成されます。
確率的勾配降下法(SGD:Stochastic Gradient Descent)は、一般的に用いられる非自己学習アルゴリズムで、ランダムに選択したデータの一部(ミニバッチと呼ばれます)から平均勾配を計算し、そのミニバッチに適合するようにモデルの修正すべき方向を示すために使用されます。
深層学習で最も広く使われているDP学習アルゴリズムは、DP Stochastic Gradient Descent(DP-SGD)と呼ばれるSGDの拡張版です。
DP-SGDは以下の2つの追加ステップを含みます。
(1)平均化する前に、各サンプルの勾配のL2ノルムが事前に定義された閾値を超えた場合にノルムを刈り取ります。
(2)モデルを更新する前に平均勾配にガウスノイズが追加されます。
DP-SGDは、SGDやAdamなどのオプティマイザをそれらのDPの亜種に置き換えることで、既存のあらゆる深層学習パイプラインに最小限の変更で適用することが可能です。
しかし、DP-SGDを実際に適用すると、大きな計算上の負荷を伴い、モデルの実用性(すなわち精度)が大きく損なわれる可能性があります。
そのため、より実用的で大規模な深層学習問題に対してDP-SGD学習を適用する試みが様々な研究により行われています。最近の研究でも、コンピュータビジョンや自然言語処理の問題で有望なDP学習の結果が示されています。
論文「Private Ad Modeling with DP-SGD」では、視覚や言語タスクと比較して特異な課題が存在する広告モデリング問題に対するDP-SGD学習の系統的な研究を紹介します。
広告データセットは、データクラス間の不均衡が大きく、また、多数のユニークな値を持つカテゴリ特徴から構成されていることが多いため、大きなembedding層と非常にまばらな勾配更新を持つモデルになることが分かっています。
本研究では、DP-SGDにより、高プライバシー環境下においても、従来予想されていたよりもはるかに小さな効用差で広告予測モデルを匿名化したままで学習できることを実証します。さらに、適切な実装により、DP-SGD学習における計算とメモリのオーバーヘッドを大幅に削減できることを実証します。
評価方法
広告のクリック率予測(pCTR)、広告クリック後のコンバージョン率予測(pCVR)、広告クリック後のコンバージョン期待回数予測(pConvs)の3つの広告予測タスクを用いて、プライベート学習の評価を行いました。
pCTRについては、pCTRモデルのベンチマークとして広く公開されているCriteoのデータセットを使用しています。pCVRとpConvsはGoogleの内部データセットを用いて評価します。
pCTRとpCVRはバイナリクロスエントロピー損失で学習するバイナリ分類問題であり、テストのAUC損失(すなわち1-AUC)を報告します。pConvsはポアソン対数損失(PLL:Poisson Log Loss)で学習する回帰問題であり、テストのPLLを報告します。
各タスクについて、DP-SGDのプライバシーと実用性のトレードオフを、様々なプライバシー予算枠下でのプライベート学習済みモデルの損失の相対的増加(すなわち、プライバシー損失)により評価します。
プライバシー予算枠下はスカラーεで特徴付けられ、εが低いほどプライバシーが高いことを示します。プライベート学習と非プライベート学習の間の効用ギャップを測定するために、非プライベートモデル(ε=∞に相当)と比較して損失の相対的増加を計算します。
私達の主な観測は、3つの一般的な広告予測タスクすべてにおいて、非常に高いプライバシー(例えば、ε <= 1)体制であっても、相対的な損失の増加は以前に予想されたよりもはるかに小さくすることができることです。
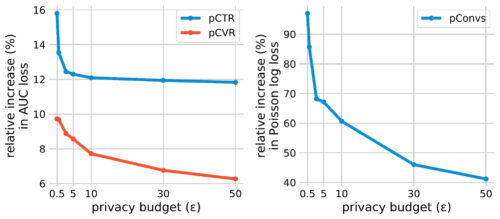
3つの広告予測タスクにおけるDP-SGDの結果
各タスクの非プライバシー基準(すなわち、ε = ∞)モデルに対する損失の相対的増加を計算したものです。
プライバシーアカウンティングの改善
プライバシーアカウンティング(Privacy accounting)は、ガウスノイズ乗数や他の学習ハイパーパラメータが与えられたDP-SGD学習モデルのプライバシーバジェット(ε)を推定します。
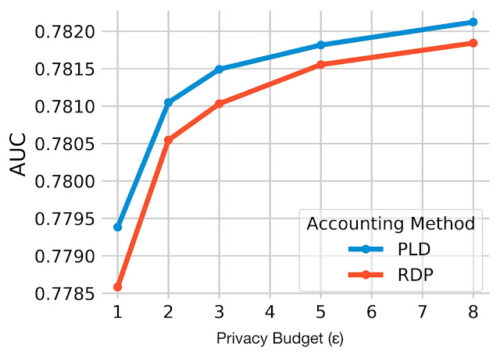
Rényi差分プライバシー(RDP:Rényi Differential Privacy)アカウンティングは、オリジナルの論文以来、DP-SGDにおいて最も広く用いられているアプローチです。
私達は、より厳密な推定値を提供するために、アカウンティング手法の最新の進歩を探求しています。具体的には、プライバシー損失分布(PLD:Privacy Loss Distribution)に基づくアカウンティングに新しい手法であるconnect-the-dotsを使用します。
次の図は、この改良されたアカウンティングを従来のRDPアカウンティングと比較し、PLDアカウンティングが全てのプライバシーバジェット(ε)に対してpCTRデータセットのAUCを改善することを実証しています。
3.匿名化した確率的勾配降下法で広告の効果測定を行う(1/2)関連リンク
1)ai.googleblog.com
Private Ads Prediction with DP-SGD
2)arxiv.org
Private Ad Modeling with DP-SGD
3)petsymposium.org
Connect the Dots: Tighter Discrete Approximations of Privacy Loss Distributions

