
1.TensorStore:ペタサイズの高次元データを柔軟に効率的に処理する(1/2)まとめ
・最近の機械学習はペタ規模の巨大多次元データセットを操作する事も多い
・データは順番に読まれるわけではなく複数マシンに分散される事もある
・TensorStoreは高次元データの操作に特化したC++とPython用ライブラリ
2.TensorStoreとは?
以下、ai.googleblog.comより「TensorStore for High-Performance, Scalable Array Storage」の意訳です。
元記事の投稿は2022年9月22日、Jeremy Maitin-ShepardさんとLaramie Leavittさんによる投稿です。
アイキャッチ画像はstable diffusionの生成で大事な物を格納しようとしているトトロ
コンピュータサイエンスと機械学習(ML:Machine Learning)の多くのエキサイティングな現代的アプリケーションは、単一の大きな座標系にまたがる多元データセットを操作します。
例えば、空間グリッド上の大気測定値を使った気象モデリングや、2Dまたは3Dスキャンにおけるマルチチャンネル画像強度値からの医療画像予測などです。このような環境では、単一のデータセットでさえ、テラバイトからペタバイトのデータストレージを必要とする場合があります。このようなデータセットは、ユーザーが不規則な間隔や様々な規模でデータを読み書きする可能性があり、また、多くの場合、多数のマシンを並行して使用して分析を実行することに関心があるため、作業も困難です。
本日、n次元データの保存と操作のために設計された、オープンソースのC++とPythonのソフトウェアライブラリであるTensorStoreを紹介します。
・zarrやN5を含む複数の配列フォーマットの読み書きのための統一されたAPIを提供します。
・Google Cloud Storage、ローカルおよびネットワークファイルシステム、HTTPサーバ、インメモリストレージなど、複数のストレージシステムをネイティブにサポートします。
・強力な不可分性、一貫性、独立性、および永続性(ACID:Atomicity, Isolation, Consistency, Durability)保証によるリード/ライトバック・キャッシングとトランザクションをサポートします。
・楽観的並行性(optimistic concurrency)により、複数のプロセスやマシンからの安全で効率的なアクセスをサポートします。
・非同期APIにより、高レイテンシのリモートストレージに対しても高スループットのアクセスを実現します。
・高度で全てを構成可能なインデックス操作と仮想ビューを提供します。
TensorStoreは、すでに科学計算における重要な工学的課題の解決に利用されています。(例えば、ペタスケールの3D電子顕微鏡データや神経細胞活動の「4D」ビデオなど、神経科学の大規模データセットの管理・処理など)。
また、TensorStoreは、分散学習時のモデルパラメータ(チェックポイント)管理の問題を解決し、PaLMなどの大規模機械学習モデルの作成に利用されています。
データアクセス・操作のための使い慣れたAPI
TensorStoreは、大規模な配列データを読み込み、操作するためのシンプルなPython APIを提供します。以下の例では、ハエの脳の56兆の三次元画素の3D画像を表すTensorStoreオブジェクトを作成し、そのデータの小さな100×100の断片をNumPy配列としてアクセスします。
>>> import tensorstore as ts
>>> import numpy as np
# Create a TensorStore object to work with fly brain data.
>>> dataset = ts.open({
... 'driver':
... 'neuroglancer_precomputed',
... 'kvstore':
... 'gs://neuroglancer-janelia-flyem-hemibrain/' +
... 'v1.1/segmentation/',
... }).result()
# Create a 3-d view (remove singleton 'channel' dimension):
>>> dataset_3d = dataset[ts.d['channel'][0]]
>>> dataset_3d.domain
{ "x": [0, 34432), "y": [0, 39552), "z": [0, 41408) }
# Convert a 100x100x1 slice of the data to a numpy ndarray
>>> slice = np.array(dataset_3d[15000:15100, 15000:15100, 20000])
重要なことは、特定の100×100のスライスが要求されるまで、実際のデータにはアクセスされず、メモリにも保存されないことです。
したがって、標準的なNumPyの操作とほぼ同じインデックス付けと操作の構文を使って、データセット全体をメモリに格納することなく、任意の大きさの基礎となるデータセットをロードして操作することができます。
また、TensorStoreは、変換、アライメント、ブロードキャスト、仮想ビュー(データ型変換、ダウンサンプリング、遅延オンザフライ生成配列)など、高度なインデックス機能を幅広くサポートしています。
以下の例では、TensorStoreを使用してzarr配列を作成する方法と、その非同期APIによって高いスループットを実現する方法を示しています。
>>> import tensorstore as ts
>>> import numpy as np
>>> # Create a zarr array on the local filesystem
>>> dataset = ts.open({
... 'driver': 'zarr',
... 'kvstore': 'file:///tmp/my_dataset/',
... },
... dtype=ts.uint32,
... chunk_layout=ts.ChunkLayout(chunk_shape=[256, 256, 1]),
... create=True,
... shape=[5000, 6000, 7000]).result()
>>> # Create two numpy arrays with example data to write.
>>> a = np.arange(100*200*300, dtype=np.uint32).reshape((100, 200, 300))
>>> b = np.arange(200*300*400, dtype=np.uint32).reshape((200, 300, 400))
>>> # Initiate two asynchronous writes, to be performed concurrently.
>>> future_a = dataset[1000:1100, 2000:2200, 3000:3300].write(a)
>>> future_b = dataset[3000:3200, 4000:4300, 5000:5400].write(b)
>>> # Wait for the asynchronous writes to complete
>>> future_a.result()
>>> future_b.result()
安全で高性能な規模拡大
大規模な数値データの処理と解析には、膨大な計算リソースが必要です。これは通常、多くのマシンに分散する多数のCPUコアやアクセラレータコアにまたがる並列化によって達成されます。そのため、TensorStoreの基本的な目標は、安全性(並列アクセスパターンから生じる破損や不整合を回避)と高性能(計算中にTensorStoreへの読み書きがボトルネックにならない)の両方を備えた個々のデータセットの並列処理を可能にすることでした。
実際、Googleのデータセンター内でのテストでは、CPUの数を増やすと、読み込みと書き込みの性能がほぼ線形にスケーリングされることがわかりました。
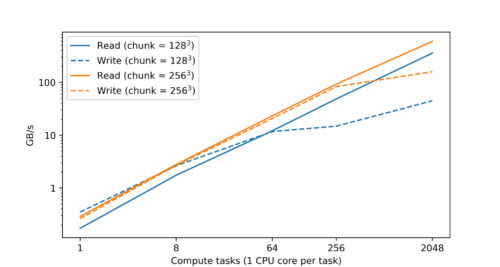
Google Cloud Storage(GCS)上のzarr形式のTensorStoreデータセットに、Googleデータセンターでシングルコアの計算タスクを可変個数使用して同時アクセスした場合の読み込みと書き込みのパフォーマンスです。読み取り性能と書き込み性能の両方が、計算タスクの数に対してほぼ線形に伸びていきます。
C++で主要処理を実装し、エンコード/デコードやネットワークI/Oなどの処理にマルチスレッドを多用し、チャンキングによって大きなデータセットをより小さな単位に分割して、データセット全体のサブセットを効率的に読み書きできるようにすることでパフォーマンスを実現しています。
また、TensorStoreは、設定可能なインメモリキャッシング(頻繁にアクセスされるデータのストレージシステムとのやりとりにかかる時間を短縮)と、プログラムが他の作業を完了している間、バックグラウンドで読み取りまたは書き込み操作を継続できる非同期APIも提供します。
3.TensorStore:ペタサイズの高次元データを柔軟に効率的に処理する(1/2)関連リンク
1)ai.googleblog.com
TensorStore for High-Performance, Scalable Array Storage
2)github.com
google / tensorstore

