
1.観測困難な量子状態をそのままデータとして扱える量子機械学習の優位性(2/2)まとめ
・従来は原子やその他の量子オブジェクトを使って量子状態を測定してデータとした
・QMLでは、量子状態を測定するのではなく、量子状態を保存する事が可能になる
・従来では量子ビットの数に応じて指数関数的に規模が増えるがQMLは線形に抑える事が可能
2.量子機械学習のアルゴリズム
以下、ai.googleblog.comより「Quantum Advantage in Learning from Experiments」の意訳です。元記事は2022年6月22日、Jarrod McCleanさんとHsin-Yuan Huangさんによる投稿です。
アイキャッチ画像はlatent diffusionによる生成
量子機械学習(QML:Quantum Machine Learning)アルゴリズムがどのように機能するかを確認するには、標準的な量子実験と対比すると便利です。
科学者が量子システムについて知りたい場合、対象のシステムに敏感な状態の原子やその他の量子オブジェクトなどを量子探索機として送信し、システムと相互作用させてから、探索機を測定します。その後、新しい実験を設計したり、測定結果に基づいて予測を行ったりすることができます。従来の機械学習アルゴリズムは、MLモデルを使用して同じプロセスに従いますが、動作原理は同じです。これは、従来の情報を処理する従来のデバイスです。
QMLアルゴリズムは、代わりに人工的な「量子学習者(quantum learner)」を使用します。 量子学習者は、システムと対話するために探索機を送信した後、量子状態を測定するのではなく、量子状態を保存することを選択できます。 ここにQMLの力があります。 これらの量子探索機の複数のコピーを収集し、それらを絡ませてシステムについてより速く学習することができます。
たとえば、対象のシステムが、可能な状態の分布からサンプリングすることにより、確率的に量子重ね合わせ状態を生成するとします。 各状態はn個の量子ビットで構成され、それぞれが「0」と「1」の重ね合わせです。すべての学習者は状態の一般的な形式を知ることができますが、その詳細を学習する必要があります。
従来のデータのみにアクセスできる標準的な実験では、すべての測定で量子状態の分布のスナップショットが提供されますが、これはサンプルにすぎないため、状態のコピーを多数測定して再構築する必要があります。 実際には、\(2^n\)コピーの規模になります。
QMLエージェントはより賢いです。 n量子ビット状態のコピーを保存し、次に来るコピーと絡ませることで、グローバル量子状態についてより迅速に学習し、状態がより早くどのように見えるかをよりよく理解できます。
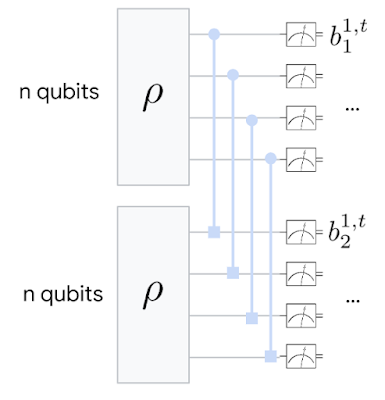
QMLアルゴリズムの基本的な概略図。 量子状態の2つのコピーが保存され、次に「ベル測定」が実行されます。ここで、各ペアが絡み合い、それらの相関が測定されます。
古典的な再構成は、ノイズ混じりの画素の海に隠れている画像を見つけようとするようなものです。画像が何を表しているかを知るために、すべてのノイズを平均化するのに非常に長い時間がかかる可能性があります。 一方、量子再構成では、量子力学を使用して、2つの異なる画像間の相関関係を一度に探すことにより、真の画像をより速く分離します。
結果
QMLの能力をよりよく理解するために、最初に3つの異なる学習タスクを調べ、それぞれの場合において、量子学習エージェントが従来の学習エージェントよりも指数関数的に優れていることを理論的に証明しました。各タスクは、上記の例に関連していました。
(1)量子状態の互換性のない観測可能物、つまり、位置や運動量などのハイゼンベルグの不確実性の原理のために任意の精度で同時に知ることができない観測可能物について学習します。 しかし、状態の複数のコピーを絡ませることで、この制限を克服できることを示しました。
(2)量子状態の主要なコンポーネントについて学習します。ノイズが存在する場合、量子状態を乱す可能性があります。ただし、通常、「主要コンポーネント」(最も確率の高い重ね合わせの部分)はこのノイズに対して堅牢であるため、この主要部分を見つけることで、元の状態に関する情報を収集できます。
(3)量子システムまたはプローブに作用する物理プロセスについて学習します。 状態自体が対象ではない場合もありますが、この状態を進化させる物理的なプロセスは対象です。 時間の経過に伴う状態の変化を分析することにより、さまざまな分野と相互作用について学ぶことができます。
理論的な作業に加えて、Sycamore量子プロセッサでいくつかの原理証明実験を実行しました。 最初のタスクを実行するためにQMLアルゴリズムを実装することから始めました。 未知の量子混合状態をアルゴリズムに供給し、次に、2つの観測可能な状態のどちらが大きいかを尋ねました。 シミュレーションデータを使用してニューラルネットワークをトレーニングした後、量子学習エージェントが70%の予測精度に到達するために必要な実験が指数関数的に少なくなることがわかりました。これは、システムサイズが20量子ビットの場合の測定値の10,000分の1に相当します。 一度に2つのコピーが保存されたため、使用された量子ビットの総数は40でした。
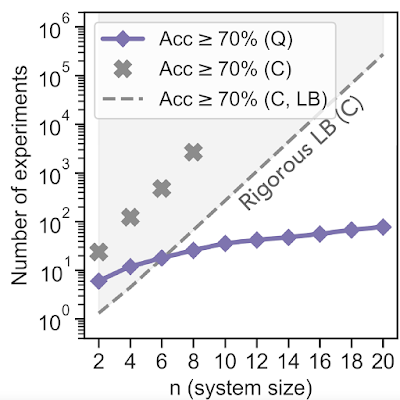
量子状態の観測可能値を予測するためのQMLアルゴリズムとCMLアルゴリズムの実験的比較。 CMLアルゴリズム(上記の「C」)で70%の精度を達成するために必要な実験の数は、量子状態nのサイズとともに指数関数的に増加しますが、QMLアルゴリズム(「Q」)が必要とする実験の数は、nで線形です。「厳密なLB(C)」というラベルの付いた破線は、従来の機械学習アルゴリズムの理論上の下限(LB)(可能な限り最高のパフォーマンス)を表しています。
上記のタスク3に関連する2番目の実験では、量子ビットの量子状態を進化させる演算子の対称性についてアルゴリズムに学習させました。特に、量子状態が完全にランダムまたはランダムであるが時間反転対称である進化を遂げる可能性がある場合、古典的な学習者が違いを区別するのは難しい場合があります。
このタスクでは、QMLアルゴリズムは、演算子を2つの異なるカテゴリに分類し、2つの異なる対称クラスを表しますが、CMLアルゴリズムは完全に失敗します。QMLアルゴリズムは完全に教師なし学習であったため、これにより、事前に正しい答えを知る必要なしに、このアプローチを使用して新しい現象を発見できる可能性があります。
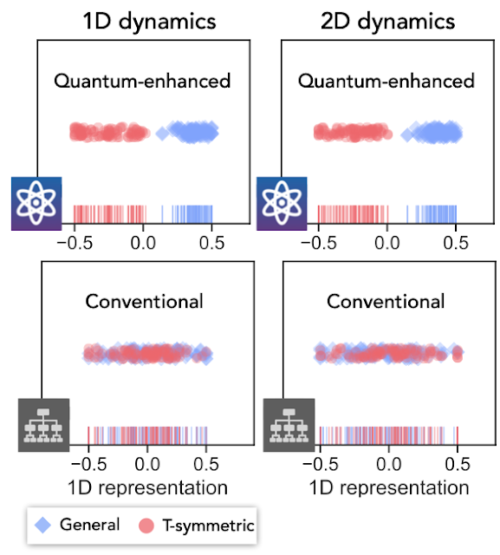
演算子の対称性クラスを予測するためのQMLアルゴリズムとCMLアルゴリズムの実験的比較。 QMLは2つの対称クラスを正常に分離しますが、CMLはタスクを実行できません。
結論
この実験的研究は、量子機械学習において最初に実証された指数関数的な利点を表しています。そして、計算上の利点とは異なり、量子状態からのサンプル数を制限する場合、無制限に使える古典的な計算リソースがあったとしても、このタイプの量子学習の利点に挑戦することはできません。
これまでのところ、この手法は、量子状態が意図的に生成され、研究者がそれが何であるかを知らないふりをする、考案された「原理の証明」実験でのみ使用されてきました。これらの手法を使用して実際の実験で量子増強測定を行うには、まず、量子状態を量子コンピューターに忠実に転送するための現在の量子センサー技術と手法に取り組む必要があります。しかし、今日の量子コンピューターがすでにこの情報を処理して、学習における指数関数的な利点を絞り出すことができるという事実は、量子機械学習の将来にとって良い前兆です。
謝辞
このブログ投稿を作成してくれたQuantum Science CommunicatorのKatherine McCormickに感謝します。Huangらの許可を得て転載した画像。Science, Vol 376:1182 (2022).
3.観測困難な量子状態をそのままデータとして扱える量子機械学習の優位性(2/2)関連リンク
1)ai.googleblog.com
Quantum Advantage in Learning from Experiments
2)arxiv.org
Quantum advantage in learning from experiments

