
1.観測困難な量子状態をそのままデータとして扱える量子機械学習の優位性(1/2)まとめ
・量子の観測の困難さはよく知られており、実体が波なのか粒なのかも判明しないほど
・量子に関する実験は量子状態の観測が必要になるため機械学習でもデータ収集が困難
・しかし、量子コンピュータならば量子状態を観測せずともデータとして扱う事が可能
2.量子状態の観測の難しさ
以下、ai.googleblog.comより「Quantum Advantage in Learning from Experiments」の意訳です。元記事は2022年6月22日、Jarrod McCleanさんとHsin-Yuan Huangさんによる投稿です。
高校物理の教科書などにも出てきますが、量子は非常に観測する事が難しく、その実体が「粒」なのか「波」なのかも未だにわかってません。
観測方法に応じて、波動っぽい挙動を示したり、粒子っぽい挙動を示したりするので、あたかも自分が観測されている事を意識して挙動を変えているように見える怪奇現象が知られています。
でもよく考えれば、量子コンピュータって、同じ量子を扱ってるんだから観測する必要なくない?量子状態をコピーすれば量子機械学習用のデータとしてそのまま使えるっしょ?みたいなものすごい発想の転換のお話です。
更に、今回のお話はGoogleが量子超越性を達成したと発表した際にIBMが物言いをつけた経緯を知っていると理解が深まります。
量子超越性、つまり、私達が普段使っているようなコンピューター(古典的コンピューター)では、解く事が不可能なほど複雑な問題でも、量子コンピューターを使えば解けるという概念です。
2019年にGoogleが「世界最速のスーパーコンピューターで10,000年かかる計算を量子コンピュータでは200秒で計算出来ました!」と発表したところ、IBMがその計算はアルゴリズムを工夫すれば古典的コンピューターでも3日で解けるからそれは量子超越性の達成とは言えない、と指摘された経緯です。
アイキャッチ画像はlatent diffusionによる生成で左側は「Google社内で行われている秘密の量子コンピュータ実験をエジプトの壁画風に描いたも」ので、右側は「サイバー空間で量子コンピュータが複雑な計算をしているところを眺めている牛」
量子世界について学ぶ際、科学者達は大きな障害に直面します。
それは量子世界を古典的な世界で体験しなければならないことです。
量子システムが測定されるとき、「観測する」という行為が量子状態の「量子性(quantumness)」を破壊します。
たとえば、量子状態が2つの場所で重ね合わせ(superposition)にあり、同時に2つの場所にあるように見える場合、観測すると、「ここ」または「そこ」のいずれかにランダムに表示されますが、両方は表示されません。私たちは、この奇妙な量子世界を古典的世界に投影した影だけを見ています。
ますます多くの実験がデータの分析を支援するために機械学習(ML:Machine Learning)アルゴリズムを実装していますが、これらにはその支援対象である人々と同じ制限があります。つまり、量子情報に直接アクセスして学習することができません。
しかし、この量子データと直接相互作用できる量子機械学習アルゴリズムがあったとしたらどうでしょうか?
Science誌に掲載されたCaltech、Harvard、Berkeley、およびMicrosoftの研究者とのコラボレーションである論文「Quantum Advantage in Learning from Experiments」では、量子学習エージェントが多くのタスクで従来の学習エージェントよりも指数関数的に優れていることを示しています。
Googleの量子コンピューターであるSycamoreを使用して、量子機械学習(QML:Quantum Machine Learning)アルゴリズムが可能な限り最高の古典的なアルゴリズムよりも優れていることを示します。
以前の量子アドバンテージのデモンストレーションとは異なり、従来のコンピューティング能力の進歩ではこのギャップを克服できませんでした。 これは、現在のノイズの多いハードウェアを使っていても、堅牢な量子システムで学習させる際は、古典的コンピュータより指数関数的利点を持っている事を証明可能な最初のデモンストレーションです。
量子スピードアップ
QMLは、量子コンピューティングとあまり知られていない量子センシングの分野の両方の長所を兼ね備えています。
量子コンピューターは、特定の問題に対して従来のシステムに比べて指数関数的な改善を提供する可能性がありますが、その可能性を実現するには、研究者はまず量子ビットの数をスケールアップし、量子エラー補正を改善する必要があります。
さらに、量子コンピューターによって約束された古典的なアルゴリズムに対する指数関数的なスピードアップは、問題のいわゆる「複雑さのクラス(complexity classes)」についての大きな、証明されていない仮定に依存しています。
つまり、量子コンピューターで解決できる問題のクラスは、古典的なコンピューターで解決できるものよりもより大きいということです…
それは合理的な仮定のように思えますが、それでも誰もそれを証明していません。 それが証明されるまで、量子の利点のすべての主張には※が付く事になります。
「※この量子アルゴリズムは既知の古典的なアルゴリズムよりもうまくいくことができます。」
一方、量子センサー(Quantum sensors)は、すでにいくつかの高精度測定に使用されており、従来のセンサーに比べて適度な(そして実証済みの)利点を提供します。
一部の量子センサーは、粒子間の量子相関を利用して、システムに関するより多くの情報を抽出することで機能します。たとえば、科学者はN個の原子のコレクションを使用して、周囲の磁場などの原子の環境の側面を測定できます。通常、原子が測定できるフィールドに対する感度は、Nの平方根でスケールします。しかし、量子もつれ(Quantum entanglement)を使用して原子間の相関の複雑なウェブを作成する場合、スケーリングをNに比例するように改善できます。ほとんどの量子センシングプロトコルでは、従来のセンサーを超えるこの2次高速化は、これまでで最高の速度です。
量子コンピューターと量子センサーの間の境界線にまたがるテクノロジーであるQMLの世界に入りましょう。 QMLアルゴリズムは、量子データを利用した計算を行います。 量子コンピューターは、量子状態を測定する代わりに、量子データを格納し、QMLアルゴリズムを実装して、データを折りたたむことなく処理できます。 また、このデータが限られている場合、QMLアルゴリズムは、特定のタスクを検討するときに、受け取る各ピースから指数関数的に多くの情報を絞り出すことができます。
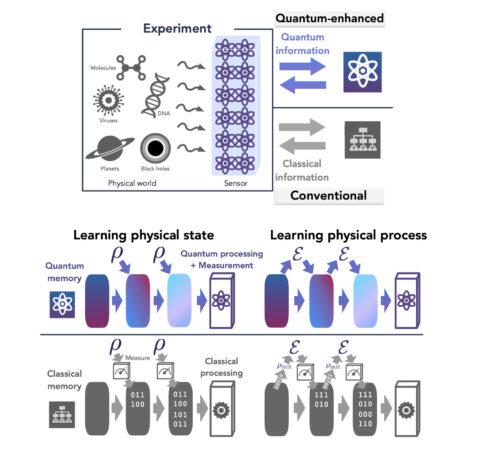
古典的な機械学習(CML:Classical Machine Learning)アルゴリズムと量子機械学習(QML:Quantum Machine Learning)アルゴリズムの比較
古典的な機械学習アルゴリズムは、量子システムを測定し、システムについて学習するために取得した古典的なデータに対して古典的な計算を実行します。一方、量子マシン学習アルゴリズムは、システムによって生成された量子状態と直接相互作用するため、CMLよりも量子的に有利です。
3.観測困難な量子状態をそのままデータとして扱える量子機械学習の優位性(1/2)関連リンク
1)ai.googleblog.com
Quantum Advantage in Learning from Experiments
2)arxiv.org
Quantum advantage in learning from experiments

