
1.Pix2Seq:言語モデルを使って物体検出を行う(2/2)まとめ
・Pix2Seqでは物体検出を言語モデリングタスクとみなしており特別な設計をしていない
・システムの出力が比較的簡潔なトークンの並びで表現されるような領域に応用可能
・幅広い視覚および知覚システムに言語インターフェースを提供する用に組み込み事が可能
2.Pix2Seqの性能
以下、ai.googleblog.comより「Pix2Seq: A New Language Interface for Object Detection」の意訳です。元記事は2022年4月22日、Ting ChenさんとDavid Fleetさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Clem Onojeghuo on Unsplash
量子化後、各トレーニング画像に含まれる物体の注釈は、以下のような離散的なトークンのシーケンスに並べられます。物体の順序は検出タスク自体には関係ないため、学習中に画像が表示されるたびに物体の順序をランダムにします。また、画像内に存在する物体の数が異なることが多いため、最後にEOS(End of Sequence)トークンを追加し、シーケンス長を決定します。
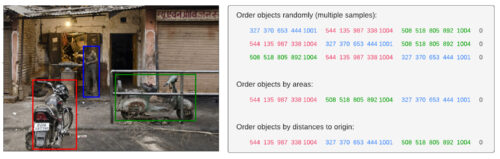
左の画像から検出されたオブジェクトの境界ボックスとクラスラベルは、右側のシーケンスで表現されています。本研究ではランダムに物体の順序付け(random object ordering strategy)を行っていますが、他の順序付けのアプローチも可能です。
モデルの構成、目的関数、推論
私達は物体の説明から構築されたシーケンスを「方言(dialect)」として扱い、画像エンコーダと自己回帰言語エンコーダを備えた強力で一般的な言語モデルによって問題に取り組みます。
言語モデリングと同様に、Pix2Seqは画像と先行するトークンが与えられたとき、最尤損失でトークンを予測するように学習します。
推論時に、モデルの尤度を元にトークンを抽出します。抽出されたシーケンスはEOSトークンが生成された時点で終了します。
シーケンスが生成されると、それを5つのトークン塊に分割し、物体の説明を抽出・非量子化します(すなわち、予測された境界ボックスとクラスラベルを得ます)。
注目すべきは、アーキテクチャと損失関数の両方が、物体検出に関する事前知識(例えば、境界ボックス)を仮定していない点で、タスクにとらわれないということです。本論文では、タスク固有の事前知識をシーケンス拡張技術で取り込む方法について述べています。
研究成果
Pix2Seqはそのシンプルさにもかかわらず、ベンチマークデータセットで印象的な経験的性能を達成しました。特に、広く使われているCOCOデータセットにおいて、よく知られたベースラインであるFaster R-CNNやDETRと比較し、競争力のある平均精度(AP)結果を達成することを実証しています。

Pix2Seqは、モデル設計時に専門性を必要とする従来システムと比較して、大幅にシンプルでありながら、競争力のあるAP結果を達成しています。Pix2Seqの最高性能のモデルは、APスコア45を達成しました。
本アプローチでは、モデル設計時に誘導バイアスや物体検出タスクの事前知識を最小限に抑えているため、大規模物体検出COCOデータセットを用いたモデルの事前学習が性能に与える影響をさらに調査しました。
その結果、この学習戦略(より大きなモデルの使用とともに)は、性能をさらに向上させることができることが示されました。
Pix2Seqモデルの平均精度(事前学習と微調整を行った場合)
事前学習を行わなかった場合のPix2Seqモデルの最高性能はAPスコア45でした。事前学習を行った場合、APスコアは50となり、11%の改善が見られました。
Pix2Seqは、下図のような人口密度の高い複雑な風景でも物体を検出することができます。

学習済みPix2Seqモデルによってラベル付けされた、複雑で人口密度の高い風景の例
Colabでお試しください
結論と今後の課題
Pix2Seqでは、物体検出を言語モデリングタスクとみなしています。モデルアーキテクチャと損失関数は一般的なものであり、検出タスクのために特別に設計されていない画素入力を条件としています。
したがって、このフレームワークは、システムの出力が比較的簡潔なトークンの列で表現されるような異なる領域や応用(例:キーポイント検出、画像キャプション、視覚的質問応答)へ容易に拡張でき、また、汎用的な知的システムを支える知覚システムにも組み込むことができ、幅広い視覚および言語タスクへの言語インターフェースを提供することができます。また、Pix2Seqのコード、学習済みモデル、対話型デモの公開が、この方向でのさらなる研究の刺激となることを期待しています。
謝辞
この記事は、共著者との共同研究を反映しています。Saurabh Saxena、Lala Li、Geoffrey Hinton。また、Pix2Seqの図をビジュアル化してくれたTom Smallに感謝します。
3.Pix2Seq:言語モデルを使って物体検出を行う(2/2)関連リンク
1)ai.googleblog.com
Pix2Seq: A New Language Interface for Object Detection
2)arxiv.org
Pix2seq: A Language Modeling Framework for Object Detection
3)github.com
google-research / pix2seq
4)colab.research.google.com
Pix2Seq Inference (Object Detection).ipynb

