
1.DALL·E Flow:複数のモデルを組み合わせて入力文に基づいたHD画像を作成(2/2)まとめ
・DALL-E Flowのサーバーは、ピーク時に21GBのVRAMを持つ1つのGPUを必要とする
・12GBのGPUではDALL-E Flowのサーバー側実装を動かすのは難しいかもしれない
・Dockerファイルも提供されているが各ファイルを直接ネイティブで実行する事も可能性
2.DALL·E Flowのサーバー側実装
以下、github.comより「A Human-in-the-Loop workflow for creating HD images from text」の意訳です。
本稿で解説しているサーバー側実装ですが、Dockerが提供されていたので、チャレンジしてみたのですが、私のGeForce RTX 3060(12GB)では「メモリ確保に失敗」とのエラーが出てdocker runの起動もできませんでした。
「ピーク時に21GBのVRAMが必要」との事なので、ワンチャンあるかと思ったのですが、メモリ設定などを変更しても起動させる事がまだ出来ていません。24GB搭載しているGeforce RTX 3090でないと一連のサービスとして起動するのは無理かもしれません。
アイキャッチ画像はDALL·E FLOWでプロンプトは「STUDIO GHIBLI movies style illustration of nausicaa riding Möwe in the castle of the sky.」
サーバー
以下の手順で、ご自身でサーバーを構築することができます。
ハードウェア要件
DALL-E Flowは、ピーク時に21GBのVRAMを持つ1つのGPUを必要とします。すべてのサービスはこの1つのGPUに集約され、これには(おおよそ)以下のものが含まれます。
・DALLE ~9GB
・GLID Diffusion ~6GB
・SwinIR ~3GB
・CLIP ViT-L/14-336px ~3GB
さらにVRAMを減らすためには、以下のような合理的な工夫が必要です。
・SwinIRをCPUに移動(-3GB)
・CLIPをCLIP-as-serviceのデモサーバに委ねる(-3GB)
ハードディスクに少なくとも40GBの空き容量が必要です。主に事前学習済みモデルのダウンロードに使用します。
高速インターネットが必要です。インターネットの速度が遅い、または不安定な場合、モデルのダウンロード時にタイムアウトが発生する可能性があります。
CPUのみの環境は未検証で、動作しない可能性が高いです。Google Colabはメモリ不足エラーを起こす可能性があり、動作しない可能性があります。
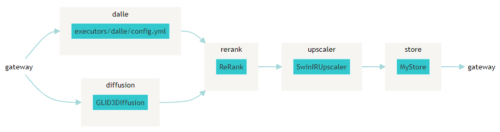
Jinaをインストールしている場合、上記のようなフローチャート図を以下のコマンドで生成することができます。
# pip install jina jina export flowchart flow.yml flow.svg
Dockerで実行する
Dockerfileを提供することで、すぐにサーバを動作させることができます。このDockerfileはCUDA 11.6をベースイメージとしていますが、お使いのシステムに応じて調整してください。
git clone https://github.com/jina-ai/dalle-flow.git
cd dalle-flow
docker build --build-arg GROUP_ID=$(id -g ${USER}) --build-arg USER_ID=$(id -u ${USER}) -t jinaai/dalle-flow .
平均的なインターネット速度で10分ほどで構築でき、10GBのDockerイメージができあがります。
実行するには、単純に
docker run -p 51005:51005 -v $HOME/.cache:/home/dalle/.cache --gpus all jinaai/dalle-flow
初回実行には、平均的なインターネットの速度で約10 分ほどかかるでしょう。
-v $HOME/.cache:/root/.cache を指定すると、Docker 実行時に毎回モデルのダウンロードが繰り返されるのを回避することができます。
-p 51005:51005 の最初の部分の51005は、ホストサーバーの公開ポートです。公開する場合は、このポートにアクセスできることを確認してください。2番目の部分は、flow.ymlで定義したポートです。
実行すると、以下のような画面が表示されます。
ネイティブで実行する場合と異なり、Dockerで実行すると、プログレスバー、カラーログ、印刷が鮮明でなくなる可能性があることに注意してください。これは、Dockerコンテナ内のターミナルの制限によるものです。実際の使用には影響ありません。
ネイティブで実行する
ネイティブで実行すると、いくつかの手動手順が必要ですが、多くの場合、これによりデバッグが容易になります。
レポジトリのクローン
[pyhton] mkdir dalle && cd dallegit clone https://github.com/jina-ai/dalle-flow.git
git clone https://github.com/JingyunLiang/SwinIR.git
git clone https://github.com/CompVis/latent-diffusion.git
git clone https://github.com/hanxiao/glid-3-xl.git
[/pyhton]
以下のようなフォルダ構成になっているはずです。
[pyhton] dalle/|
|– dalle-flow/
|– SwinIR/
|– glid-3-xl/
|– latent-diffusion/
[/pyhton]
補助レポジトリのインストール
[pyhton] cd latent-diffusion && pip install -e . && cd –cd glid-3-xl && pip install -e . && cd –
[/pyhton]
GLID-3-XLには、ダウンロードが必要なモデルがいくつかあります。
[pyhton] cd glid-3-xlwget https://dall-3.com/models/glid-3-xl/bert.pt
wget https://dall-3.com/models/glid-3-xl/kl-f8.pt
wget https://dall-3.com/models/glid-3-xl/finetune.pt
cd –
[/pyhton]
flowのインストール
[pyhton] cd dalle-flowpip install -r requirements.txt
[/pyhton]
サーバーの起動
今、貴方はdalle-flow/以下に移動したので、以下のコマンドを実行します。
[pyhton] jina flow –uses flow.yml[/pyhton]
すぐにこの画面が表示されるはずです。
初回起動時は、DALL·E megaモデルやその他必要なモデルのダウンロードに8分ほどかかります。続けて実行すると、成功のメッセージに到達するまでに1分ほどしかかかりません。
すべての準備が整ったら、以下の画面が表示されます。
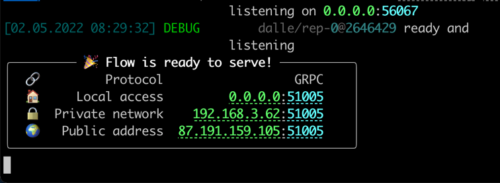
おめでとうございます。これでクライアントを実行できるようになったはずです。
サーバーフローは、モデルの変更、永続化の追加、Instagram/OpenSeaへの自動投稿など、好きなように修正・拡張することが可能です。JinaとDocArrayを使えば、DALL-E Flowを簡単にクラウドネイティブにし、本番環境に対応させることができるのです。
サポート
DALL-E Flowを拡張するには、JinaとDocArrayに精通する必要があります。私たちのSlackコミュニティに参加し、他のコミュニティメンバーとアイデアについてチャットしてください。
私たちのエンジニアリング・オールハンズ・ミートアップに参加して、あなたのユースケースについて話し合い、Jinaの新機能を学びましょう。
・いつ?毎月第二火曜日
・どこで?Zoom(公開イベントカレンダー/.icalを参照)とYouTubeでのライブストリーム
・YouTubeチャンネルで最新のビデオチュートリアルを購読しましょう。
DALL-E Flowは、Jina AIが支援し、Apache-2.0の下でライセンスされています。私たちは、オープンソースで次のニューラル・サーチ・エコシステムを構築するために、AIエンジニア、ソリューション・エンジニアを積極的に採用しています。
3.DALL·E Flow:複数のモデルを組み合わせて入力文に基づいたHD画像を作成(2/2)関連リンク
1)github.com
jina-ai / dalle-flow
2)colab.research.google.com
client.ipynb

