
1.LiT:画像エンコーダを凍結してマルチモーダルな対象学習の性能を向上(1/2)まとめ
・画像分類などでは事前学習後にタスク毎に微調整に固有データが必要になるので手間がかかる
・代替手法には画像とテキストを使う対照学習があるが微調整手法に比べて性能が劣る
・LiTは事前学習と対照学習による新しいタスクへの柔軟なゼロショット転移を実現する新手法
2.Locked-Image Tuningとは?
以下、ai.googleblog.comより「Locked-Image Tuning: Adding Language Understanding to Image Models」の意訳です。元記事は2022年4月14日、Andreas SteinerさんとBasil Mustafaさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Jakob Owens on Unsplash
画像をカテゴリに分類する能力は、ディープラーニングによって変貌を遂げました。それはまた、転移学習によって著しく加速されました。これにより、モデルはまずImageNetのような大規模なデータセットで事前に訓練されて視覚特徴表現を学習し、その後、より少ないデータで新しいタスク(例えば、動物の分類)に微調整(fine-tuning)し、転移されます。BiTやViTなどの先行研究は、これらの手法を採用し、VTABベンチマークなどの幅広い分類タスクにおいて最先端の性能を達成しています。
しかし、微調整にはいくつかの欠点があります。事前学習(pre-training)は一度だけ行われますが、タスク固有のデータが必要な新しいデータセットごとに微調整が必要です。マルチモーダルな対照学習(contrastive learning)は最近普及した代替パラダイムであり(CLIP、ALIGNなど)、自由形式のテキストと画像のマッチングを学習することにより、これらの問題を克服します。これらのモデルは、画像とテキストのマッチング問題として課題を再定式化することにより、余分なデータなしに新たな課題を解決することができます。(「ゼロショット」学習と呼ばれます)
対照学習は柔軟で新しい課題に対応しやすいですが、対になる画像・テキストデータが大量に必要であり、転移学習に比べて性能が劣るという限界があります。
これらの制限を念頭に置き、私達はCVPR 2022に掲載予定の「LiT: Zero-Shot Transfer with Locked-image Text Tuning」を提案します。LiTモデルは、テキストを訓練済画像エンコーダーにマッチングするように学習します。このシンプルかつ効果的なセットアップは、事前学習による強力な画像特徴表現と、対照学習による新しいタスクへの柔軟なゼロショット転移という、両方の長所を提供します。LiTは最先端のゼロショット分類精度を達成し、2つの学習スタイルの間のギャップを大きく縮めています。この記事の最後に、LiTモデルのデモを掲載しましたので、実際に試してみてください。
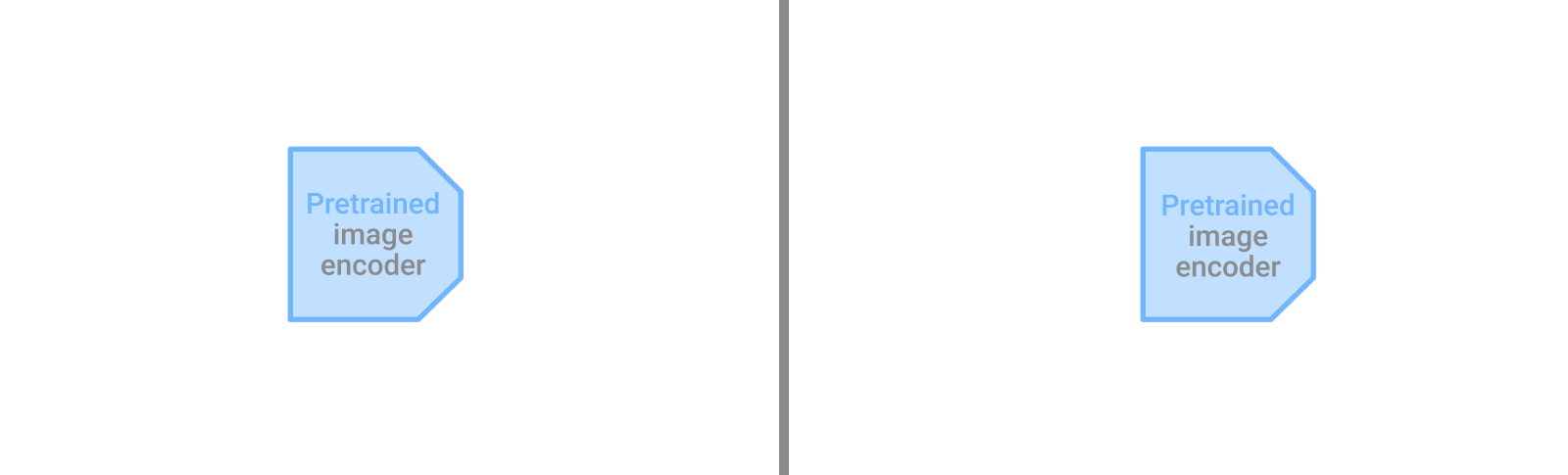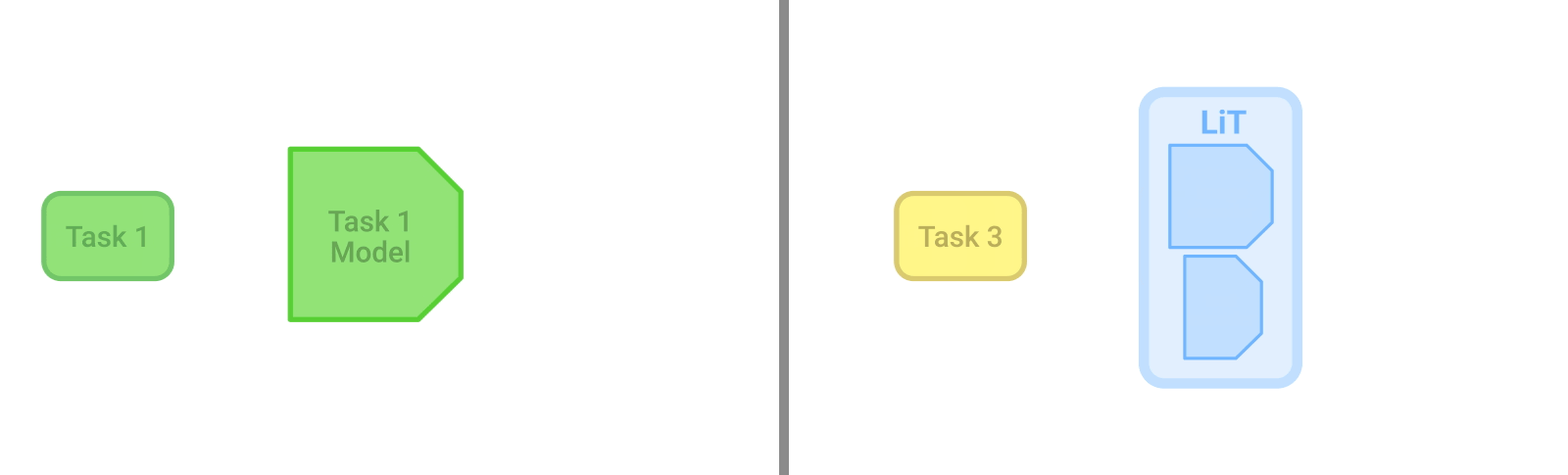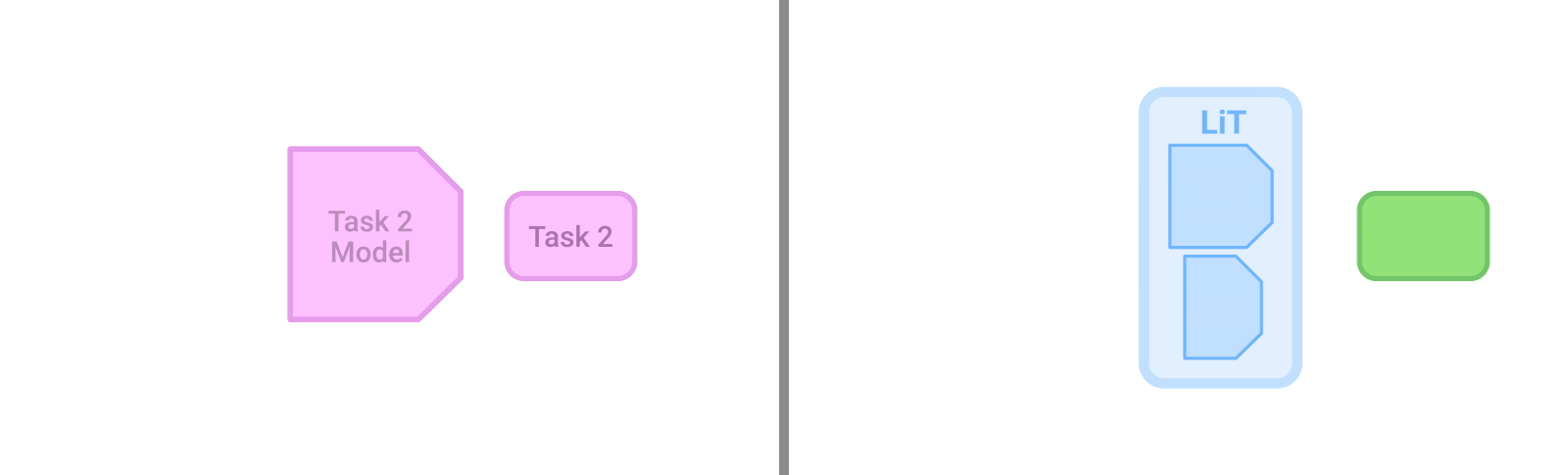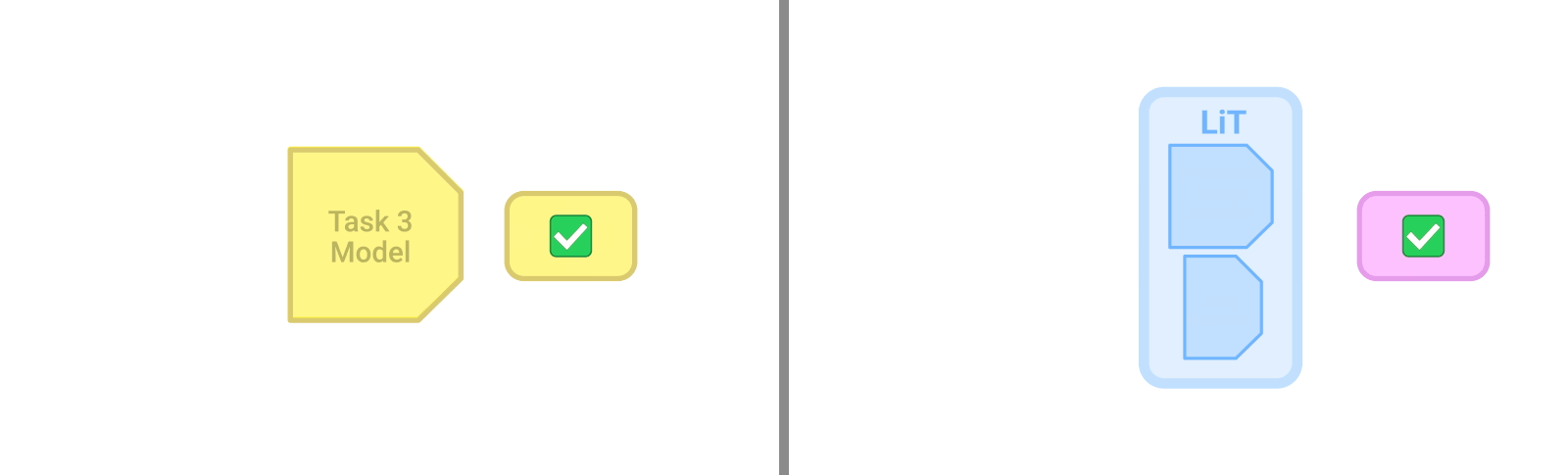
微調整(fine-tuning)は、事前学習(pre-training)したモデルを新しいタスクに適応させるために、タスク固有のデータと学習が必要です。LiTモデル(右)は、どのようなタスクにも対応でき、更なるデータや適応を必要としません。
画像とテキストデータに対する対照学習
対照学習モデルは、「ポジティブ(positive)」な例と「ネガティブ(negative)」な事例を使って特徴表現を学習します。その際、「ポジティブ」な事例に対する特徴表現を互いに似たものにし、「ネガティブ」な事例を異なるようにします。
マルチモーダル対照学習は、これを画像と関連するテキストのペアに適用します。画像エンコーダは画像から特徴表現を計算し、テキストエンコーダはテキストに対して同じことをします。それぞれの画像特徴表現は、関連するテキストの特徴表現(ポジティブ)に近づけ、データ中の他のテキストの特徴表現(ネガティブ)とは遠ざけるように促され、その逆も同様です。これは通常、ランダムに初期化されたモデル(ゼロから学習するモデル)で行われ、エンコーダーは特徴表現とそのマッチング方法を同時に学習しなければならないことを意味します。
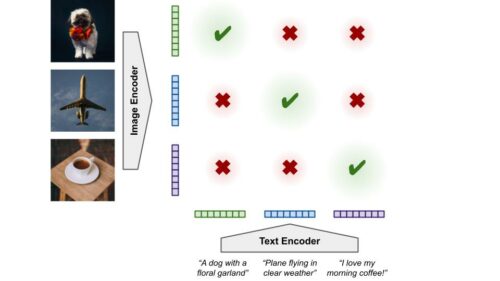
マルチモーダル対照学習は、画像やテキストが密接にマッチした際に、モデルが類似した特徴表現を生成するように訓練します。
この学習は、ウェブ上で自然に発生する、ノイズの多い、厳密な確認をせずともゆるく組み合わせた画像とテキストのペアを用いて行うことができます。これにより、手動でのラベリングが不要になり、データの規模を拡大する事が容易になります。
さらに、このモデルはより豊かな視覚的概念を学習します。つまり、分類ラベル空間で定義されたものに制約されません。例えば、ある画像を「コーヒー」と分類する代わりに、それが「白いマグカップに入った小さなエスプレッソ」なのか「赤い魔法びんに入った大きなラテ」なのかを理解することができるのです。
一度学習した画像とテキストの組み合わせ関係を調整するモデルは、さまざまな方法で使用することができます。ゼロショット分類の場合、画像特徴表現とクラス名のテキスト特徴表現を比較します。例えば、「ウォンバット vs ジャガー」分類器は、テキスト「jaguar」と「wombat」の特徴表現を計算し、その特徴表現が前者によく一致する場合、画像をジャガーと分類することで構築できます。
この方法は、何千ものクラスに対応でき、微調整に必要な余分なデータなしに、分類タスクを非常に簡単に解決することができます。対照モデルのもう一つの応用は画像検索(別名、画像-テキスト検索(image-text retrieval))で、与えられたテキストの特徴表現と最もよく一致する画像、あるいはその逆を見つけることです。
3.LiT:画像エンコーダを凍結してマルチモーダルな対象学習の性能を向上(1/2)関連リンク
1)ai.googleblog.com
Locked-Image Tuning: Adding Language Understanding to Image Models
2)arxiv.org
LiT: Zero-Shot Transfer with Locked-image text Tuning
3)google-research.github.io
LiT: Zero-Shot Transfer with Locked-image Tuning

