
1.差分プライバシーを使って大規模な画像分類モデルを学習(1/2)まとめ
・大量データを集約して学習データにしていてもモデルは個人に関する特徴を取り込み可能
・個人に関する特徴が符号化されないようにするため連合学習の重要性が高まっている
・データプライバシーが保証されるDP-SGDには非効率で遅そく実用に耐えない欠点がある
2.差分プライバシーで大規模モデルを学習させる困難さ
以下、ai.googleblog.comより「Applying Differential Privacy to Large Scale Image Classification」の意訳です。元記事は2022年2月1日、Alexey KurakinさんとRoxana Geambasuさんによる投稿です。
大規模なイメージを表現したかったアイキャッチ画像のクレジットはPhoto by Nick Decorte on Unsplash
機械学習(ML:Machine Learning)モデルは、推薦システムから画像の自動分類システムまで、様々な一般消費者向け製品において性能が向上しており、ますます価値が高まっています。
しかし、大量のデータを集約して学習データにしていても、理論的には、モデルは学習データから個人に関する特徴を取り込むことは可能です。
例えば、電子メールデータセットを用いて学習させた言語モデルは、学習データに含まれる機密情報を符号化してしまう場合があり、学習セット内に特定のユーザーに関するデータが含まれているか否かを明らかにしてしまう可能性があることが、管理された実験環境内での実験により示されています。
そのため、個々の学習項目からそのような特徴が符号化されないようにすることが重要です。このため、研究者は連合学習(federated learning)アプローチを採用することが多くなっています。
差分プライバシー(DP:Differential Privacy)は、システムやアルゴリズムのプライバシー保証を定量化し、理解することを可能にする厳密な数学的枠組みを提供します。
DPの枠組みでは、システムのプライバシー保証は通常、プライバシー損失境界と呼ばれる正のパラメータεによって特徴付けられ、εが小さいほど、より良いプライバシーに対応しています。通常、DP保証を持つモデルの学習には、DP-SGDという特殊な学習アルゴリズムが用いられ、学習されたモデルに対してDP保証が提供されます。
しかし、DP-SGDを用いた学習には、一般的に2つの大きな欠点があります。
まず、DP-SGDの既存のほとんどの実装は非効率で遅いため、大規模なデータセットに使用することが困難です。第二に、DP-SGDによる学習は、実用性(モデルの精度など)に大きな影響を与えることが多く、DP-SGDで学習したモデルが実際には使用に耐えない可能性がある点です。
そのため、ほとんどのDP研究論文では、DPアルゴリズムを非常に小さなデータセット(MNIST、CIFAR-10、UCI)で評価し、ImageNetなどの大きなデータセットでの評価を行おうともしていません。
論文「Toward Training at ImageNet Scale with Differential Privacy」では、DPを用いてImageNet上の大規模画像分類モデルを高精度かつ最小限の計算コストで学習させるという、私たちの進行中の取り組みの初期結果を共有しています。
モデルやハイパーパラメータの慎重な選択、フルバッチトレーニング、他のデータセットからの転移学習など、様々な学習技術の組み合わせにより、DPを用いて学習したImageNetモデルの精度を大幅に向上させることができることを示しています。これらの発見を実証し、今後の研究を促進するため、関連するソースコードも公開しています。
ImageNetを使って差分プライバシーを検証
DPの実用性と有効性を実証するためにImageNetの分類を選んだのは、以下の理由からです。
(1)DPにとって野心的な課題であり、先行研究が十分な進展を示していないこと
(2)他の研究者が取扱可能な公開データセットであり、現実のDP訓練の有用性を共同で向上させる機会であること
ImageNetを使った分類は、多くのパラメータを持つ大規模なネットワークが必要なため、DPにとって挑戦的です。これは、計算実行中に加わるノイズがモデルの大きさに比例して大きくなることを意味します。
JAXを使って差分プライバシーの規模を拡大
DPに何が有効かを研究するために、複数のアーキテクチャや学習構成を模索することは、時間がかかり消耗します。
そこで、XLAをベースにした高性能計算ライブラリであるJAXを使用し、効率的な自動ベクトル化と数学計算のジャストインタイムコンパイルを実現しました。これらのJAXの機能を利用することは、CIFAR-10のような小規模なデータセットにおけるDP-SGDの高速化に有効な方法として以前から推奨されていました。
私たちJAX上でDP-SGDの実装を独自に作成し、大規模なImageNetデータセットに対してベンチマークを行いました。(私たちの公開コードに含まれています)。JAXでの実装は比較的シンプルで、XLAコンパイラを使用しただけで顕著な性能向上が得られました。
DP-SGDの他の実装(Tensorflow Privacyの実装など)と比較すると、JAXの実装は常に数倍速くなっています。カスタムビルドされ最適化されたPyTorch Opacusと比較しても、一般的にさらに高速になります。
私たちのDP-SGD実装では、各ステップごとにネットワークを約2回前後に通過させます。これは、1回の前方・後方パスで済む非プライベートな学習手法よりも遅いですが、それでもDP-SGDに必要なサンプル単位の勾配で学習する既知のアプローチとしては最も効率的なものです。
以下のグラフは、ImageNetの2つのモデルについて、DP-SGDと非プライベートなSGD、それぞれJAXを使ったトレーニング実行時間を示しています。
全体として、JAX上のDP-SGDは、非プライベート学習と比較して、最適なハイパーパラメータを求めるための学習回数をわずかに減らすだけで、大規模な実験を十分に高速に実行できることがわかりました。これは、CIFAR10やMNISTベンチマークで5倍から10倍遅いことが判明したTensorflow Privacyのような代替品より、かなり優れています。
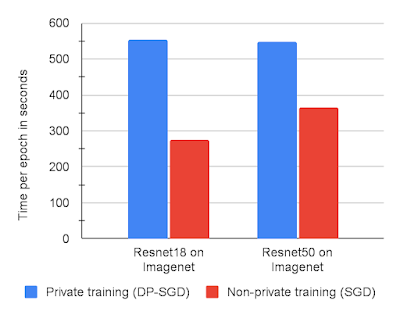
V100GPUを8台使用したResnet18またはResnet50アーキテクチャによるImageNetの学習エポックあたりの時間(秒)
3.差分プライバシーを使って大規模な画像分類モデルを学習(1/2)関連リンク
1)ai.googleblog.com
Applying Differential Privacy to Large Scale Image Classification
2)arxiv.org
Toward Training at ImageNet Scale with Differential Privacy
3)github.com
google-research / dp-imagenet

