
1.LIMoE:画像と文章に対応可能で規模拡大が容易なスパースMoEモデル(1/2)まとめ
・従来の密なモデルに比べると疎らなスパースモデルは規模拡大が用意で将来的に有望
・疎なモデルは密なモデルが直面するマルチタスク時の性能悪化や破局的忘却を回避可能
・従来のスパースモデルは言語領域か視覚領域に特化していたがLIMoEは両方を同時に扱える
2.LIMoEとは?
以下、ai.googleblog.comより「LIMoE: Learning Multiple Modalities with One Sparse Mixture-of-Experts Model」の意訳です。元記事は2022年6月9日、Basil MustafaさんとCarlos Riquelmeさんによる投稿です。
アイキャッチ画像はDALL·E FLOWでプロンプトは「Illustration of Moe model」。萌えな二次元画像を予想していたのですがアートっぽくなりました。modelの方がインスピレーションを与えるようです。
スパースモデル(Sparse models)は、ディープラーニングの将来的に有望なアプローチの中で最も際立っています。モデルのすべての部分がすべての入力を処理する(密なモデリング(Dense modeling))ではなく、条件付き計算を採用した疎らなスパースモデルは、潜在的に巨大なネットワーク内の異なる「エキスパート(Experts)」に個々の入力をルーティングすることを学習します。
これには多くの利点があります。まず、計算コストを一定に保ったままモデルサイズを大きくすることができます。これは、効率的かつ環境に優しいモデルの規模拡大方法であり、しばしば高性能化の鍵となるものです。
また、スパース性はニューラルネットワークを自然に区分けします。多くのタスクを同時に(マルチタスク)、あるいは逐次的に(継続学習(continual learning))学習する高密度モデルは、タスクの種類が多すぎるためにタスクごとに1つのモデルを学習した方が良いという負の干渉や、新しいタスクが追加されると以前のタスクでモデルの性能が悪くなるという破局的忘却(catastrophic forgetting)に悩まされることがよくあります。
スパースモデルはこれらの現象を回避するのに役立ちます。すべての入力に対してモデル全体を適用しないことで、モデルの「Experts」はモデルの共有部分を利用しつつ、異なるタスクやデータ型に特化することができるのです。
Google Researchでは、スパース性に関する研究が長く続けられています。Pathwaysビジョンは、数千のタスクと様々なデータ入力を満遍なく処理する一つの大きなモデルを構築するという研究指針を集約しています。
これまで、言語領域(Switch, Task-MoE, GLaM)やコンピュータビジョン領域(Vision MoE)のためのスパースユニモーダルモデルにかなりの進展がありました。
本日、私達は、モダリティにとらわれないルーティングで画像とテキストを同時に扱う大規模なスパースモデルを研究することにより、Pathwaysビジョンに向けた新たな重要な一歩を踏み出しました。
関連するアプローチにマルチモーダル対照学習があります。これは、画像をその画像を説明する正しい文章と紐づけるため、画像とテキストの両方をしっかり理解する必要があります。この課題に取り組む最も強力なモデルは、各モダリティに対して独立したネットワーク(2タワーアプローチ)に依存しています。
論文「Multimodal Contrastive Learning with LIMoE: the Language Image Mixture of Experts」では、まばらな「専門家の寄せ集め(MoE:Mixture-of-Experts)」を用いた初の大規模なマルチモーダルアーキテクチャを紹介します。
LIMoEは、画像とテキストの両方を同時に処理しますが、まばらに活性化され自然に専門化するExpertsを使用します。ゼロショット画像分類において、LIMoEは同等の高密度マルチモーダルモデルと2タワーアプローチの両方を凌駕する性能を示しました。最大のLIMoEは84.1%のゼロショットImageNet精度を達成し、これはより高価な最先端モデルに匹敵します。
スパース性により、LIMoEは優雅に規模を拡大し、非常に異なる入力を扱うことを学習し、万能のジェネラリストと一流のスペシャリストの間の綱引きに対処することができるようになりました。

IMoEアーキテクチャには多数の「Experts」が存在し、どのトークン(画像や文章の一部)がどのExpertsに行くかはルーターが決定します。Experts層(灰色)と共有高密度層(茶色)で処理された後、最終出力層で画像か文章のどちらか1つのベクトル特徴表現が計算されます。
まばらなMixture-of-Expertsモデル
Transformerはデータをベクトル(またはトークン)の列として表現します。元々はテキスト処理用に開発されましたが、画像、動画、音声など、トークンの列として表現可能なほとんどのものに適用できます。最近の大規模なMoEモデルは、TransformerアーキテクチャにExperts層を追加しています。(例えば、自然言語処理におけるgShardとST-MoE、視覚タスクにおけるVision MoEなど)。
標準的なTransformerは多くの「ブロック」で構成され、それぞれが様々な異なるレイヤーを含んでいます。これらの層の1つは、フィードフォワードネットワーク(FFN:Feed-Forward Network)です。
LIMoEと前述の作品では、この単一のFFNは、それぞれがExpertsである多数の並列FFNを含むエキスパート層で置き換えられます。処理すべきトークンの並びが与えられると、単純なルーターが、どのExpertsがどのトークンを処理すべきかを予測するように学習します。
つまり、多くのExpertsを持つことでモデル容量は大幅に増加しますが、Expertsをまばらに使用することで実際の計算コストは抑制されます。もしExpertsが1人しかいなければ、モデルのコストは標準的なTransformerモデルとほぼ同等になります。
LIMoEはまさにこの通り、1サンプルにつき1つのExpertsを起動させることで、高密度なベースラインの計算コストに匹敵する計算効率を実現しています。異なるのは、LIMoEルーターが画像またはテキストデータのトークンに遭遇する可能性があることです。
MoEモデル特有の故障モード(failure mode)は、すべてのトークンを同じExpertsに送ろうとしたときに発生します。通常、これは補助損失(auxiliary losses)、つまりバランスの取れたExpertsの使用を促す特別な学習目標で対処されます。
しかし、複数のモダリティを扱うことは、スパース性と相互作用し、既存の補助的損失では対処できない新たな故障モードを引き起こすことが分かりました。この問題を解決するために、我々は新しい補助損失を開発し(詳細は論文参照)、学習時にルーティングの優先順位付け(BPR:Batch Priority Routing)を行うという2つの工夫を行い、安定かつ高性能なマルチモーダルモデルを実現しました。
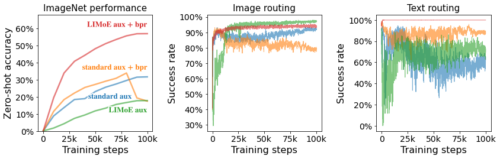
新しい補助損失(LIMoE aux)とルーティングの優先順位付け(BPR)により、全体のパフォーマンスが安定・向上し(左)、ルーティング動作の成功率が高まりました。(中・右)
成功率が低いということは、ルーターが利用可能なエキスパートをすべて使っておらず、個々のエキスパートの容量に達しているために多くのトークンを取りこぼしていることを意味し、これは通常、スパースモデルがうまく学習できていないことを示しています。LIMoEに導入された組み合わせは、画像とテキストの両方で高いルーティング成功率を保証し、その結果、性能が大幅に向上しています。
3.LIMoE:画像と文章に対応可能で規模拡大が容易なスパースMoEモデル(1/2)関連リンク
1)ai.googleblog.com
LIMoE: Learning Multiple Modalities with One Sparse Mixture-of-Experts Model
2)arxiv.org
Multimodal Contrastive Learning with LIMoE: the Language-Image Mixture of Experts

