
1.脚式ロボットが学習時に転倒して破損しないようにする(2/3)まとめ
・ロボットを使い効率的歩行、キャットウォーク、2脚バランスタスクで実験を行った
・学習者ポリシーは安全回復ポリシーを発動する必要性を回避しながら学習できた
・安全トリガーセットと安全回復ポリシーは性能が向上してもポリシー探索を妨げない
2.安全回復ポリシーの効果
以下、ai.googleblog.comより「Learning Locomotion Skills Safely in the Real World」の意訳です。元記事は2022年5月5日、Jimmy (Tsung-Yen) Yangさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Ana Dujmovic on Unsplash
脚式機関の課題
本アルゴリズムの有効性を示すために、3種類の脚式機関の運動技能の学習を考えます。
(1)効率的歩行(Efficient Gait)
ロボットはエネルギー消費の少ない歩き方を学習し、エネルギー消費が少なければ報酬が与えられます。
(2)キャットウォーク(Catwalk)
ロボットが、左右の2本の足が互いに接近するキャットウォーク歩行パターンを学習します。体重を支える脚が狭い多角形形状になるため、ロボットの安定性が損なわれます。そのため、キャットウォークは挑戦的な取り組みです。
(3)2脚バランス(Two-leg Balance)
右前と左後ろの2本の足で立脚し、残りの2本の足を持ち上げる2脚バランス方針を学習します。体重を支える脚が多角形形状から線分形状に縮退してしまうため、繊細なバランス制御を行わないと簡単に転倒してしまいます。

論文で検討したロコモーションタスク(Locomotion tasks)
上段:効率的な歩行 中段:キャットウォーク 下段:両足バランス
実装の詳細
学習者ポリシーと安全回復ポリシーには、RLと従来の制御手法を組み合わせた階層的ポリシーフレームワークを用いています。
このフレームワークは、歩行パラメータ(例:ステップ頻度)と足の配置を生成する高レベルのRLポリシーと、これらのパラメータを取り込んでロボットの各モータに望ましい出力を計算するモデル予測制御(MPC:Model Predictive Control)という低レベルのプロセスコントローラで構成されています。
モータの角度を直接指令しないため、より安定した動作が得られ、行動空間が小さくなるためポリシーの学習が効率化され、より堅牢なポリシーが得られます。
RLポリシーネットワークの入力には、以前の歩行パラメータ、ロボットの高さ、機体の向き、直線速度、角速度、およびロボットが安全トリガセットに近づいているかどうかを示すフィードバックが含まれます。私達は各タスクで同じ設定を使用しています。
私達は、できるだけ早く安定に到達することに報酬を与える安全回復ポリシーを訓練します。さらに、捕捉可能性理論(capturability theory)からヒントを得て、安全トリガーセットを設計します。
特に、最初の安全トリガーセットは、ロボットの足が安全回復ポリシーを使って安全に回復できる状態から外れないことを保証するために定義されます。次に、このセットを実際のロボット上でランダムなポリシーで微調整し、ロボットが転倒しないようにします。
実世界の実験結果
効率的歩行、キャットウォーク、2脚バランスタスクにおける報酬学習曲線と安全回復ポリシー起動の割合を示す実環境実験結果を報告します。
ロボットが安全に学習できるように、安全回復ポリシーを発動する際にペナルティを追加しています。ここで、2脚バランスタスクだけより多くの学習ステップを必要とするため、シミュレーションで事前に学習させていますが、それ以外は、すべてのポリシーをゼロから学習させています。
全体として、これらのタスクでは、報酬が増加し、安全回復ポリシーの使用率がポリシーの更新に伴って減少していることがわかります。
例えば、効率的な歩行タスクでは、安全な回復ポリシーの使用割合が20%から0%近くまで減少しています。また、2脚バランス課題では、82.5%から67.5%に減少しており、2脚バランスは前の2つの課題よりかなり難しいことが示唆されます。それでも、このポリシーは報酬を向上させることができます。
このことから、学習者ポリシーは安全回復ポリシーを発動する必要性を回避しながら、徐々に課題を学習することができることが示唆されます。さらに、このことは、安全なトリガーセットと安全回復ポリシーを設計することが可能であり、性能が向上しても、ポリシーの探索を妨げないことを示唆しています。
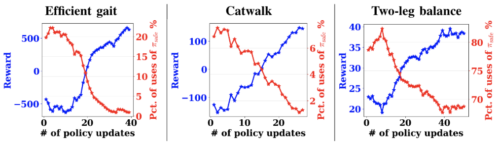
実世界における報酬学習曲線(青)と、私達の安全RLアルゴリズムを用いた安全回復ポリシーの発動率(赤)
3.脚式ロボットが学習時に転倒して破損しないようにする(2/3)関連リンク
1)ai.googleblog.com
Learning Locomotion Skills Safely in the Real World
2)arxiv.org
Safe Reinforcement Learning for Legged Locomotion
