1.FormNet:書式に基づいた文書理解を実現(2/2)まとめ
・FormNetは多くの代替案に欠けている数学的正しさを備えていると見なせる
・新しいRichAtt機構とスーパートークンにより優れたフォーム理解能力を発揮可能
・FormNet-A2は2.5倍小さいモデルでありながら最新手法のスコアを凌駕する
2.FormNetの性能
以下、ai.googleblog.comより「FormNet: Beyond Sequential Modeling for Form-Based Document Understanding」の意訳です。元記事は2022年4月20日、Chen-Yu LeeさんとChun-Liang Liさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Kelly Sikkema on Unsplash
しかし、あるトークンが他の与えられたトークンにどれだけ強くAttentionすべきかの判断には、QueryとKeyベクトル以外の他の特徴、例えば、それらの順番、間にあるトークンの数、あるいは、それらの間隔が何画素であるかなどがしばしば関係します。
これらの特徴をシステムに組み込むために、私達は学習可能なパラメトリック関数(parametric function)とエラーネットワークの組を用います。エラーネットワークは観測された特徴とパラメトリック関数の出力を取り、ドット積Attentionスコア(dot product attention score)を減少させるペナルティを返します。
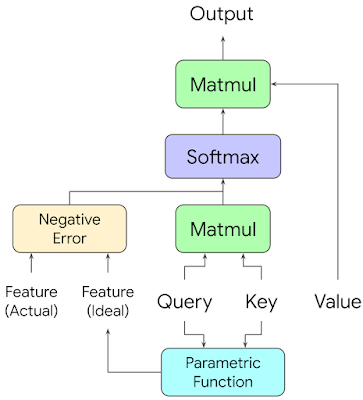
ネットワークはQueryとKeyのベクトルを用いて、トークンが関連している場合に何らかの低レベルの特徴(例えば距離)がどのような値をとるべきかを検討し、その誤差に基づいてAttentionスコアにペナルティを課します。
高レベルでは、各レイヤーの各Attentionヘッドに対して、FormNetはトークン特徴表現の各ペアを調べ、それらの間に意味のある関係がある場合にトークンが持つべき理想的な特徴表現を決定し、実際の特徴表現が理想的な特徴表現からどれだけ異なるかに応じてAttentionスコアにペナルティを与えます。これにより、モデルは論理的含意を用いてAttention制約を学習することができます。
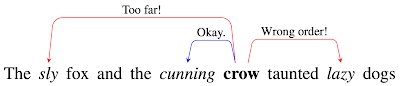
RichAttが文章にどのように作用するかを視覚化した図
「crow」という単語がAttentionする可能性のある形容詞が3つあります。
「Lazy」は右側にあるので、おそらく「crow」を修飾せず、そのAttentionエッジはペナルティを受けます。「Sly」は離れている(間に多くのトークンがある)ので、そのAttentionエッジもペナルティーを受けます。「Cunning」は大きなペナルティを受けないので、消去法で最もAttentionすべき候補となります。
さらに、ソフトマックスで正規化された注目スコア(softmax-normalized attention scores)が確率分布を表し、観測された特徴の分布が既知であると仮定すると、このアルゴリズム(パラメトリック関数と誤差関数の正確な選択を含む)は代数計算に帰結します。
つまり、FormNetは多くの代替案(相対的を含むembeddings)に欠けている数学的正しさを備えています。
グラフ学習によるスーパートークン
長いシーケンスをモデリングする際、ETCのAttention機構をスパース化する鍵は、すべてのトークンが直列化されたシーケンスにおいて近傍にあるトークンにのみ注意するようにすることです。RichAtt機構は空間レイアウト構造を考慮することでtransformersを強化しますが、貧弱な直列化は依然として関連する単語トークン間の重要なAttentionの重み計算をブロックする可能性があります。
この問題をさらに軽減するために、私達はフォーム文書中の近傍のトークンを結ぶグラフを構築します。グラフの辺は強い帰納的バイアスに基づき、同じエンティティタイプに属する確率がより高くなるように設計します。
各トークンについて、隣接するトークンから意味的に関連する情報を集約するために、これらのエッジに沿ってグラフ畳み込みを適用して、そのスーパートークンのembeddingsを得ます。このスーパートークンをRichAtt ETCアーキテクチャの入力として使用します。このようにGCNが学習したスーパートークン(Super-Token)は、逐次処理が不十分なためにエンティティが複数のセグメントに分割されたとしても、エンティティフレーズの文脈の多くを保持していることを意味します。
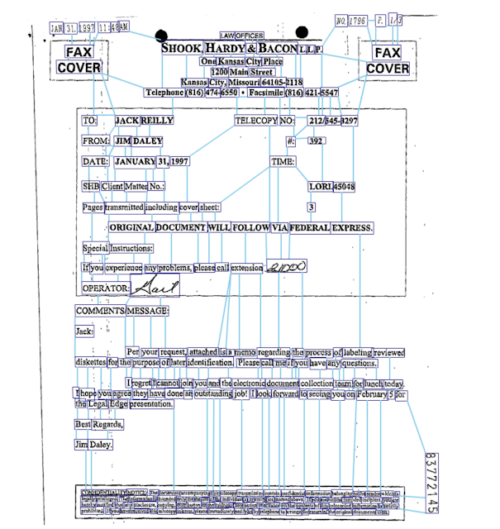
FUNSD文書の単語レベルグラフ(トークン間に青いエッジがあります)の説明図
主な結果
下の図は、CORDベンチマークにおける最近のアプローチのモデルサイズとF1スコア(精度と再現率の調和平均)を示しています。FormNet-A2は2.5倍小さいモデルを用いながら、最新のDocFormerを凌駕しています。FormNet-A3は97.28%のF1スコアで最先端の性能を達成しました。より詳細な実験結果については、論文をご参照ください。
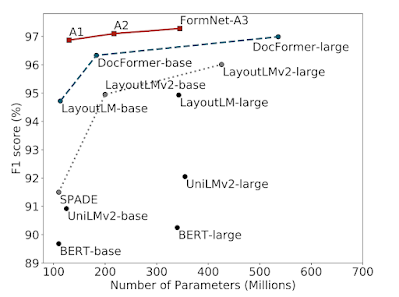
CORDベンチマークにおけるモデルサイズとエンティティ抽出のF1スコアの比較
FormNetは、絶対的なF1性能とパラメータ効率において、他の最近のアプローチを大幅に上回っています。
3種のFormNetsを用いて大規模なマスク言語モデリング(MLM:masked language modeling)事前学習タスクにおけるRichAttとGCNによるスーパートークンの重要性を研究しました。
RichAttとGCNの両コンポーネントはETCベースラインよりもマスクされたトークンの再構成において大幅な改善をし、フォーム文書に対する構造的エンコーディング機能の有効性を示しています。RichAttとGCNの両方を組み込んだ場合に、最高の性能が得られれます。
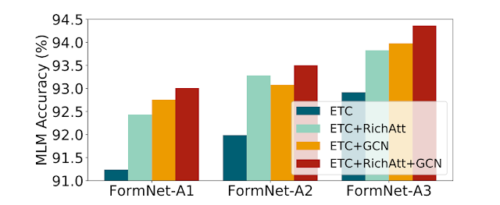
マスク言語モデリング(MLM)の事前学習の性能
提案するRichAttとGCNによるスーパートークンの両コンポーネントは、ETCベースラインを大幅に改善し、大規模なフォーム文書に対する構造エンコーディング能力の有効性を示しています。
BertVizを用いて、CORDデータセットの特定の例について、標準ETCモデルとFormNetモデルのlocal-to-local attention scoreを可視化しました。
定性的には、FormNetの場合、トークンは主に同じ視覚ブロック内の他のトークンにAttentionしていることが確認されました。さらにそのモデルでは、特定のAttention headが、フォーム文書の意味の強い信号である水平に並んだトークンに向かっていることが確認されました。ETCモデルでは明確なAttentionパターンが現れず、GCNによるRichAttとSuper-Tokenによって、モデルが構造的な手がかりを学習し、レイアウト情報を効果的に活用することができることが示唆されました。
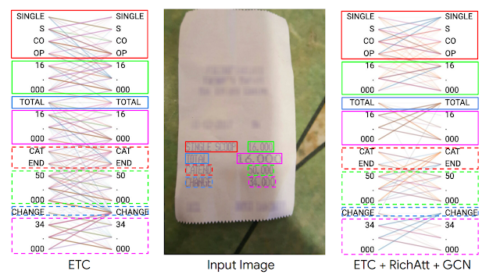
ETCモデルとFormNet(ETC+RichAtt+GCN)モデルの注目度スコア。ETCモデルと異なり、FormNetモデルでは、トークンは同じ視覚ブロック内の他のトークン、および水平に並んだトークンに注意するようになり、構造的手がかりを強く利用するようになりました。
まとめ
本稿では、フォームベースの文書理解のための新しいモデルアーキテクチャであるFormNetを紹介します。新しいRichAtt機構とスーパートークンコンポーネントにより、最適とは言えないノイズの多い逐次処理にもかかわらず、ETC transformerの優れたフォーム理解能力を発揮できることを確認しました。また、FormNetはテキストを直列化する際に失われる可能性のある局所的な構文情報を回復し、3つのベンチマークにおいて最先端の性能を達成することを実証しました。
謝辞
この研究は、Chen-Yu Lee, Chun-Liang Li, Timothy Dozat, Vincent Perot, Guolong Su, Nan Hua, Joshua Ainslie, Renshen Wang, Yasuhisa Fujii, Tomas Pfisterによって実施されました。また、Evan Huang、Shengyang Dai、Salem Elie Haykalには貴重なフィードバックをいただき、Tom Smallにはこの記事のアニメーションを制作していただきました。
3.FormNet:書式に基づいた文書理解を実現(2/2)関連リンク
1)ai.googleblog.com
FormNet: Beyond Sequential Modeling for Form-Based Document Understanding
2)arxiv.org
FormNet: Structural Encoding beyond Sequential Modeling in Form Document Information Extraction

