
1.PaLM-SayCan:飲み物をこぼしてしまったからちょっと助けて!とロボットに頼めるようになる(2/2)まとめ
・ポリシーの学習には10台のロボットで11ヶ月間収集したデモデータ+αを使用
・更にシミュレーションでオンラインデータを収集しRLの性能を継続的に向上
・PaLM-SayCanで言語モデルの力を借りてロボットが曖昧な指示を実行できた
2.PaLM-SayCanの性能
以下、ai.googleblog.comより「Towards Helpful Robots: Grounding Language in Robotic Affordances」の意訳です。元記事は2022年8月16日、Brian IchterさんとKarol Hausmanさんによる投稿です。
アイキャッチ画像はDALL·E 2による画像生成
学習ポリシーと価値関数
エージェントのスキルセットの各スキルは、言語を使った短い記述(例えば、「缶を拾う」)と、ロボットの現在の状態からそのスキルを完了する確率を示すアフォーダンス関数からなるポリシーとして定義されます。アフォーダンス関数の学習には、成功した場合に1.0、そうでない場合に0.0とする疎な報酬関数を用います。
言語条件付きポリシーの学習には画像に基づく行動クローニング(BC:Behavioral Cloning)、価値関数の学習には時間差に基づく(TD:Temporal-Difference-based)強化学習(RL:Reinforcement Learning)を用いています。
ポリシーの学習には、10台のロボットが11ヶ月間に行った68,000件のデモのデータを収集し、学習済みのポリシーによる自律エピソードでフィルタリングした12,000件の成功エピソードを追加しました。
その後、Everyday RobotsのシミュレータでMT-Optを用いて言語条件付き価値関数を学習しました。このシミュレータは、実ロボット群をシミュレーション版のスキルや環境で補完し、RetinaGANを用いて変換することで、シミュレーションとリアルのギャップを少なくしています。私達は、デモを利用してシミュレーションポリシーの性能をブートストラップし、最初の成功をもたらし、その後、シミュレーションのオンラインデータ収集によりRLの性能を継続的に向上させました。
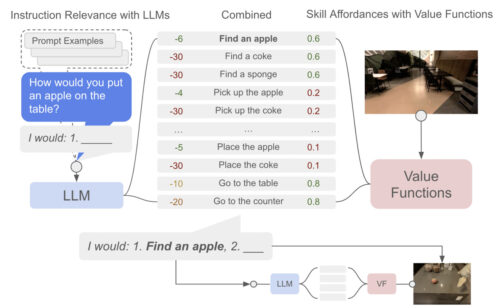
高レベルな指示が与えられると、言語モデルによる確率と価値関数(VF:Value Function)による確率を組み合わせて、次に実行すべきスキルを選択します。このプロセスは、高レベルの指示が正常に完了するまで繰り返されます。
時間的に広範囲にわたり、複雑かつ抽象的な指示に対する性能
私達の手法をテストするために、Everyday RobotsチームのロボットとPaLMを組み合わせて使用しました。ロボットを一般的な物が置かれた台所環境に置き、101の命令に対してロボットを評価し、様々なロボットと環境の状態、命令時の言語の複雑さ、時間軸に対する性能を検証しました。
特に、これらの命令は単純で命令的な問い合わせではなく、言語の曖昧さや複雑さを示すように設計されており、「水とリンゴを持ってきてくれる?」ではなく、「運動したばかりなので、疲労回復のためにおやつと飲み物を持ってきてくれない?」といった問い合わせが可能になっています。
システムの性能評価には、ロボットが命令に対して正しいスキルを選択したかどうかを示す「計画成功率」と、命令を正常に実行したかどうかを示す「実行成功率」の2つの指標を使用します。
PaLMとFLAN(指示に応答するタスクに関して微調整された小型の言語モデル)の2つの言語モデルを、アフォーダンスに基づいているか否か?、および自然言語を直接実行する基本ポリシー(下表の行動クローニング)と比較しました。
その結果、アフォーダンスに基づくPaLMを用いたシステム(PaLM-SayCan)は、84%の確率で正しいスキルの実行順番を選択し、74%の確率でスキルを正常に実行し、FLANに比べて、またロボット操作に基づかない素のPaLMに比べて、エラーを50%減少させることがわかりました。
これは、言語モデルの改良がロボット工学の改良につながることを初めて示したものであり、特にエキサイティングなことです。この結果は、言語モデルの進歩の波にロボット工学が乗ることで、両分野の研究がより密接に連携するようになる可能性を示しています。
| Algorithm | Plan | Execute |
| PaLM-SayCan | 84% | 74% |
| PaLM | 67% | – |
| FLAN-SayCan | 70% | 61% |
| FLAN | 38% | – |
| Behavioral Cloning | 0% | 0% |
PaLM-SayCanは、アフォーダンスなしのPaLMやFLANと比較して、101のタスクで、エラーを半減させました。

SayCanは、PaLMと組み合わせることで、101のテスト命令のうち84%の計画を成功させることができました。
このプロジェクトに関わった研究者達から詳しい話を聞きたい方は、以下のビデオをご覧ください。
まとめと今後の課題
PaLM-SayCanは、言語モデルからの知識を活用する解釈可能で汎用的な手法で、ロボットが高レベルのテキスト命令に従って物理的に根拠のあるタスクを実行できるようにするもので、私たちはその進歩に興奮しています。
実世界の多くのロボットタスクに関する私達の実験では、長期的かつ抽象的な自然言語の指示を計画し、高い成功率で完了できることを実証しています。
私達は、PaLM-SayCanの解釈可能性により、実世界のユーザーとロボットとの安全な対話が可能になると考えています。今後、ロボットの実体験から得られる情報を言語モデルの改良にどのように活用できるか、また、自然言語がロボットのプログラミングにどの程度適しているのかを理解することで、この研究の今後の方向性を探っていきたいと考えています。
私たちは、ロボットシミュレーションのセットアップをオープンソース化しました。これは、ロボット学習と高度な言語モデルを組み合わせた今後の研究のための貴重なリソースを研究者に提供することを期待しています。研究者コミュニティは、このプロジェクトのGitHubページとウェブサイトをご覧ください。
謝辞
共著者の Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Kelly Fu, Keerthana Gopalakrishnan, Alex Herzog, Daniel Ho, Jasmine Hsu, Julian Ibarz, Alex Irpan, Eric Jang, Rosario Jauregui Ruano, Kyle Jeffrey, Sally Jesmonth, Nikhil J Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang, Kuang-Huei Lee, Sergey Levine, Yao Lu, Linda Luu, Carolina Parada, Peter Pastor, Jornell Quiambao, Kanishka Rao, Jarek Rettinghouse, Diego Reyes, Pierre Sermanet, Nicolas Sievers, Clayton Tan, Alexander Toshev, Vincent Vanhoucke, Fei Xia, Ted Xiao, Peng Xu, Sichun Xu, Mengyuan Yan, そして Andy Zengに感謝の意を表したいと思います。
また、Yunfei Bai, Matt Bennice, Maarten Bosma, Justin Boyd, Bill Byrne, Kendra Byrne, Noah Constant, Pete Florence, Laura Graesser, Rico Jonschkowski, Daniel Kappler, Hugo Larochelle, Benjamin Lee, Adrian Li, Suraj Nair, Krista Reymann, Jeff Seto, Dhruv Shah, Ian Storz, Razvan Surdulescu 及び Vincent Zhaoにはプロジェクトの色々な面で協力と支援を受けてきましたので、お礼を申し上げたいと思います。また、この記事の多くのアニメーションを制作してくれたTom Smallに感謝します。
3.PaLM-SayCan:飲み物をこぼしてしまったからちょっと助けて!とロボットに頼めるようになる(2/2)関連リンク
1)ai.googleblog.com
Towards Helpful Robots: Grounding Language in Robotic Affordances
2)arxiv.org
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
3)github.com
google-research/saycan/

