
1.FLAN:指示調整により初見タスク実行能力を向上した言語モデル(1/2)まとめ
・モデルが意味のある文章を生成するためには現実世界の知識と物事を抽象化する能力が必要
・モデルは規模拡大するとこれらの知識を自動的に取得するが条件は明確にわかっていない
・FLANは指示調整と呼ぶ新しい調整法で初見タスクへの対応能力を向上する事を目指す新手法
2.FLANとは?
以下、ai.googleblog.comより「Introducing FLAN: More generalizable Language Models with Instruction Fine-Tuning」の意訳です。元記事は2021年10月6日、Maarten BosmaさんとJason Weiさんによる投稿です。
FLANとはアイキャッチ画像にあるようなタルト的なデザートの事です。トップ部分のデコレーションがないのがケーキと異なり、内部には砂糖的な甘みではなく、チーズやフルーツなどを入れるそうです。
アイキャッチ画像のクレジットはPhoto by Daniel J. Schwarz on Unsplash
2023年2月追記)データセットとしてのFLANを更に充実させたFlan Collectionが発表されています。
機械学習モデルが意味のある文章を生成するには、現実世界に関する大量の知識と物事を抽象化する能力が必要です。これを行うように訓練された言語モデルは、モデルの規模を拡大するにつれてこれらの知識を自動的に取得するようになります。しかし、どうやれば規模拡大以外の手法でこれらの知識を意図的に学習させて特定の実務的なタスクを実行させる事ができるようになるのかは明確ではありません。
確立された手法の1つは、微調整(fine-tuning)と呼ばれます。これは、ラベル付きデータセットでBERTやT5などの事前トレーニング済みモデルをトレーニングして、下流タスクに適応させることです。ただし、微調整では、下流タスクごとにモデルの重みを保存する事が必要になるとともに、多数のトレーニングデータが必要です。これは、特に大規模なモデルの場合、常に実用的な解決策になるとは限りません。
論文「Fine-tuned Language Models Are Zero-Shot Learners」では、「指示微調整(instruction fine-tuning)」、または略して「指示調整(instruction tuning)」と呼ぶシンプルな手法を検討します。
これには、特定のタスクを解決するのではなく、一般的なNLPタスクをより受け入れやすくし、解決しやすくするようにモデルを微調整することが含まれます。
私達は指示調整を使用してモデルをトレーニングしました。このモデルをFLAN(Fine-tuned LAnguage Net)と呼んでいます。
FLANの指示調整フェーズは、モデルの事前トレーニングに伴う大量の計算と比較して、更新数が少ないです。つまり、FLANの名称は事前トレーニングを主菜とすれば、デザート的な位置づけになる事を比喩的に表現しています。
FLANはさまざまなやった事のないタスクを実行できます。

FLANの概要図
モデルは、異なる一連の指示で微調整され、今までやった事のない指示にも一般化できます。より多くのタイプのタスクが微調整データモデルに追加されると、パフォーマンスが向上します。
背景
言語モデルを使用してタスクを解決する最近の一般的な手法の1つは、ゼロショット(zero-shot)または少数ショットプロンプト(few-shot prompting)と呼ばれます。
この手法は、言語モデルがトレーニング中に見た可能性のあるテキストに基づいてタスクを定式化し、言語モデルがテキストを完成させることによって回答を生成します。
たとえば、映画レビューの感情を分類する際は、言語モデルに
「『プリティウーマン以来の最高のロマンティック・コメディ』と言う映画のレビュー文はXXXです」
という文が与えられ、XXXを「肯定的評価(positive)」または「否定的評価(negative)」のどちらかで埋めて文を完成するように求めます。
この手法は一部のタスクで優れたパフォーマンスを示しますが、トレーニング中にモデルが見たデータのように見えるようにタスクを設計するために、慎重に入力として与える表現を工夫する必要があり、これをプロンプトエンジニアリングと言います。
プロンプトエンジニアリングは全てではありませんが一部のタスクでうまく機能する可能性があるアプローチです。しかし、モデルと対話するやり方としては直感的でないため実践が難しい場合もあります。
たとえば、GPT-3(現在使用されている最大の言語モデルの1つ)の開発者は、そのようなプロンプトの表現を工夫する手法では自然言語推論(NLI:Natural Language Inference)タスクのパフォーマンスが向上しないことを発見しました。
指示調整(Instruction Tuning)
代わりに、FLANは、さまざまな指示の大規模なセットでモデルを微調整します。「この映画レビュー文を肯定的評価または否定的評価に分類する」、「この文をデンマーク語に翻訳する」など、タスクのシンプルで直感的な説明を使用します。
モデルを微調整するために最初から命令のデータセットを作成するには、かなりの量のリソースが必要になります。したがって、代わりにテンプレートを使用して、既存のデータセットを命令形式に変換します。
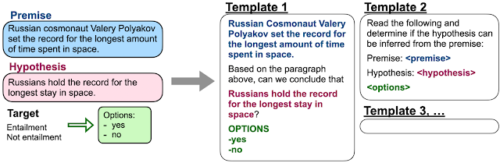
自然言語推論データセットのテンプレートの例
これらの指示でモデルをトレーニングすることにより、トレーニング中に見た種類の指示を解決するのが得意になるだけでなく、一般的な指示に従うのも上手になることを示します。
3.FLAN:指示調整により初見タスク実行能力を向上した言語モデル(1/2)関連リンク
1)ai.googleblog.com
Introducing FLAN: More generalizable Language Models with Instruction Fine-Tuning
2)arxiv.org
Finetuned Language Models Are Zero-Shot Learners
3)github.com
google-research / FLAN

