
1.モデルのアンサンブルは貴方が思っているよりも凄い(2/2)まとめ
・モデルカスケードはアンサンブルの早期終了を可能にするため計算量を節約できる場合がある
・カスケードは調査した全ケースで単一モデルよりも優れた性能を示し速度や精度が向上
・畳み込みモデル以外にTransformerモデルでもであるViTでもカスケードの有用性を実証
2.モデルのカスケード
以下、ai.googleblog.comより「Model Ensembles Are Faster Than You Think」の意訳です。元記事の投稿は2021年11月10日、Xiaofang WangさんとYair Alonさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Judi Neumeyer on Unsplash
モデルカスケードの実力とシンプルさ
これまでモデルのアンサンブルの有用性を実証してきましたが、アンサンブル内のモデルの一部だけで正しい答えを出せるような簡単な入力では、アンサンブルの適用はしばしば無駄になります。
このような状況では、モデルカスケードが計算量を節約することができます。カスケードは早期の終了を可能にし、すべてのモデルが使用される前に停止して答えを出力することができるためです。問題は、カスケードから抜けるタイミングを決めることです。
カスケードの実用的な利点を強調するために、予測の信頼性を測定するために、意図的に単純な経験則を採用しいした。例えば、ある画像が猫、犬、馬のいずれかであると予測される確率が、それぞれ20%、80%、20%であった場合、モデルの予測(犬)の信頼度は0.8となります。信頼度のスコアに閾値を設け、カスケードから抜けるタイミングを決定します。
このアプローチを検証するために、EfficientNet、ResNet、MobileNetV2群のモデルカスケードを、計算コストと精度のどちらかに合わせて構築しました。(カスケードは最大4つのモデルまでに制限しました)。
カスケードは、難易度の高い入力は簡単な入力よりも多くのモデルを経由するように設計されているため、一部の入力では他の入力よりもFLOPSが高くなります。そのため、すべてのテスト画像について計算した平均FLOPSを報告します。
その結果、カスケードは、すべての計算領域(FLOPSが1億5千万から370億の範囲)において、単一モデルよりも優れた性能を示し、テストしたすべてのモデルにおいて、精度を向上させるか、FLOPSを低減させるか(場合によってはその両方)が可能であることがわかりました。
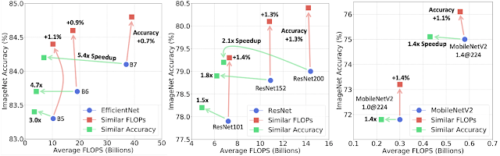
ImageNetにおけるEfficientNet(左)、ResNet(中)、MobileNetV2(右)の各モデルのカスケード
同程度のFLOPSを使用した場合、カスケードは単一モデルよりも高い精度を得ることができます(上向きの赤い矢印で示します)。カスケードは、例えばB7では5.4倍など、大幅に少ないFLOPSで単一モデルと同等の精度を得ることができます(左を向きの緑色の矢印で示します)
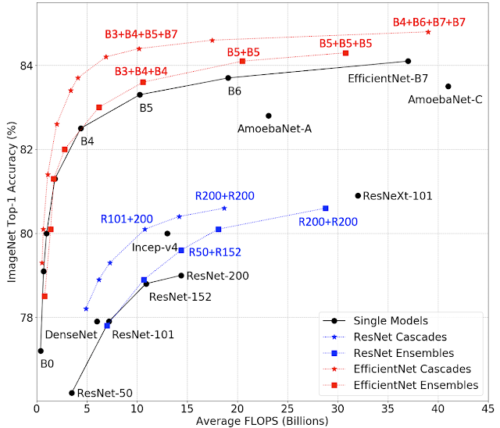
アンサンブルとカスケードの精度とFLOPSの関係をまとめたグラフ
四角はアンサンブル、星はカスケードを表しており、「+」表記はアンサンブルやカスケードを構成するモデルを示しています。例えば、星印の「B3+B4+B5+B7」は、EfficientNet-B3、B4、B5、B7モデルのカスケードを意味します。
場合によっては、平均的な計算コストではなく、最悪のケースのコストが制限要因となることもあります。カスケード構築手順に簡単な制約を加えることで、カスケードの計算コストに上界を保証することができます。詳しくは論文をご覧ください。
畳み込みニューラルネットワーク以外にも、TransformerベースのアーキテクチャであるViTも考慮しています。ViT-BaseモデルとViT-Largeモデルでカスケードを構築することで、1つの最先端のViT-Largeモデルの平均計算量や精度と一致させる事ができます。つまり、カスケードの利点がTransformerベースのアーキテクチャにも一般化することを示します。
| Single Models | Cascades – Similar Throughput | Cascades – Similar Accuracy | ||||||
| Top-1 (%) | Throughput | Top-1 (%) | Throughput | △Top-1 | Top-1 (%) | Throughput | SpeedUp | |
| ViT-L-224 | 82 | 192 | 83.1 | 221 | 1.1 | 82.3 | 409 | 2.1x |
| ViT-L-384 | 85 | 54 | 86 | 69 | 1 | 85.2 | 125 | 2.3x |
ImageNetにおけるViTモデルのカスケード。「224」と「384」は、モデルの学習対象となる画像の解像度を示します。応答速度は1秒間に処理された画像の数として測定されます。私達のカスケードは、同程度の応答速度でViT-L-384よりも1.0%高い精度を達成したり、同程度の精度で2.3倍のスピードアップを達成したりすることができます。
カスケードに関する以前の研究でも、最先端のモデルを用いて効率化を図っていましたが、ここでは、少数のモデルを用いたシンプルなアプローチで十分であることを示しています。
予測速度
今までの分析では、計算コストを測定するためにFLOPSを平均しています。ここで、カスケードによって得られたFLOPSの削減が、実際にハードウェア上のスピードアップにつながることを確認することも重要です。
これを同程度の性能を持つシングルモデルとカスケードモデルのオンデバイスでの応答速度とスピードアップを比較して検証しました。
その結果、EfficientNetファミリのモデルをカスケード接続した場合、TPUv3上での平均応答速度が、同等の精度を持つ単一モデルと比較して最大5.5倍減少することがわかりました。モデルが大きくなればなるほど、同等のカスケードではより高速化されることがわかります。
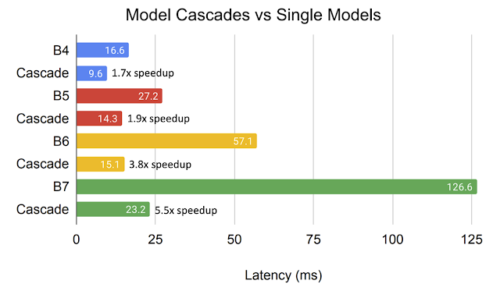
TPUv3におけるオンライン処理のカスケードの平均応答時間
同じ色のバーのペアはそれぞれ同等の精度を持ちます。カスケードによって大幅に応答時間が短縮されていることがわかります。
多数の候補モデルからのカスケードを構築
今までの説明では、モデルの種類を限定し、最大でも4つのモデルのアンサンブル/カスケードのみを検討しました。これは、アンサンブルを使用することのシンプルさを強調するためですが、その一方、全てのモデルの組み合わせをわずかな時間でチェックできるため、検証セットを使ったものであれば、わずか数時間のCPU時間で最適なモデル群を見つけることができます。
多数の候補モデルが存在する場合、カスケードはさらに効率的で正確になることが期待できますが、ブルートフォース検索(総当り検索)は実現不可能です。しかし、効率的なカスケード探索法は提案されています。
例えば、Streeter(2018)のアルゴリズムは、大規模な候補モデル群に適用すると、最先端のニューラルアーキテクチャ検索ベースのImageNetモデルの精度に匹敵するカスケードを、大幅に少ないFLOPSで生成しました。様々なモデルサイズでこれを実現できています。
まとめ
これまで見てきたように、アンサンブル/カスケードベースのモデルは、いくつかの標準的なアーキテクチャ群の最先端のモデルよりも優れた効率と精度を得ることができます。
本論文では、他のモデルやタスクについても結果を示しています。実務者にとっては、利用可能なモデルを用いて効率性を維持しながら精度を向上させるための簡単な手順が紹介されています。
ぜひ、試してみてください!
謝辞
このブログでは、Xiaofang Wang(Google Research でインターン中),Dan Kondratyuk, Eric Christiansen, Kris M. Kitani, Yair Alon (旧 Movshovitz-Attias), Elad Eban による研究を紹介しています。また、Sergey Ioffe, Shankar Krishnan, Max Moroz, Josh Dillon, Alex Alemi, Jascha Sohl-Dickstein, Rif A Saurous, 及び Andrew Heltonの各氏には、貴重なご協力とご意見をいただきました。
3.モデルのアンサンブルは貴方が思っているよりも凄い(2/2)関連リンク
1)ai.googleblog.com
Model Ensembles Are Faster Than You Think
2)arxiv.org
Wisdom of Committees: An Overlooked Approach To Faster and More Accurate Models

