
1.LOLNeRF:1枚の画像から3次元構造を学ぶ(2/2)まとめ
・2次元画像から3次元形状を理解する手法は複数視点のデータに依存している
・1枚の画像から3次元構造を知ることができると便利だが解決困難とされている
・LOLNeRFは単一視点画像の集まりから3D構造と外観を学習するフレームワーク
2.LOLNeRFとは?
以下、ai.googleblog.comより「LOLNeRF: Learn from One Look」の意訳です。元記事の投稿は2022年9月13日、Daniel RebainさんとMark Matthewsさんによる投稿です。
アイキャッチ画像はstable diffusion
カメラ推定
NeRFが動作するためには、各画像の被写体に対する正確なカメラ位置を知る必要があります。撮影時に測定したものでない限り、一般的には不明です。
そこで、MediaPipe Face Meshを使って、画像から5つのランドマーク位置を抽出します。これらの2次元予測はそれぞれ、対象物上の意味的に一貫した点(例えば、鼻先や目尻)に対応しています。
これにより、各画像のカメラポーズの推定値とともに、鼻先や目じりなどの正規の3次元位置セットを導出することができ、このような位置セットの2次元画像への投影がランドマークと可能な限り一致するようにします。
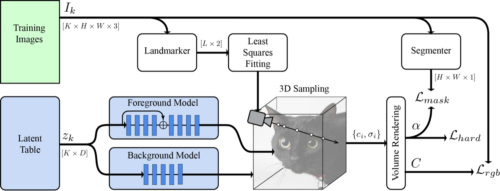
NeRFモデルと並行して、画像毎の潜在コードのテーブルを学習します。出力は、視線毎のRGB、マスク、硬度損失の対象となります。カメラは、予測されたランドマークと標準的な3Dキーポイントを適合させて導き出されます。

MediaPipe ランドマークとセグメンテーション マスクのサンプル(CelebAの画像)
固体表面損失とマスク損失
標準的なNeRFは画像を正確に再現するのに有効ですが、単一視点の場合、軸から外れた位置で見たときに画像がぼやけて見える傾向があります。そこで、固体表面損失(hard surface loss)という新しい損失を導入し、外部領域から内部領域へシャープな遷移を行うよう密に働きかけ、ぼやけを低減させました。これにより、雲のような半透明の表面ではなく、「固体(solid)」の表面を作るようにネットワークに指示します。
また、前景と背景のネットワークに分割することで、より良い結果を得ることができました。この分離は、MediaPipe Selfie Segmenterのマスクと、ネットワークの専門家を促進する損失を用いて教師しました。これにより、前景ネットワークは、関心のある物体のみに特化し、背景に「気を取られる」ことなく、その品質を向上させることができます。
結果
5つのキーポイントを適合させるだけで、猫、犬、人間の顔のモデルを学習するのに十分な精度のカメラ推定値が得られるという驚くべき結果が得られました。つまり、愛猫SchnitzelやWidget、その仲間たちを1枚の写真に収めれば、他の角度からの新しい画像を作成することができるのです。

上:AFHQの猫画像サンプル
下:LOLNeRFで作成された新規3D視点の合成
まとめ
2次元画像から3次元構造を発見する技術を開発しまし。LOLNeRFは様々な用途に応用できる可能性があり、現在その可能性を調査しているところです。

AFHQの異なるサンプルに対する学習済み潜在コードの線形補間により猫の同一性を推定します。
コードの公開
私達は、悪用される可能性と責任を持って行動することの重要性を認識しています。そのため、再現性のためにのみコードを公開し、学習済みの生成モデルは一切公開しない予定です。
謝辞
Andrea Tagliasacchi, Kwang Moo Yi, Viral Carpenter, David Fleet, Danica Matthews, Florian Schroff, Hartwig Adam そして Dmitry Lagunにこの技術の構築において継続的に協力していただいたことに感謝します。
3.LOLNeRF:1枚の画像から3次元構造を学ぶ(2/2)関連リンク
1)ai.googleblog.com
LOLNeRF: Learn from One Look
2)ubc-vision.github.io
LOLNeRF: Learn from One Look

