
1.CoCa:様々な視覚タスクのバックボーンとして利用できる基盤モデル(2/2)まとめ
・CoCaモデルは、最小限の改造で多くのタスクに対して直接微調整を行うことが可能
・CoCaは画像分類やクロスモーダル検索などのゼロショットでも最先端モデルを凌駕する
・CoCaは新規の画像-テキストバックボーンで最小限の改造で最先端の性能を発揮する
2.CoCaの性能
以下、ai.googleblog.comより「Image-Text Pre-training with Contrastive Captioners」の意訳です。元記事は2022年5月24日、Zirui WangさんとJiahui Yuさんによる投稿です。
アイキャッチ画像はDALL·E Mini
ベンチマーク結果
CoCaモデルは、最小限の改造で多くのタスクに対して直接微調整を行うことが可能です。その結果、一般的な視覚・マルチモーダルベンチマークにおいて、一連の最新鋭の結果を得ることができました。
(1)視覚認識(visual recognition):ImageNet、Kinetics-400/600/700、MiT
(2)クロスモーダルアライメント(cross-modal alignment):MS-COCO、Flickr30K、MSR-VTT
(3)マルチモーダル理解(multimodal understanding):VQA、SNLI-VE、NLVR2、NoCaps
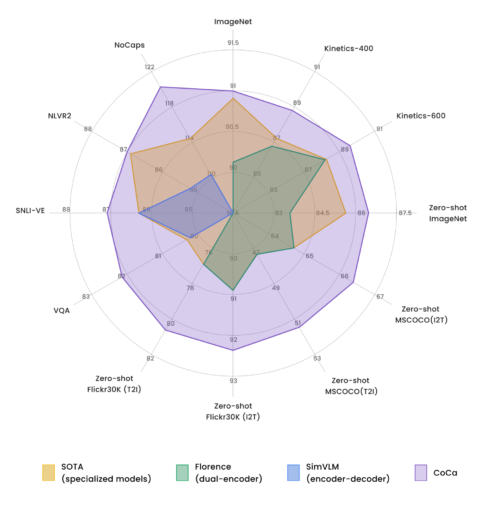
CoCaと「他の画像-テキストバックボーンモデル(タスクに特化したカスタマイズなし)」および「最新のタスク特化型モデル」との比較
注目すべきは、CoCaが全てのタスクに適応した単一モデルでありながら、従来のトップレベルの性能を持つ専用モデルよりも軽量であることが多いことです。
例えば、CoCaはImageNetのtop1精度で91.0%を達成し、パラメータ数は従来の半分以下となっています。また、CoCaは高品質なキャプション文を画像に付与する強力なキャプション生成能力も獲得しています。
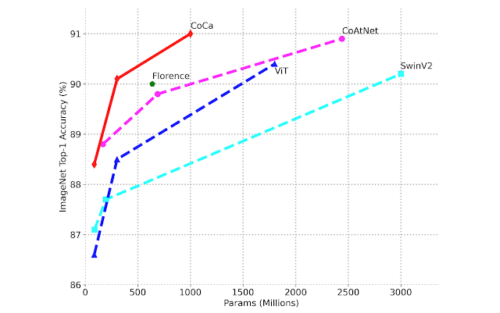
画像分類におけるモデル規模と性能の関係
微調整されたImageNetのtop1精度とモデルサイズの比較

NoCapsデータセットの画像を入力した際にCoCaが生成したキャプション文
ゼロショット性能
CoCaは、微調整により優れた性能を達成するだけでなく、画像分類やクロスモーダル検索などのゼロショット学習タスクにおいても、従来の最先端モデルを凌駕する性能を有しています。
CoCaはImageNetにおいて86.3%のゼロショット精度を達成し、ImageNet-A, ImageNet-R, ImageNet-V2, ImageNet-Sketchといった難易度を高めたベンチマークにおいても、従来モデルを上回り頑健性を発揮します。下図に示すように、CoCaは従来手法と比較して、より小さなモデルサイズでより良いゼロショット精度を獲得しています。
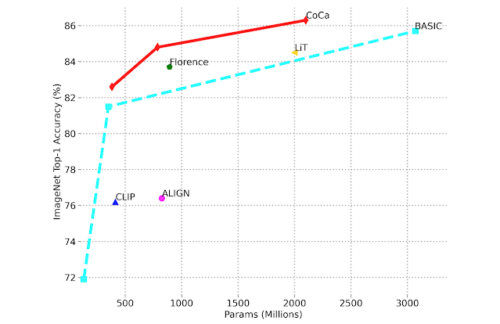
画像分類性能をゼロショットImageNetのtop-1精度とモデルサイズで比較
凍結エンコーダ特徴表現
特に興味深いのは、CoCaが凍結したビジュアルエンコーダのみを用いて、微調整したモデルに匹敵する結果を達成したことです。これは、モデル学習後に抽出された特徴を分類器の学習に利用する事であり、これにより、モデルを微調整するよりも計算量が少なくなり、より効率的な学習が可能になります。
ImageNetにおいて、学習済み分類ヘッド付きCoCaエンコーダは90.6%のtop-1精度を達成しました。これは既存のバックボーンモデルの完全に微調整された性能(90.1%)を上回ります。
また、このセットアップは動画認識にも非常に有効であることがわかりました。サンプリングしたビデオフレームを個々にCoCa凍結画像エンコーダーに送り込み、学習済み分類器を適用する前にattentionalプーリングによって出力特徴を融合させます。
CoCa凍結画像エンコーダを用いたこのシンプルなアプローチは、Kinetics-400データセットにおいて動画行動認識のtop-1精度88.0%を達成し、CoCaが複合的な学習目標で高度に汎用的な視覚特徴表現を学習することを実証しています。
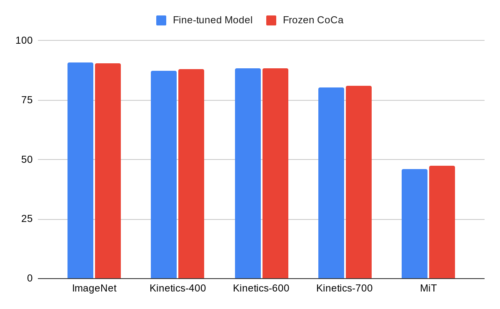
凍結型CoCaビジュアルエンコーダと(複数の)最適な微調整を施したモデルとの比較
まとめ
本論文では、画像-テキストバックボーンモデルのための新しい事前学習パラダイムであるContrastive Captioner(CoCa)を紹介しました。この手法は、様々な種類の視覚・視覚-言語タスクに広く適用可能であり、タスクに応じた最小限の適応で、あるいは全く適応することなく、最先端の性能を得ることができます。
謝辞
このプロジェクトのあらゆる側面に携わってくださった共著者のVijay Vasudevan、Legg Yeung、Mojtaba Seyedhosseini、Yonghui Wuに感謝します。
また、Yi-Ting Chen, Kaifeng Chen, Ye Xia, Zhen Li, Chao Jia, Yinfei Yang, Zhengdong Zhang, Wei Han, Yuan Cao, Tao Zhu, Futang Peng, Soham Ghosh.に感謝します。Zihang Dai, Xin Li, Anelia Angelova, Jason Baldridge, Izhak Shafran, Shengyang Dai, Abhijit Ogale, Zhifeng Chen, Claire Cui, Paul Natsev, Tom Duerig には有益な議論をしていただきました。
Andrew Daiは対照モデルについて、Christopher FiftyとBowen Zhangはビデオモデルについて、Yuanzhong Xuはモデルのスケーリングについて、Lucas Beyerはデータ準備について、それぞれ協力してくれました。
Andy Zengには MSR-VTT の評価について、Hieu PhamとSimon Kornblithにはゼロショット評価について、Erica Moreiraと Victor Gomesにはリソース調整について、Liangliang Caoには校正についてご協力をいただきました。
このブログで使用したアニメーションを作成してくれたTom Small、そしてこのプロジェクトを通してサポートしてくれたGoogle Brainチームの他のメンバーにも感謝します。
3.CoCa:様々な視覚タスクのバックボーンとして利用できる基盤モデル(2/2)関連リンク
1)ai.googleblog.com
Image-Text Pre-training with Contrastive Captioners
2)arxiv.org
CoCa: Contrastive Captioners are Image-Text Foundation Models

