
1.MLGO:強化学習を使ってコンパイラの最適化処理を最適化(1/2)まとめ
・コンパイラのコードの最適化はデータセンターやスマホアプリの運用コストを削減可能
・コンパイラの進歩は続いているが最適化に関する複雑な経験則が改良の妨げになっている
・MLGOは産業用コンパイラ基盤であるLLVMに機械学習を統合する汎用フレームワーク
2.MLGOとは?
以下、ai.googleblog.comより「MLGO: A Machine Learning Framework for Compiler Optimization」の意訳です。元記事は2022年7月6日、Yundi QianさんとMircea Trofinさんによる投稿です。
アイキャッチ画像は適切な画像が思い浮かばずに苦し紛れにlatent diffusionにMLGOとだけプロンプトに入れて丸投げして出力された画像。思いもよらぬ画像で困惑したのですが、Googleで類似画像検索をしたところ「マイリトルポニー」がサジェストされたので、確かにそれっぽいですが、おそらく「GO」の部分から「Pokemon Go」の影響を受けて、そこからカラフルな空想上の生物繋がりで生成された画像のような気もします。右下とかロゴにそのまま使えちゃいそうですね。
より速く、より小さなコードにコンパイルするにはどうしたらよいかという問題は、モデムの誕生とともに生まれました。
コードの最適化がうまくいけば、大規模なデータセンター・アプリケーションの運用コストを大幅に削減することができます。コンパイルされたコードのサイズは、コンパイルされたバイナリが制限の厳しいコードサイズ枠に収まる必要があるモバイルおよび組み込みシステム、またはセキュアブートパーティションに展開されるソフトウェアに最も重要です。この分野の進歩に伴い、ますます複雑になる経験則によって空き容量は大きく圧迫され、メンテナンスやさらなる改良の妨げになっています。
最近の研究では、機械学習(ML:Machine Learning)が複雑な経験則をMLポリシーに置き換えることで、コンパイラの最適化におけるより多くの機会を解放できることが示されています。しかし、業界標準の汎用コンパイラにMLを導入することは、依然として困難です。
この問題を解決するため「MLGO: a Machine Learning Guided Compiler Optimizations Framework」(以下、「MLGO」)を紹介します。MLGOは、LLVM(ミッションクリティカルで高性能なソフトウェアを構築するためにユビキタスなオープンソースの産業用コンパイラ基盤)にML技術を体系的に統合するための、初の産業用汎用フレームワークです。
MLGOは、強化学習(RL:Reinforcement Learning)を用いてニューラルネットワークを学習させ、LLVMの経験則を置き換える判断を行えるようにします。
(1)インライン化によるコードサイズの縮小
(2)レジスタ割り当て(regalloc)によるコード性能の向上
です。どちらの最適化もLLVMリポジトリで利用可能であり、実運用に導入されています。
MLGOはどのように機能するか?Inlining-for-Sizeのケーススタディ
インライン化は、冗長なコードを削除できるように判断することで、コードサイズを縮小するのに役立ちます。以下の例では、呼び出し側の関数foo()が呼び出される側の関数bar()を呼び出し、bar自身がbaz()を呼び出しています。両方の呼び出し元をインライン化すると、シンプルなfoo()関数が返され、コードサイズが縮小されます。
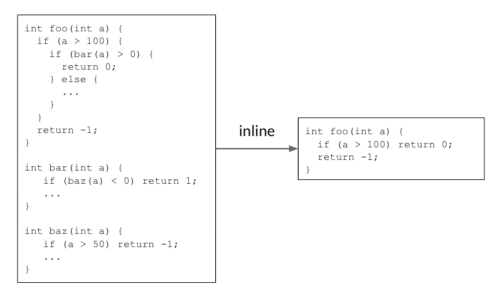
インライン化は、冗長なコードを削除することでコードサイズを縮小します。
現実のコードでは、何千もの関数が互いに呼び合っており、呼び出しグラフを構成しています。インライン化の段階では、コンパイラは呼び出し側と呼び出される側のすべてのペアについて呼び出しグラフを端から端まで調べて、呼び出し側と呼び出される側のペアをインライン化するかどうかを決定します。
先に行われたインライン化の決定が呼び出しグラフを変更し、後の決定と最終結果に影響を与えるため、これは順次決定プロセスです。上の例では、コードサイズ削減を実現するために、呼び出しグラフ foo() → bar() → baz() は、両方のエッジで「yes」の判定をする必要があります。
MLGO以前は、インラインかノーインラインかの判断は経験則によって判断されていましたが、時間の経過とともに、その改善は難しくなってきていました。MLGOは、経験則をMLモデルで置き換えます。
呼び出しグラフの探索中に、コンパイラは、グラフから関連する特徴(すなわち入力)を与えることで、特定の呼び出し側と受け手側のペアをインライン化するかどうかについてニューラルネットワークに助言を求めます。呼び出しグラフ全体が探索されるまでその決定を逐次実行します。
インライン化中のMLGOの説明図
「#bbs」, 「#users」, 「callsite height」は、呼び出し側と呼び出される側の特徴量の例です。
MLGOは、ポリシー勾配と進化戦略アルゴリズムを用いて、RLで意思決定ネットワーク(ポリシー)を学習します。最良の決定か否かを判断するための真の情報は存在しませんが、オンラインRLは学習と学習済みポリシーによるコンパイルの実行を繰り返し、データを収集し、ポリシーを改善します。
特に、学習中の現在のモデルが与えられると、コンパイラはインライン化の段階でインライン化/非インライン化の決定を行うためにモデルを参照します。コンパイルが終了すると、逐次意思決定プロセス(状態、行動、報酬)のログが生成されます。このログは学習者に渡され、モデルを更新します。このプロセスは、満足のいくモデルが得られるまで繰り返されます。
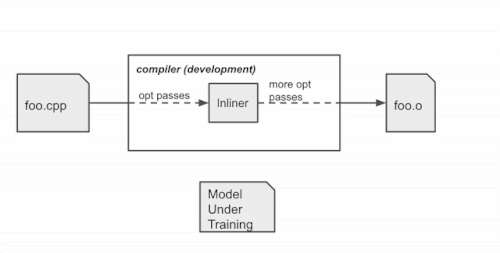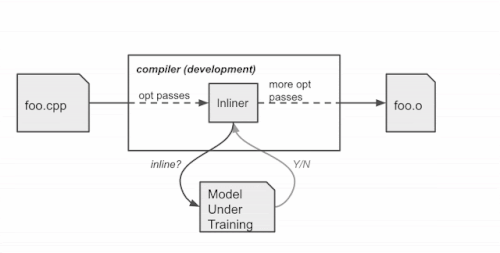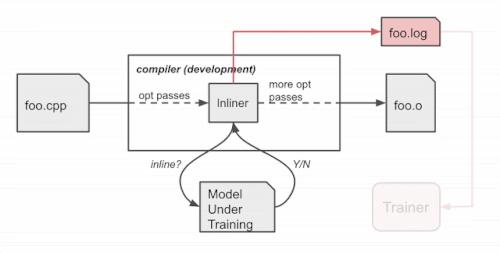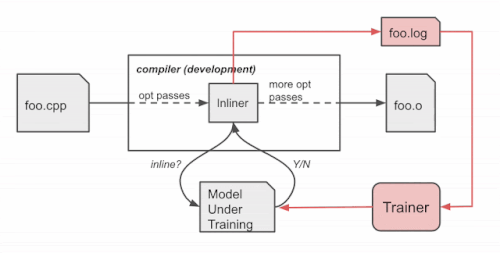
学習時のコンパイラの動作
コンパイラは、ソースコードfoo.cppを一連の最適化パス(そのうちの1つはインラインパス)を用いてオブジェクトファイルfoo.oにコンパイルします。
学習済ポリシーはコンパイラに組み込まれ、コンパイル時にインライン/ノーインラインの判定を行います。トレーニングシナリオとは異なり、ポリシーはログを生成しません。TensorFlowモデルをXLA AOTで埋め込み、モデルを実行可能なコードに変換します。これにより、TensorFlowの実行時依存とオーバーヘッドを回避し、コンパイル時にMLモデルの推論によってもたらされる余分な時間とメモリコストを最小化します。
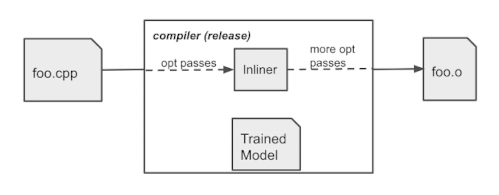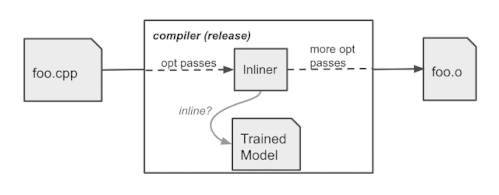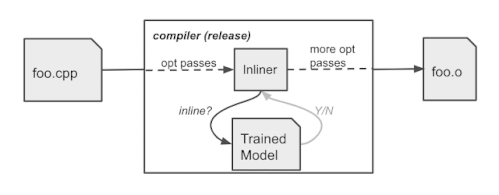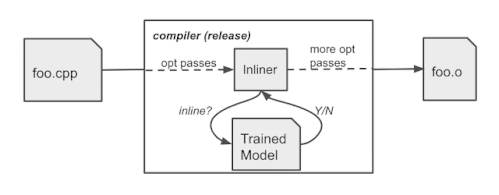
実稼働時のコンパイラの動作
3万モジュールを含む大規模な社内ソフトウェアパッケージに対して、サイズに応じたインライン化ポリシーの学習を行いました。学習済ポリシーは、他のソフトウェアのコンパイルに適用しても一般化され、3%~7%のサイズ削減を達成しました。
ソフトウェア間の汎化性に加えて、時間経過に関する汎化性も重要です。ソフトウェアとコンパイラの両方が活発に開発されているため、学習済ポリシーは適切な期間、良好な性能を維持する必要があります。3ヶ月後に同じソフトウェアのセットでモデルの性能を評価したところ、わずかな劣化しか認められませんでした。
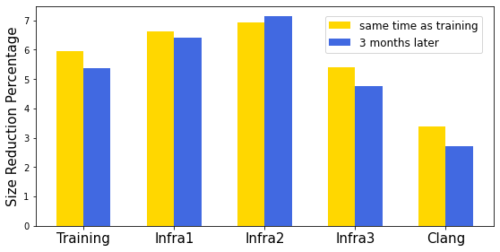
Inlining-for-sizeポリシーのサイズ削減率
X軸は異なるソフトウェアを示し、Y軸はサイズ削減のパーセンテージを表しています。「Training」はモデルを学習させたソフトウェア、「Infra[1|2|3]」は異なる内部ソフトウェアパッケージです。
3.MLGO:強化学習を使ってコンパイラの最適化処理を最適化(1/2)関連リンク
1)ai.googleblog.com
MLGO: A Machine Learning Framework for Compiler Optimization
2)arxiv.org
MLGO: a Machine Learning Guided Compiler Optimizations Framework
3)github.com
google / ml-compiler-opt

