
1.Table Tennis:俊敏な動きを研究するためにロボットと卓球をする(1/2)まとめ
・卓球は人間や他のロボットと対戦できるので強化学習の試験環境として有用
・モデルがなければデータが収集できないがデータがなければモデルの学習は不可
・i-S2Rはこの「鶏と卵」の問題を解決するための解決策を提示する新手法
2.Iterative-Sim2Realとは?
以下、ai.googleblog.comより「Table Tennis: A Research Platform for Agile Robotics」の意訳です。元記事は2022年10月18日、Avi SinghさんとLaura Graesserさんによる投稿です。
アイキャッチ画像はstable diffusionの生成で卓球をするトトロ
ロボットの学習は、器用な操作、脚の運動、物体の把持など、実世界の難しいタスクに幅広く適用されています。しかし、卓球(Table Tennis)のような人間とロボットの緊密な相互作用を必要とする動的で加速するタスクに、ロボット学習が適用されている例はあまりありません。
卓球の難しさには、ロボット学習の研究にとって興味深い2つの補完的な性質があります。まず、この課題では速度と精度の両方が要求されるため、学習アルゴリズムに大きな要求がなされます。同時に、この課題は高度に構造化されており(固定された予測可能な環境)、自然にマルチエージェント化される(ロボットは人間や他のロボットと対戦できる)ため、人間とロボットの相互作用や強化学習に関する問題を調査するための望ましい試験環境となります。このような特性から、いくつかの研究グループが卓球の研究プラットフォームを開発しています。
GoogleのRoboticsチームは、マルチプレイヤーで動的かつインタラクティブな環境におけるロボット学習から生じる問題を研究するために、このようなプラットフォームを構築しました。この記事の続きでは、これまで調査してきた問題を示す2つのプロジェクト、Iterative-Sim2Real(CoRL 2022で発表予定) とGoalsEye(IROS 2022)を紹介します。Iterative-Sim2Realは、ロボットが人間のプレーヤーと300打以上のラリーを行うことを可能にし、GoalsEyeは、アマチュアの人間の精度に匹敵するゴール条件付きポリシーの学習を可能にします。

人間と協調してプレイするIterative-Sim2Realポリシー

異なる場所にボールを返すGoalsEyeポリシー
Iterative-Sim2Real: シミュレータを活用し人間と協調プレイ
このプロジェクトでは、ロボットの目標は人間との協力プレイであり、できるだけ長くラリーを続けることです。実世界で人間と直接対戦する訓練は面倒で時間がかかるため、シミュレーションによるアプローチ(例:sim-to-real)を採用しています。しかし、人間の行動を正確にシミュレートすることは困難であるため、人間との緊密なやりとりが必要なタスクにsim-to-realの学習を適用することは困難です。
Iterative-Sim2R(以下、i-S2R)では、人間とロボットが相互にやりとりを行うタスクのための人間行動モデルの学習方法を提案し、私達のロボット卓球プラットフォームで実現します。私たちは、アマチュアの人間プレーヤーと最大340打のラリーを実現するシステムを構築しました。(下図)
人間行動モデルの学習:鶏と卵の問題
ロボット工学のための正確な人間行動モデル(human behavior models)を学習する際の中心的な問題は、次のとおりです。
最初に十分なロボットポリシーがなければ、人間がロボットとどのように相互作用するかについての高品質のデータを収集することができません。しかし、人間の行動モデルがなければ、そもそもロボットのポリシーを得ることができません。
代替手段には実世界で直接ロボットポリシーを学習させるという方法もありますが、時間がかかり、コストがかかり、安全面でも問題があります。
i-S2Rは、この「鶏と卵」の問題を解決するためのソリューションです。i-S2Rは、人間の行動に関するシンプルなモデルをおおよその出発点とし、シミュレーションによる訓練と実世界での展開を交互に繰り返します。その繰り返しで、人間行動モデルとポリシーの双方が洗練されていきます。

i-S2Rの手法
研究成果
i-S2Rを評価するため、5人の人間相手に5回のトレーニングを行い、通常のSIM-TO-REAL+FINE-TUNING(S2R+FT)の手法と比較しました。全プレイヤーで集計すると、i-S2Rのラリー長はS2R+FTよりも約9%長くなっています(下左図)。i-S2RとS2R+FTのラリー距離のヒストグラム(下図右)を見ると、S2R+FTではラリー距離が短い(5本以下)ものが多く、i-S2Rでは長いラリーが多くなっていることがわかります。
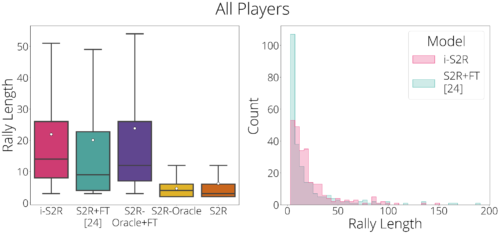
i-S2Rの評価結果概要
箱ひげ図では白丸は平均値、水平線は中央値、箱ひげは25%および75%です。
また、プレイヤーのタイプ別に、初級者(40%)、中級者(40%のプレイヤー)、上級者(20%のプレイヤー)に分けて、結果をみています。i-S2Rは、初級者、中級者ともにS2R+FTを大きく上回っていることがわかります(プレイヤーの80%)。
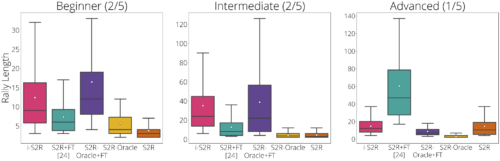
i-S2R プレーヤータイプ別の実績
i-S2Rの詳細は、論文、ウェブサイト、および以下の概要ビデオでご覧いただけます。
3.Table Tennis:俊敏な動きを研究するためにロボットと卓球をする(1/2)関連リンク
1)ai.googleblog.com
Table Tennis: A Research Platform for Agile Robotics
2)arxiv.org
i-Sim2Real: Reinforcement Learning of Robotic Policies in Tight Human-Robot Interaction Loops
GoalsEye: Learning High Speed Precision Table Tennis on a Physical Robot
3)sites.google.com
i-Sim2Real: Reinforcement Learning of Robotic Policies in Tight Human-Robot Interaction Loops
GoalsEye: Learning High Speed Precision Table Tennis on a Physical Robot

