
1.ALX:大規模な行列計算をTPU上で実現(2/3)まとめ
・ALXは各TPUコアの計算能力とメモリが無駄にならないように設計を工夫している
・デモ用にWebGraphと呼ばれる大規模な実世界のウェブリンク予測データセットを公開
・WebGraphは簡単にアクセスできるように、Tensorflow Datasetパッケージとして提供
2.WebGraphとは?
以下、ai.googleblog.comより「Large-Scale Matrix Factorization on TPUs」の意訳です。元記事は2022年4月8日、Harsh Mehtaさんによる投稿です。
映画のMatrix(行列)をイメージしたアイキャッチ画像のクレジットはPhoto by Brian Wangenheim on Unsplash
embeddingテーブルを一様にシャーディング
バッチングの問題が解決されたので、次に、疎な行列を2つの密なembedding行列(例えば、ユーザーとアイテムのembedding)に分解し、結果として得られるembedding行列の内積が元の疎行列に近似するようにしましょう。
これが出来れば元の行列から空の位置を含む全ての位置を推論する事が出来るので、ユーザーが触れた事のないアイテムを推薦するために使用することなどができます。
結果として得られるembeddingテーブル(下図のWとH)は、どちらも単一のTPUコアに収まらないほど大きくなる可能性があるため、ほとんどの大規模ユースケースでは分散学習設定が必要になります。
これまでのほとんどの分散型の行列分解では、パラメータサーバーアーキテクチャが採用されています。パラメータサーバーアーキテクチャでは、モデルパラメータを高可用性サーバーに格納し、学習データを学習タスクのみを担当するワーカー群によって並列処理します。
私達の場合、各TPUコアが同一の計算能力とメモリを持つため、メモリのみを使ってモデルパラメータを格納、または計算能力のみを使って学習を行わせるのは、どちらかしか使わない事になり無駄が多くなります。そこで、各コアで両方の処理を行うようにシステムを設計しました。
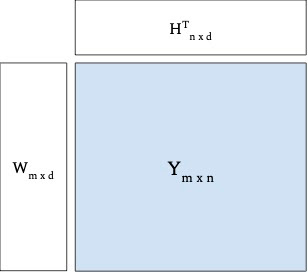
疎行列Yを2つの密な埋め込み行列WとHに因数分解する図解例
ALXでは、両方のembeddingテーブルを一様に分割することで、利用可能な分散メモリのサイズとTPU間の専用の低遅延中間接続の両方を十分に活用します。これは、非常に大きなembeddingテーブルに対して非常に効率的であり、配分集約操作および配分分散操作に対して良好な性能をもたらします。
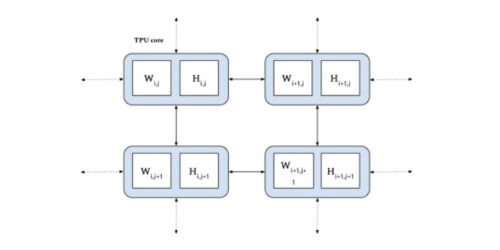
両埋embeddingテーブル(WとH)をTPUコア(青色)間で一様にシャーディング
WebGraph
行列分解は非常に大きなデータセットを扱う可能性があるため、規模の拡大が出来るか否かは行列分解を発展させる上で重要になる可能性があります。
このため、私達はWebGraphと呼ばれる大規模な実世界のウェブリンク予測データセットを公開します。このデータセットは、行と列がそれぞれリンク元とリンク先を表す行列分解問題として簡単にモデル化でき、タスクは各リンク元からリンク先を予測することです。私達はWebGraphを使い、ALXのスケーリング特性を説明します。
WebGraphデータセットは、2021年にCommonCrawlによって行われた1回のクロールから生成されたもので、すべてを取り除き、リンク->アウトリンクのデータのみを残しています。因数分解の性能はグラフの特性に依存するため、疎なパターンと国を変えた6つのバージョンのWebGraphを作成し、ALSがそれぞれでどの程度の性能を持つかを調べました。
・各言語に特化したグラフを研究するために、2つのトップレベルドメインに基づいてフィルタリングを行っています。ドイツ(.de)とインド(.in)の2つのトップレベルドメインに基づいてフィルタリングし、それぞれノード数が一桁少ないグラフを生成しました。
・これらのグラフはまだ任意の疎なパターンやリンク切れリンクを持つことができます。そこで、各グラフのノードをさらにフィルタリングして、最低10または50のインリンクとアウトリンクを持つようにします。
簡単にアクセスできるように、Tensorflow Datasetパッケージとして提供しています。参考までに、最大のバージョンであるWebGraph-sparseは、3億6500万以上のノードと300億以上のエッジを持っています。評価用にトレーニング用とテスト用の分割を作成し公開しています。
3.ALX:大規模な行列計算をTPU上で実現(2/3)関連リンク
1)ai.googleblog.com
Large-Scale Matrix Factorization on TPUs
2)arxiv.org
ALX: Large Scale Matrix Factorization on TPUs
3)github.com
google-research/alx/
4)www.tensorflow.org
web_graph
