
1.BERTは文法を理解しているのか?頻度を見ているだけなのか?(1/2)まとめ
・言語モデルは機能する理由が不透明な事が多く更なる改善の妨げになっている
・英語の主語と動詞の一致規則を正しく適用するBERTモデルの能力を調査した
・初見の主語と動詞のペアに対して良好な成績を達成したが頻度の影響を受けた
2.言語モデルの構文能力を評価する
以下、ai.googleblog.comより「Evaluating Syntactic Abilities of Language Models」の意訳です。元記事の投稿は2021年12月2日、Jason WeiさんとDan Garretteさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Ashes Sitoula on Unsplash
近年、BERTやGPT-3などの事前にトレーニングされた言語モデルが、自然言語処理(NLP:Natural Language Processing)で広く使用されています。大量のテキストをトレーニングすることで、言語モデルは世界に関する幅広い知識を習得し、さまざまなNLPベンチマークで強力なパフォーマンスを実現します。
ただし、これらのモデルは、なぜそれほどうまく機能するのかが不透明であることが多く、これにより、仮説に基づいてモデルを更に改善する事に限界が生まれています。
そこで、「これらのモデルにはどのような言語的知識が含まれているのだろうか?」という新たな科学的探究が始まりました。
言語に関する知識にはさまざまなものがありますが、分析の有力な基礎となるのは、英語の「主語と動詞の一致」という文法規則です。これは、動詞の文法上の単数形or複数形が主語の単数形or複数形と一致することを要求するものです。
例えば、「The dogs run.」という文は 「dogs」と「run」がともに複数形なので文法的に正しいですが、「The dogs runs.」は「runs」が単数形なので文法を無視(ungrammatical)しています。
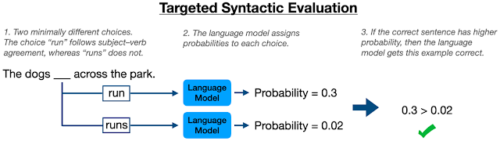
このような言語モデルの言語知識を評価するフレームワークの1つに、ターゲット構文評価(TSE:Targeted Syntactic Evaluation)があります。
これは、「文法的に正しい文」と「文法を無視した文」のペアがモデルに表示され、モデルがどちらが文法的に正しいかを判断するテストです。
以上の背景から、EMNLP2021で発表した「Frequency Effects on Syntactic Rule-Learning in Transformers」では、英語の主語と動詞の一致規則を正しく適用するBERTモデルの能力が、事前学習時にモデルが見た単語の回数にどのように影響を受けているかを調査しました。
特定の条件をテストするために、慎重に制御されたデータセットを用いて、BERTモデルを一から事前学習しました。その結果、BERTは事前学習データ内で一緒に出現しない主語と動詞のペアに対して良好な成績を達成しました。
これは、BERTが主語と動詞の一致を学習していることを示しています。しかし、このモデルは、正しい形式よりも誤った形式の方がはるかに頻繁に現れる場合、誤った形式を予測する傾向があり、これはBERTが文法的一致を従うべき規則として扱っていないことを示しています。これらの結果は、事前学習した言語モデルの長所と限界をよりよく理解するのに役立ちます。
先行研究
これまでの研究では、BERTモデルで英語の主語と動詞の一致能力を測定するためにTSEを使用していました。この設定では、BERTは与えられた動詞の単数形と複数形(例えば、「runs」と「run」)の両方に確率を割り当てることによって、空欄補充タスク(例えば、「the dog ____ across the park」)を実行します。
もしモデルが主語と動詞の一致規則を正しく学習していれば、文法的に正しい文章を作る方の動詞形式に高い確率を一貫して割り当てるはずです。
以前の研究では、自然文(natural sentences、ウィキペディアから抽出)とノンス文(nonce sentences、文法的には正しいが意味をなさないように人為的に作られた文、例えばNoam Chomskyの有名な例「colorless green ideas sleep furiously.(無色の緑のアイディアは激しく眠る)」)の両方を使用してBERTを評価しています。
ノンス文は、モデルが表面的なデータの統計情報に頼ることができないため、構文能力をテストする際に有用です。
例えば、「dogs run」は「dogs runs」よりもはるかによく使われますが、「dogs publish」と「dogs publishes」は両方とも非常にまれです。したがって、モデルは単にどちらかが他よりも可能性が高いという事実を記憶しているわけではありません。
BERTはノンス文に対して80%以上の精度(ランダム選択時の基準値50%よりはるかに良い)を達成し、これはモデルが主語と動詞の一致規則を適用することを学習した証拠とされました。本論文では、この先行研究を超えて、特定のデータ条件でBERTモデルを事前学習させることで、事前学習データの特定のパターンがパフォーマンスにどのような影響を与えるか、この結果をより深く掘り下げることができました。
3.BERTは文法を理解しているのか?頻度を見ているだけなのか?(1/2)関連リンク
1)ai.googleblog.com
Evaluating Syntactic Abilities of Language Models
2)arxiv.org
Frequency Effects on Syntactic Rule Learning in Transformers

