
1.Auto Arborist Dataset:都市部に存在する樹木の分布を調査(1/2)まとめ
・都市部の樹木は人々の健康と福祉に貢献し、都市の気候変動への適応に不可欠であり重要
・多くの都市ではコストがかかるので樹木の位置や種類に関する基本的なデータがさ不足
・機械学習により街路写真と航空写真を組み合わせて樹木の国勢調査のコストを劇的に削減
2.Auto Arborist Datasetとは?
以下、ai.googleblog.comより「Mapping Urban Trees Across North America with the Auto Arborist Dataset」の意訳です。元記事は2022年6月22日、Sara BeeryさんとJonathan Huangさんによる投稿です。
アイキャッチ画像はlatent diffusionによる生成でドクターが樹木を診察している感じにしたかったのですが、ドクターが樹木と一体化している画像などが出きてしまってますね。
40 億人以上の人々が世界中の都市に住んでいます。ほとんどの人は、食料品店、公共交通機関、職場など、毎日、他の人と触れ合いますが、都市の脆弱な生態系を構成する多様な植物や動物と頻繁に触れ合うことは、当然のことだと考えているかもしれません。
都市の森(urban forests)と呼ばれる都市部の樹木は、人々の健康と福祉に重要な恩恵をもたらし、都市の気候変動への適応に不可欠であることを証明しています。木は空気と水をろ過し、雨水の流出を防ぎ、大気中の二酸化炭素を吸収し、浸食と干ばつを抑えます。
都市の木陰は、エネルギーコストのかかる冷房費を削減し、都市のヒートアイランド現象を緩和します。米国だけでも、都市の森林は1億2700万エーカーを占め、180億ドル相当の生態系サービスを生み出しています。しかし、気候の変動に伴い、これらの生態系はますます脅威にさらされています。
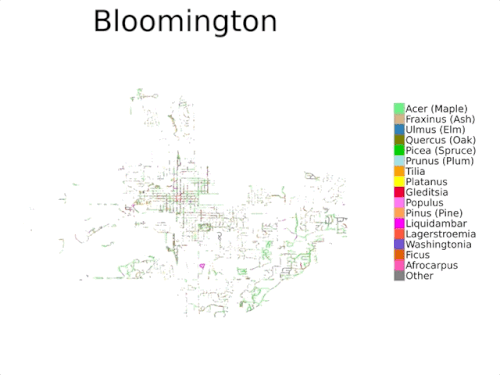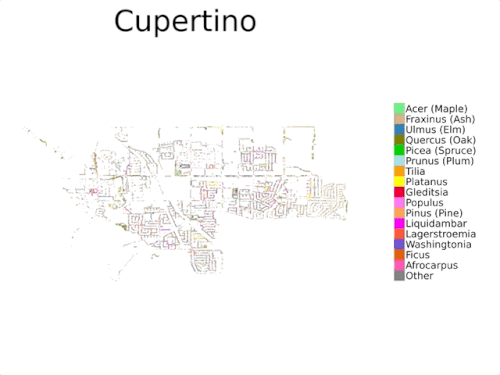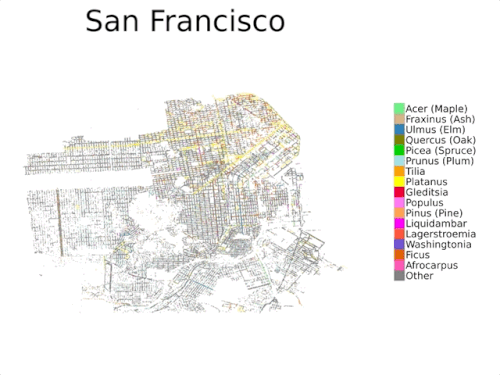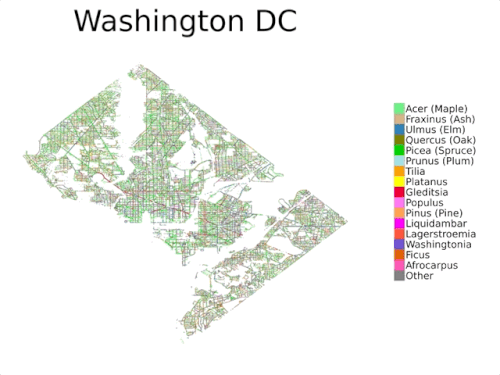
国勢調査のデータは通常、公共の樹木の一部を対象としており、公園内の樹木は含まれていないため、包括的なものではありません
都市の森林モニタリング(都市の樹木のサイズ、健康状態、樹種の分布を長期的に測定)により、研究者や政策立案者は、(1)大気質の改善、炭素隔離、公衆衛生への恩恵などの生態系サービスの定量化、(2)異常気象による被害の追跡、(3)気候変動、病気、侵入に対する堅牢性を高めるための植栽目標、などを実現することができます。
しかし、多くの都市では、樹木の位置や種類に関する基本的なデータさえ不足しています。このようなデータを樹木を対象とした国勢調査で収集するにはコストがかかるため(最近のロサンゼルスの調査は200万ドルと18ヶ月を要しました)、通常、相当の資源を持つ都市のみが実施しています。
更に、都市の緑地を利用できないことは、社会経済的不平等や人種的不平等など、都市の社会的不平等の重要な側面です。都市部の森林モニタリングによって、この不平等を定量化し、その改善を追求することができます。
しかし、機械学習により、街路樹と航空写真を組み合わせることで、樹木の国勢調査のコストを劇的に削減することができます。このような自動化されたシステムは、都市部の森林モニタリングへのアクセスを民主化することができ、特に、気候変動によってすでに不相応な影響を受けている資源不足の都市にとっては有効です。航空写真や街路樹画像から都市の樹木の種を自動認識する研究は以前から行われているが、大規模なラベル付きデータセットがないことが大きな制約になっています。
本日、複数視点を持つ都市樹木分類データセット「自動樹医データセット(Auto Arborist Dataset)」を紹介します。このデータセットは、約260万本の樹木と320以上の属からなり、先行研究よりも2桁以上大きなデータセットです。このデータセットを構築するために、北米の23都市から樹木の記録を収集し(上図)、これらの記録をストリートビューおよびオーバーヘッドRGB画像と統合しました。
複数の都市をカバーする初の都市森林データセットとして、森林モデルが地理的な分布の変化に対してどのように一般化できるかを詳細に分析し、スケールアップしたシステムを構築するために重要な情報を提供しています。現在、260万本の樹木の記録と、100万本の航空写真および地上写真が公開されています。
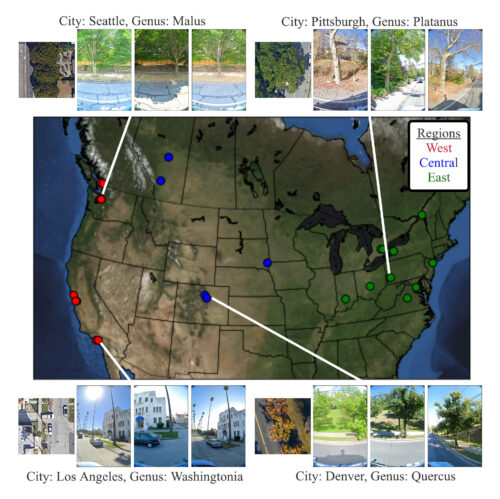
データセットに含まれる23都市は北米に広がっており、空間的および階層的な一般化の分析を可能にするために、西、中央、東の地域に分類されています。
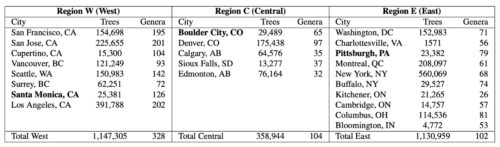
データセットに含まれる樹木の記録と属の数、都市ごと、地域ごと。各地域のホールドアウト都市(学習中に一度も登場しない都市)は太字で表示されています。
Auto Arboristデータセット
Auto Arboristを作成するために、多くの都市がオンラインで提供している既存の樹木の調査から開始しました。各樹木調査について、そのデータにGPSを使った位置と属・種のラベルが含まれていること、および公共利用可能であることを確認しました。
次に、これらのデータを共通のフォーマットに解析し、一般的なデータ入力エラー(緯度・経度の反転など)を修正し、真実の属名(および一般的なスペルミスや俗称)を統一した分類名に割り当てました。
ハイブリッドや亜種から生じる分類学の複雑さを避けるため、また種名(species names)よりも属名(genus names)の方が普遍的なコンセンサスがあることから、(種レベルの予測ではなく)属名の予測を主要なタスクとして焦点を当てることにしました。
次に、各樹木について提供された地理的位置を用いて、その樹木を中心とするRGB航空画像と、その周囲2-10メートル以内に撮影されたすべての街路樹画像を照会しました。
最後に、(1)各画像から目的の樹木が見える可能性を最大化し、(2)ユーザーのプライバシーを保護するために、これらの画像にフィルタをかけました。後者については、セマンティックセグメンテーションによる人物画像の除去や、手動によるぼかし処理など、さまざまなステップを経ています。

Auto Arboristデータセットから選択されたストリートビュー画像。緑のボックスは樹木の検出(Open Imagesで学習したモデルを使用)、青い点はラベル付けされた樹木のGPSによる位置の予測を表しています。
3.Auto Arborist Dataset:都市部に存在する樹木の分布を調査(1/2)まとめ
1)ai.googleblog.com
Mapping Urban Trees Across North America with the Auto Arborist Dataset
2)openaccess.thecvf.com
The Auto Arborist Dataset: A Large-Scale Benchmark for Multiview Urban Forest Monitoring Under Domain Shift
3)google.github.io
The Auto Arborist Dataset

