
1.人工知能に皮肉を理解させるまとめ
・人工知能に皮肉や風刺を理解させるのは重要だが困難な課題である
・皮肉をストレートに受け取ると感情分析やAffective computingが大きな誤動作をしてしまう
・個人特性や感情、情緒に注目して皮肉を理解させる新手法が発表された
2.人工知能に皮肉を検出させるために必要な事
Affective computing(感情コンピューティング:人工知能に感情を理解 or 実装させる試み)や感情分析などの他の分野では、文章が正反対の意味を持つようになるため、皮肉の検出は重要です。
論文「A Deeper Look into Sarcastic Tweets Using Deep Convolutional Neural Networks」では、畳み込みネットワーク(CNN)の組み合わせを用いてNLP(自然言語解析)の重要な問題である皮肉検出に取り組んでいます。Affective computingや感情分析などの研究分野では皮肉が検出できないと正反対の結論を出してしまうため、皮肉を検出する事は重要になります。
皮肉の例
皮肉や風刺は苦い気分や気晴らしを表現するものとみなすことができます。例として「この時間は貴方のお薬の時間ですか?それとも私のですか?」「私は貧乏になるため週40時間働いている」など
皮肉を理解する挑戦
皮肉を理解して検出するには、事象に関連する事実を理解することが重要です。これは、客観的な特性(通常はネガティブ)と作者が伝える皮肉な特性(通常はポジティブ)間の矛盾を検出することで可能になります。
“私は崩壊の痛みが大好き”という例を考えてみましょう。この声明に皮肉があるかどうかを知るために必要な知識を抽出するのはなかなか難しいです。この例では、「私は痛みが大好きです」は、作者によって表現された感情(この場合はポジティブ)を表現し、「崩壊」は矛盾する感情(ネガティブなもの)を表します。
風刺的な表現を理解する上での他の課題は、複数の事象への言及、大量の事実、常識的な知識、言い換えの解決、および論理的な推論を抽出する必要があることです。著者は上記の特徴を自動的に抽出させるのではなく、CNNsを利用して、皮肉のデータセットから特徴を自動学習させました。
この論文の趣旨
・皮肉の検出にディープラーニングを使った
・ユーザのプロファイル、感情、情緒を皮肉検出のために利用
・特徴量を自動抽出するために事前も訓練したモデルを利用
事前訓練モデル
感情の変化は、皮肉に関連したコミュニケーションによく見られます。したがって、著者らは、情緒特有の特徴量抽出を学習するために(CNNに基づく)感情モデルを最初に訓練することを提案しています。モデルは、下位層の局所的特徴を学習し、上位層の大域的特徴に変換されます。著者は、皮肉な表現はユーザー固有のものであり、一部のユーザーは他のユーザーよりも皮肉な意見を沢山言う傾向があると述べています。
論文中で考案されたフレームワークでは、パーソナリティベースの特徴、情緒特徴、および感情ベースの特徴が皮肉検出フレームワークに組み込まれています。各フィーチャセット(特徴セット)は別々のモデルで学習され、皮肉データセットから皮肉に関連する特徴を抽出するために使用される学習モデルの事前トレーニングとなります。
CNNフレームワーク
CNNは、細かい特徴がより大きな特徴に繋がる階層的構造をモデリングするのに有効で、これは、文脈を学習するために不可欠です。文章は小さい単語ベクトルが集まって大きな文章として表現されるためです。Googleのword2vecベクトルを入力データ作成に使用しました。これらの単語ベクトルのパラメータはトレーニング段階で学習されます。
次に、Max poolingを用いて特徴量を生成し、中間層を経て、最終的な予測を出力するためのソフトマックス層が続きます。
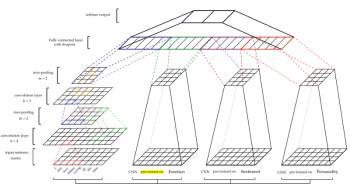
情緒(S)、感情(E)、およびパーソナリティ(P)の特徴を得るために、CNNモデルは事前に訓練され、皮肉のデータセットから特徴を抽出するために使用されました。
純粋なCNN分類器(CNN)とCNN-SVM分類器(CNNが抽出した特徴をSVMの入力に使ったモデル)の2つの分類器がテストされました。
別のモデル(つまり、感情や情緒やパーソナリティ)を組み入れないCNNモデルのみからなるベースライン分類器(B)も同様に訓練しました。
実験
使用データ Balanced and imbalanced sarcastic tweets datasets(Ptacek 他 2014)とThe Sarcasm Detectorから皮肉学習用のツイートデータセットを得ました。
ユーザー名、URL、およびハッシュタグが削除され、NLTK Twitterトークナイザをトークン化に使用しました。
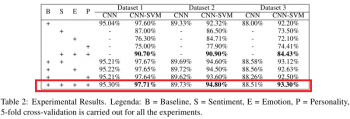
すべてのデータセットにCNNとCNN-SVMの分類器を適用した場合のパフォーマンスを下の表に示します。モデル(特にCNN-SVM)が皮肉の特徴B、感情の特徴E、情緒の特徴S、およびパーソナリティの特徴Pと共に組み合わせたとき、他のすべてのモデルよりも優れていることがわかります。
最先端のモデル(上段)、他のよく知られている皮肉探出研究(中段)、今回発表したモデル(下段)の比較結果を以下に示します。今回提案した論文のモデルは、他のすべてのモデルより一貫して優れた結果を示しました。
モデルの汎化能力もテストされました。主な発見は、データセットが本質的に異なる場合、結果に大きな影響を与えるということでした。 (下記のPCAを介してレンダリングされたデータセットの視覚化を参照)。たとえば、トレーニングをデータセット1で行い、データセット2でテストした場合、モデルのF1スコアは33.05%であり、精度が著しく低下してしまいました。

結論と今後の課題
著者らは、皮肉はトピック依存性と文脈依存性が高いことを発見し、感情などの文脈上の手がかりがテキストの皮肉を検出するのに役立つと結論づけました。事前訓練された情緒、感情、およびパーソナリティモデルは、文脈からの情報を取り込むために有用です。
手作りの特徴(例えば、nグラム)は、皮肉検出に幾分有用です、非常に疎な特徴ベクトル表現を生成します。これらの理由から、人力で作った特徴量より単語ベクトルを入力特徴として使用する事は適切です。
3.人工知能に皮肉を検出させるために必要な事感想
ヒントン教授は、「人工知能はアメリカ人より先に皮肉を理解できるようになるだろう」と皮肉を言っていたのですが、アレは皮肉ではなくて客観的観測に基づく意見表明だったのでしょうか。(そうとは思いませんが)
皮肉の例として上げられている「この時間は貴方のお薬の時間ですか?それとも私のですか?」は原文だと「Is it time for your medication or mine?」なのですが、正直、これがどんな文脈で使われて皮肉になるのか漠然とした想像レベルでしかできません。人間でも難しいレベルの皮肉を人工知能が理解し始めているとは、これも皮肉に感じます。
アンケートや世論、感想を集計する際に皮肉が障害になる事は良く知られていますが、感情やパーソナリティをベースにするのは優れたアイディアと思いました。ただ現実的には、大半のケースで集めた感想やアンケートはパーソナリティがわからないように個人情報を削除してから使われるので質問を作成する際の設問に工夫しないと応用が難しいかもな、とも思います。
4.人工知能に皮肉を検出させるために必要な事関連リンク
1)www.kdnuggets.com
Detecting Sarcasm with Deep Convolutional Neural Networks
2)arxiv.org
A Deeper Look into Sarcastic Tweets Using Deep Convolutional Neural Networks
3)www.reddit.com
Detecting Sarcasm with Deep Convolutional Neural Networks

