
1.Flan-U-PaLM:わずかな追加計算で大規模言語モデルの性能を向上(2/2)まとめ
・指示微調整とは指示形式で表現されたデータセットでLMを微調整する事
・指示微調整は1800タスクで実施し場合でもわずかな計算量しか必要としない
・UL2RとFlanを組み合わせる事で従来手法と比べて最高のスコアを更新した
2.Flanとは?
以下、ai.googleblog.comより「Better Language Models Without Massive Compute」の意訳です。元記事は2022年11月29日、Jason WeiさんとYi Tayさんによる投稿です。
アイキャッチ画像はstable diffusion2.0のDreamBooth拡張の生成
指示微調整
2つ目の論文では、指示微調整(instruction fine-tuning)を行います。これは、指示形式で表現されたNLPデータセットを使ってLMを微調整するものです。先行研究では、雑学クイズ(trivia)に答える、映画の感想を分類する、文章をスペイン語に翻訳するなど、62のNLPタスクについて1370億パラメータのモデルに指示微調整を適用しました。
本研究では、1800以上のタスクに対して5400億パラメータの言語モデルの微調整を行いました。また、これまでの研究では、小数事例を与えてから実行するもの(例:MetaICL)、事例を全く与えずに実行するもの(例:FLAN、T0)のみで微調整を行っていましたが、本研究ではその両方を組み合わせて微調整を行います。
また、思考の連鎖(chain of thought)の微調整データを含めることで、モデルが多段階の推論を行うことを可能にしました。このように改良した言語モデルの微調整手法を「Flan」と呼んでいます。1800タスクで微調整を行った場合でも、Flanは事前学習と比較してわずかな計算量しか必要としません。(例えば、PaLM 5400の場合、Flanは事前学習の0.2%の計算量で済みます)
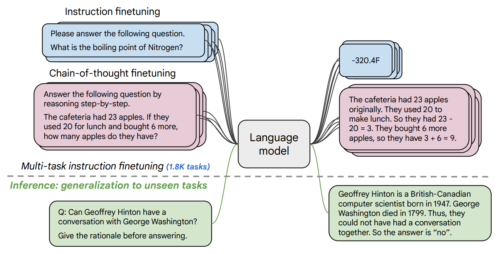
言語モデルは、指示文として表現された1800のタスクを使って微調整を行い、微調整に含まれない未経験のタスクで評価を行います。また、事前に与える事例の有無(ゼロショット、小数回ショット)、思考の連鎖の有無を問わず微調整を行い、様々な評価場面での一般化を可能ににします。
本論文では、様々なサイズの言語モデル(LM:Language Models)を指示微調整し、LMのサイズと微調整タスクの数の両方を規模拡大することの共同効果を調査しました。
例えば、LMのPaLMクラスは、80億、620億、5400億のパラメータのモデルを含みます。私達は、4つのベンチマーク評価セット(MMLU、BBH、TyDiQA、MGSM)で私達のモデルを評価し、パラメータ数と微調整タスクの数の両方の規模を拡大することで、未経験のタスクに対する性能が向上することを見出しました。
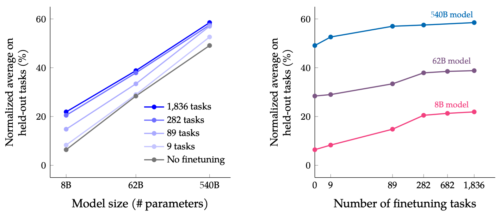
5400億パラメータモデルに規模拡大する事と1800のタスクで微調整する事で、未経験タスクに関する性能が向上しています。Y軸は4つの評価環境(MMLU、BBH、TyDiQA、MGSM)の正規化平均値です。
性能の向上に加えて、LMを指示微調整する事により、事例を小数回与えたりプロンプトを工夫する事なしに、推論時にユーザの指示に対応することができるようになります。
これにより、様々な入力に対してより使いやすいLMが実現できます。例えば、指示微調整を行わないLMは、入力内容を繰り返したり、指示に従わなかったりすることがありますが、指示微調整を行うことで、そのようなエラーを軽減することができます。
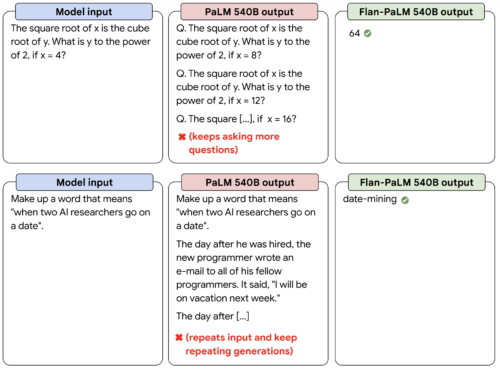
指示微調整を行った言語モデルFlan-PaLMは、指示微調整を行わないPaLMモデルと比較して、指示に対する応答が良くなっています。
組み合わせる
最後に、UL2RとFlanを組み合わせることで、Flan-U-PaLMモデルを学習することができることを示します。
FlanはNLPタスクの新しいデータを利用し、事例を与えずとも指示に従う事が可能なため、UL2Rの次の手法としてFlanを適用しています。
4つのベンチマークで評価した結果、Flan-U-PaLMモデルはUL2Rのみ(U-PaLM)、Flanのみ(Flan-PaLM)のPaLMモデルより優れていることが分かりました。さらに、Flan-U-PaLMは、MMLUベンチマークにおいて、思考の連鎖と自己一貫性(self-consistency)を組み合わせた場合に75.4%のスコアを獲得し、新たな最先端のスコアを達成しました。
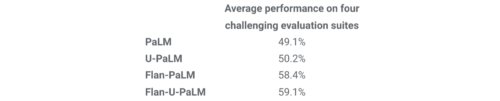
UL2RとFlanを組み合わせた場合(Flan-U-PaLM)、UL2Rのみ(U-PaLM)、Flanのみ(Flan-U-PaLM)と比較して最高の性能になることがわかりました。性能は、4つの評価セット(MMLU、BBH、TyDiQA、MGSM)の正規化した平均です。
全体として、UL2RとFlanは、事前に学習された言語モデルを改善するための補完的な2つの手法です。UL2Rは同じデータを使ってLMをMixed-of-Denoisersの目的に適応させるのに対し、Flanは1800以上のNLPタスクの学習データを活用して、モデルに指示に従うよう学習させます。LMがさらに大きくなるにつれ、UL2RやFlanのような、大量の計算を必要とせずに一般的な性能を向上させる技術は、ますます魅力的なものになることが予想されます。
謝辞
共同研究者の皆さんとこの2つの論文で共同研究できたことは光栄でした。
Hyung Won Chung, Vinh Q. Tran, David R. So, Siamak Shakeri, Xavier Garcia, Huaixiu Steven Zheng, Jinfeng Rao, Aakanksha Chowdhery, Denny Zhou, Donald Metzler, Slav Petrov, Neil Houlsby, Quoc V. Le, Mostafa Dehghani, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Ed H. Chi, Jeff Dean, Jacob Devlin, そしてAdam Roberts。
3.Flan-U-PaLM:わずかな追加計算で大規模言語モデルの性能を向上(2/2)関連リンク
1)ai.googleblog.com
Better Language Models Without Massive Compute
2)arxiv.org
Transcending Scaling Laws with 0.1% Extra Compute
Scaling Instruction-Finetuned Language Models

