
1.CoAtNets:畳み込みと自己注意の利点を備えたハイブリッドモデル(1/2)まとめ
・モデルとデータサイズが大きくなるにつれてトレーニング効率が重要な焦点になりつつある
・ニューラルアーキテクチャ探索を活用して画像認識用のモデルを2種を開発した
・EfficientNet V2は比較的小規模なデータで高速トレーニングを可能とするニューラルネット
2.EfficientNetV2とは?
以下、ai.googleblog.comより「Toward Fast and Accurate Neural Networks for Image Recognition」の意訳です。元記事の投稿は2021年9月16日、Mingxing TanさんとZihang Daiさんによる投稿です。
EfficientNetV2は発表されたのはまだ半年も経っていない2021年4月ですが、トレーニングの効率が向上して使いやすくなっているので既にバリバリ使われており、今更紹介感が出てしまうのがAI界隈の進化の速さだなぁ、と改めて思います。
Coatを意識したアイキャッチ画像のクレジットはPhoto by marco xu on Unsplash
ニューラルネットワークモデルと学習用データのサイズが大きくなるにつれて、トレーニングの効率が深層学習の重要な焦点になりつつあります。たとえば、GPT-3は少数ショット学習(few-shot learning)で優れた機能を発揮しますが、数千のGPUを使用した数週間のトレーニングが必要であるため、再トレーニングや改善が困難です。代わりに、より小さく、より高速でありながら、さらに正確なニューラルネットワークを設計できるとしたらどうでしょうか?
この投稿では、ニューラルアーキテクチャ探索を活用する画像認識用のモデルの2つの系統と、モデル容量と一般化に基づく原理的な設計方法論を紹介します。
1つ目はEfficientNet V2(ICML 2021で受理)です。これは、ImageNet1k(128万枚の画像)などの比較的小規模なデータセットの高速トレーニングを目的とした畳み込みニューラルネットワークで構成されています。
2番目の系統はCoAtNetです。これは、畳み込み(Convolutional Neural Network)と自己注意(self-attention)を組み合わせたハイブリッドモデルであり、ImageNet21(1,300万枚の画像)やJFT(数十億枚の画像)などの大規模なデータセットでより高い精度を実現することを目的としています。以前の結果と比較して、私達のモデルは4~10倍高速であり、定評のあるImageNetデータセットで最新の90.88%のtop 1精度を達成しています。また、Google AutoML githubでソースコードと事前トレーニング済みモデルをリリースしています。
EfficientNetV2:より小さなモデルとより迅速なトレーニング
EfficientNetV2は、以前のEfficientNetアーキテクチャに基づいています。
オリジナルのEfficientNetを改善するために、最新のTPU/GPUでのトレーニング速度のボトルネックを体系的に調査し、次のことを発見しました。
(1)非常に大きな画像サイズでトレーニングすると、メモリ使用量が多くなり、TPU / GPUでは遅くなることがよくあります。
(2)広く使用されている深さ方向の畳み込みは、ハードウェアの使用率が低いため、TPU / GPUでは非効率的です。
(3)畳み込みネットワークのすべての段階を均等にスケールアップする、一般的に使用される「均一複合スケーリングアプローチ(uniform compound scaling approach)」は最適ではありません。
これらの問題に対処するために、最適化目標にトレーニング速度の向上が含まれる「トレーニング対応ニューラルアーキテクチャ探索(training-aware Neural Architecture Search)」と、さまざまなステージを不均一に拡大する拡大手法の両方を提案します。
トレーニング対応ニューラルアーキテクチャ探索は以前のプラットフォーム対応ニューラルアーキテクチャ探索(platform-aware NAS、クラウド上で実行する用途に最適化したりスマホ上で実行する用途に最適化したり用途別に最適化するためのNAS)に基づいていますが、主に推論速度向上に焦点を当てている元のアプローチとは異なり、モデルの精度、モデルのサイズ、トレーニング速度を共同で最適化します。
また、元の探索スペースを拡張して、FusedMBConvなどのよりアクセラレータに適した操作を含め、NASによって選択されることのない平均プーリング(average pooling)や最大プーリング(max pooling)などの不要な操作を削除することで探索スペースを簡素化します。結果として得られるEfficientNetV2ネットワークは、以前のすべてのモデルよりも精度が向上し、はるかに高速で最大6.8分の1に小さくなります。
トレーニングプロセスをさらに高速化するために、トレーニング中に画像サイズと正則化の大きさを徐々に変更する、漸進学習(progressive learning)も提案します。プログレッシブトレーニングは、画像分類、GAN、および言語モデルで使用されています。
このアプローチは画像分類に焦点を当てていますが、精度が向上してもトレーニング速度が遅くなる事が多い従来のアプローチとは異なり、トレーニング時間を大幅に短縮しながら精度をわずかに向上させることができます。
改善されたアプローチの重要なアイデアは、画像サイズに応じて、ドロップアウト率やデータ拡張の大きさなどの正則化強度を適応的に変更することです。同じネットワークの場合、画像サイズが小さいとネットワーク容量が少なくなるため、弱い正則化が必要になります。逆に、画像サイズが大きいと、過剰適合に対抗するために、より強力な正則化が必要になります。

EfficientNetV2の漸進学習。ここでは主に、データ増強、mixup、ドロップアウトの3種類の正則化に焦点を当てます。
ImageNetでEfficientNetV2モデルを評価し、CIFAR-10/100、Flowers、Carsなどのいくつかの転移学習データセットを評価しました。ImageNetでは、EfficientNetV2は、精度を低下させることなく、トレーニング速度が約5~11倍速く、モデルサイズが最大6.8倍小さいため、以前のモデルを大幅に上回っています。
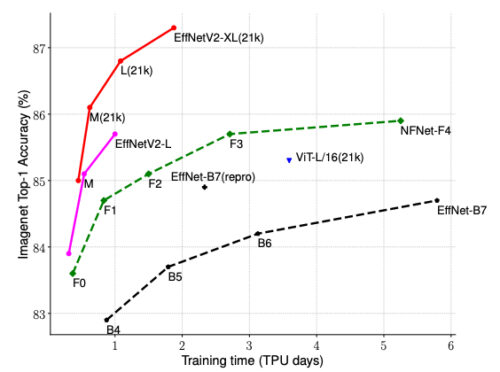
EfficientNetV2は、ImageNet分類で従来のモデルよりもはるかに優れたトレーニング効率を実現します。
3.CoAtNets:畳み込みと自己注意の利点を備えたハイブリッドモデル(1/2)関連リンク
1)ai.googleblog.com
Toward Fast and Accurate Neural Networks for Image Recognition
2)arxiv.org
EfficientNetV2: Smaller Models and Faster Training
CoAtNet: Marrying Convolution and Attention for All Data Sizes
3)github.com
google / automl
4)tfhub.dev
efficientnet_v2

