
1.V-MoEs:条件付き計算を使って視覚モデルの規模を拡大(1/2)まとめ
・大規模なモデルやデータセットを使用するためには大量の計算が必要になり困難
・計算に必要なリソースを抑える有望な手法のひとつに条件付き計算がある
・これは常にネットワーク全体を活性化させるのではなく一部のみ活性化させる手法
2.条件付き計算とは?
以下、ai.googleblog.comより「Scaling Vision with Sparse Mixture of Experts」の意訳です。元記事は2022年1月13日、Carlos RiquelmeさんとJoan Puigcerverさんによる投稿です。
寄せ集められた専門家(Mixture of Experts)をイメージしたアイキャッチ画像のクレジットはPhoto by Sebastian Herrmann on Unsplash
過去数十年にわたる深層学習の進歩は、いくつかの重要な要素によって推し進められてきました。少数の単純であっても柔軟なメカニズム(畳み込みやシーケンシャルAttentionなどの帰納的バイアス)、巨大化するデータセット、より機械学習に特化したハードウェアにより、ニューラルネットワークは、画像分類、機械翻訳、タンパク質の折りたたみ構造予測(protein folding prediction)などの幅広いタスクで素晴らしい結果を達成できるようになったのです。
しかし、大規模なモデルやデータセットを使用するためには、大量の計算が必要になります。そして、最近の研究では、強力な一般化能力と堅牢性のためには巨大なモデルサイズが必要である可能性が示唆されており、計算に必要なリソース要件を抑えながら大規模モデルを学習させることがますます重要になってきています。
有望なアプローチのひとつに、条件付き計算(conditional computation)があります。
条件付き計算とは、あらゆる入力に対して常にネットワーク全体を活性化させるのではなく、異なる入力に対してモデルの異なる部分を活性化させる手法です。
この手法はGoogleが計画している次世代大規模モデル構想であるPathways visionや大規模言語モデルに関する最近の研究で取り上げられていますが、コンピュータビジョンの分野ではあまり検討されていません。
論文「Scaling Vision with Sparse Mixture of Experts」ではV-MoEを紹介しています。V-MoEは、疎なMoE(Mixture of Experts)に基づく新しいビジョンアーキテクチャで、これを用いてこれまでで最大の視覚モデルを学習させています。
またV-MoEをImageNetに転移させ、同等の性能を持つモデルよりも約50%少ないリソースで、最先端の精度にマッチすることを実証しています。また、この疎なモデル(スパースモデル)を学習するためのコードをオープンソース化し、いくつかの学習済みモデルを提供しています。
Vision Mixture of Experts (V-MoEs)
ビジョントランスフォーマー(ViT:Vision Transformers)は、視覚タスクに最適なアーキテクチャの1つとして登場しました。ViTはまず、画像を等しい大きさの正方形の断片に分割します。この断片は言語モデルから受け継いだ用語で、トークン(tokens)と呼ばれます。しかし、最大の言語モデルと比較すると、ViTモデルはパラメータの数と計算量の点で数桁規模で小さくなっています。
視覚モデルを大規模に拡張するために、ViTアーキテクチャの一部の「密に結合したフィードフォワード層(FFN:feedforward layers)」を、「疎に結合した個々のFFN(Expertsと呼びます)を寄せ集めたもの」に置き換えます。
学習するルーターレイヤー(router layer)は、個々のトークンごとにどのExpertsの入力とするか(そしてどのように重み付けするか)を選択します。つまり、同じ画像内の異なるトークンは、異なるExpertsの入力になるようにルーティングされる可能性があります。
各トークンは、合計E人のExperts(私たちの実験では、Eは通常32人)のうち、最大K人(通常1人か2人)のExpertsにのみ送られます。このため、トークン1個あたりの計算量をほぼ一定に保ちながら、モデルのサイズを拡張することができるのです。下図は、エンコーダブロックの構造をより詳細に示しています。
V-MoE Transformerのエンコーダーブロック
実験結果
まず、大規模な画像データセットであるJFT-300Mで一度、モデルの事前学習を行いました。下の左図は、小さなS/32から巨大なH/14まで、あらゆるサイズのモデルに対する事前学習の結果を示しています。
次に、新しいヘッド(モデルの最終層)を用いて、モデルを新しい下流タスク(ImageNetなど)に転移します。新しいタスクの利用可能なすべてのサンプルでモデル全体を微調整する方法と、事前に学習したネットワークを凍結し、いくつかのサンプルを使って新しいヘッドのみを調整する方法(少数ショット転移と呼ばれます)の2つの転移設定を検討しました。
下図の右側のプロットは、1クラスあたり5枚の画像で学習させた場合のImageNetへの転移結果をまとめたものです(5ショット転移と呼びます)
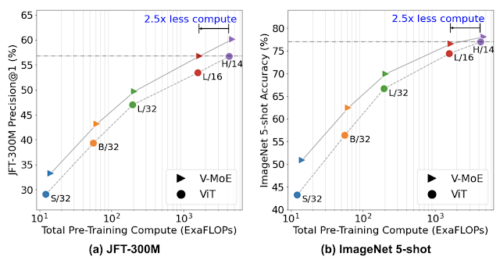
JFT-300MのPrecision@1とImageNet 5-shotの精度
色はViTのバリエーションを表し、マーカーは標準的なViT(●)、または最後のn偶数ブロックにExperts層を持つV-MoE(▸)を表します。V-MoE-Hのn=5を除き、すべてのモデルでn=2を設定しました。高いほど性能が良いことを示し、より効率的なモデルほど左側にあります。
3.V-MoEs:条件付き計算を使って視覚モデルの規模を拡大(1/2)関連リンク
1)ai.googleblog.com
Scaling Vision with Sparse Mixture of Experts
2)arxiv.org
Scaling Vision with Sparse Mixture of Experts
3)github.com
google-research / vmoe

