
1.Kubernetesのノード数を7500に拡張(1/2)まとめ
・GPT-3やCLIPやDALL·Eなどで有名なOpen AIの背後にあるインフラシステムの紹介
・Kubernetesを7500ノードに規模拡大し大規模モデルから小規模研究まで迅速に対応可
・2018年1月時点では2,500ノードだったので3年で3倍に規模が拡大している
2.Kubernetesの大規模運用から得た教訓
以下、openai.comより「Scaling Kubernetes to 7,500 Nodes」の意訳です。元記事の投稿は2021年1月25日、Benjamin ChessさんとEric Siglerさんによる投稿です。
かなりハードウェアよりのお話なので、GPT-3やCLIPやDALL·Eは、この規模感のシステムで開発されてるんだなぁ、ワールドクラスってすごいなぁ、一時間300円が高いとか言ってる場合じゃないなー、ぐらいの理解の超斜め読みで大丈夫と思います。
Kubernetes(クーバネティース)はインフラ系の作業に関わってないとあまり知る機会がないと思うのですが、この辺の記事を読むとわかりやすいですが、開発環境の設定って面倒じゃないですか?なので、ゼロから何度も環境を構築するより、一度設定した環境をマルっとコピー出来たら楽だよね、って事で仮想環境(dockerなどのコンテナ)の概念が出てきて、でも様々なコンテナが組織内に乱立しても収拾がつかなくなってしまうし、コンテナの規模の拡大縮小やコンテナ同士の連携が簡単に出来たら便利だよね、って事でコンテナ群の運用を助けてくれるツールがKubernetesです。
なので、ある程度規模が大きな組織であればKubernetesで楽になる部分があるので参考になるユースケースにも思えますが、本記事で紹介されているシステムは本当に物量が違いすぎてあまり参考にならない感もあります。
Kubernetesはギリシャ語で操舵手やパイロットを意味するらしいので、そこから連想したアイキャッチ画像のクレジットはPhoto by Maximilian Weisbecker on Unsplash
Kubernetesクラスターを7500ノードに規模拡大し、GPT-3、CLIP、DALL·Eなどの大規模モデルだけでなく、ニューラル言語モデルの規模拡大など、小規模な反復研究にも迅速に対応できるスケーラブルなインフラストラクチャを作成しました。単一のKubernetesクラスターをこのサイズに規模拡大する事はめったに行われず、特別な注意が必要ですが、利点は、機械学習研究チームがコードを変更せずに素早く規模を拡大できるシンプルなインフラストラクチャである事です。
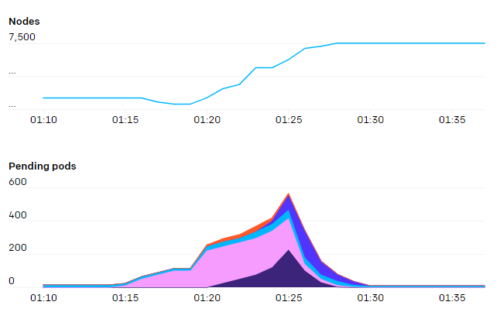
2,500ノードに規模を拡大した前回(2018年1月)の投稿以来、研究者のニーズを満たすためにインフラストラクチャを拡張し続け、その過程で多くの追加の教訓を学びました。この投稿では、Kubernetesコミュニティの他のユーザーがこれらの教訓から利益を得ることができるように、これらの教訓を要約し、次に取り組むことになる現在直面している問題で終わります。
私達のワークロードの説明
手始めに私達のワークロードについて説明することが重要です。
Kubernetesで実行するアプリケーションとハードウェアは、一般的な企業で遭遇するものとはかなり異なります。 私たちの問題とそれに対応する解決策は、あなた自身の設定によく合うかもしれませんし、そうでないかもしれません!
大規模な機械学習ジョブは多くのノードにまたがっており、各ノードの全てのハードウェアリソースにアクセスできる場合に最も効率的に実行されます。こうすれば、GPU同士がNVLinkを使用して直接相互通信したり、GPUがGPUDirectを使用してNICと直接通信したりできます。
従って、多くのワークロードでは、単一のポッドがノード全体を占めます。NUMA、CPU、またはPCIEリソースの競合は、スケジューリングの要因ではありません。ビンパッキング(Bin-packing)や断片化は一般的な問題ではありません。
現在のクラスターには完全な二分帯域幅(bisection bandwidth)があるため、ラックまたはネットワークトポロジについても考慮していません。これはすべて、ノードが多数ある一方で、スケジューラーへの負担が比較的少ないことを意味します。
とは言え、kube-schedulerの負担は急です。新しいジョブは、数百のポッドが全て一度に作成され、その後、比較的低い利用率に戻ります。
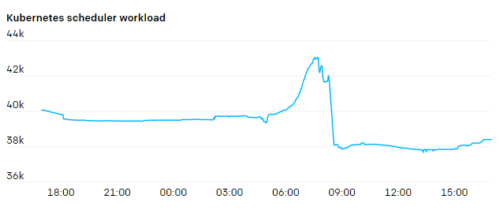
私たちの最大のジョブはMPIを実行し、ジョブ内のすべてのポッドは単一のMPIコミュニケーターに参加しています。参加しているポッドのいずれかが停止すると、ジョブ全体が停止し、再起動する必要があります。
ジョブは定期的にチェックポイントを設定し、再開すると最後のチェックポイントから再開します。従って、ポッドはセミステートフルであると見なされます。停止したポッドは交換して作業を続行できますが、これは混乱を招くため、最小限に抑える必要があります。
Kubernetesの負荷分散機能にはそれほど依存していません。HTTPSトラフィックはほとんどなく、A/Bテスト、blue/green、カナリアなどの仕組みは必要ありません。ポッドは、サービスのエンドポイントではなく、SSHを介してMPIを使用してポッドIPアドレスで相互に直接通信します。サービスを「探す」機会は限られています。ジョブの起動時にポッドがMPIに参加している1回限りの探索を実行するだけです。
ほとんどのジョブは、何らかの形式のBLOBストレージと相互作用します。通常、データセットまたはチェックポイントの一部のシャードをBLOBストレージから直接ストリーミングするか、高速なローカル一時的ディスクにキャッシュします。POSIXのツール群が役立つ場合のために、いくつかの固定ディスクもありますが、BLOBストレージははるかに規模拡張が容易であり、低速のデタッチ/アタッチ操作を必要としません。
最後に、私たちの仕事の性質は基本的に研究です。つまり、ワークロード自体は常に変化しています。スーパーコンピューティングチームは、コンピューティングインフラストラクチャの「本番」品質レベルと見なされるものを提供するよう努めていますが、そのクラスターで実行されるアプリケーションは短命であり、開発者は迅速に反復実験をします。現在の傾向と適切なトレードオフに関する私たちの仮定に反する新しい使用パターンがいつでも出現する可能性があります。そのため、物事が変化したときに迅速に対応できる持続可能なシステムが必要です。
ネットワーキング
クラスタ内のノードとポッドの数が増えるにつれて、Flannelでは必要なスループットをスケールアップするのが困難であることがわかりました。Azure VMSSのIP構成と関連するCNIプラグインにネイティブポッドネットワークテクノロジーを使用するように切り替えました。これにより、ポッドでホストレベルのネットワークスループットを取得できました。
エイリアスベースのIPアドレス指定の使用に切り替えたもう1つの理由は、最大のクラスターでは、一度に約200,000個のIPアドレスが使用される可能性があるためです。ルートベース(route-based)のポッドネットワークをテストしたところ、効果的に使用できるルートの数に大きな制限があることがわかりました。
カプセル化を回避すると、基盤となるSDNまたはルーティングエンジンへの要求が高まりますが、ネットワークのセットアップは簡単になります。VPNまたはトンネリングの追加は、追加のアダプターなしで実行できます。ネットワークの一部のMTUが低いため、パケットの断片化について心配する必要はありません。ネットワークポリシーとトラフィック監視は簡単です。パケットの送信元と宛先についてあいまいさはありません。
ホストでiptablesタグを使用して、名前空間およびポッドごとのネットワークリソースの使用状況を追跡します。これにより、研究者はネットワークの使用パターンを視覚化できます。特に、私たちの実験の多くはインターネットとポッド内の通信パターンが異なるため、ボトルネックが発生している可能性のある場所を調査できると便利なことがよくあります。
iptablesマングルルール(mangle rules)を使用して、特定の基準に一致するパケットを任意にマークできます。トラフィックが内部トラフィックかインターネットバウンドかを検出するためのルールは次のとおりです。 FORWARDルールは、ポッドからのトラフィックと、ホストからのINPUTおよびOUTPUTトラフィックを対象としています。
iptables -t mangle -A INPUT ! -s 10.0.0.0/8 -m comment --comment "iptables-exporter openai traffic=internet-in" iptables -t mangle -A FORWARD ! -s 10.0.0.0/8 -m comment --comment "iptables-exporter openai traffic=internet-in" iptables -t mangle -A OUTPUT ! -d 10.0.0.0/8 -m comment --comment "iptables-exporter openai traffic=internet-out" iptables -t mangle -A FORWARD ! -d 10.0.0.0/8 -m comment --comment "iptables-exporter openai traffic=internet-out"
マークが付けられると、iptablesは、このルールに一致するバイト数とパケット数を追跡するためのカウンターを開始します。iptables自体を使用して、これらのカウンターを目で確認できます。
% iptables -t mangle -L -v Chain FORWARD (policy ACCEPT 50M packets, 334G bytes) pkts bytes target prot opt in out source destination .... 1253K 555M all -- any any anywhere !10.0.0.0/8 /* iptables-exporter openai traffic=internet-out */ 1161K 7937M all -- any any !10.0.0.0/8 anywhere /* iptables-exporter openai traffic=internet-in */
iptables-exporterと呼ばれるオープンソースのPrometheusエクスポーターを使用して、これらを監視システムで追跡します。これは、さまざまなタイプの条件に一致するパケットを追跡する簡単な方法です。
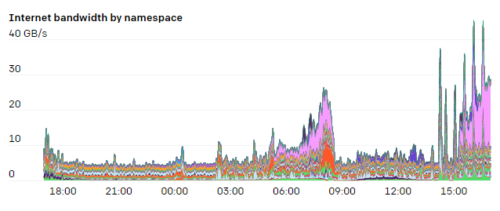
ネットワークモデルのややユニークな側面の1つは、ノード、ポッド、およびサービスネットワークのCIDR範囲を研究者に完全に公開していることです。ハブアンドスポークネットワークモデルがあり、ネイティブノードとポッドのCIDR範囲を使用してそのトラフィックをルーティングします。研究者はハブに接続し、そこから個々のクラスター(スポーク)のいずれかにアクセスできます。
ただし、クラスター自体は相互に通信できません。これにより、障害の分離を壊す可能性のあるクラスター間の依存関係がなく、クラスターが分離されたままになります。
「NAT」ホストを使用して、クラスターの外部からのトラフィックのサービスネットワークCIDR範囲を変換します。この設定により、研究者は実験のためにどのように、どのような種類のネットワーク構成を選択できるかを柔軟に選択できます。
APIサーバー
Kubernetes APIサーバーやetcdは正常に動作するクラスターにとって重要なコンポーネントであるため、これらのシステムへの負荷に特に注意を払っています。kube-prometheusが提供するGrafanaダッシュボードと、追加の社内ダッシュボードを使用します。障害の高レベルのシグナルとして、APIサーバーのHTTPステータス429(リクエストが多すぎる)と5xx(サーバーエラー)の割合を警告することが役立つことがわかりました。
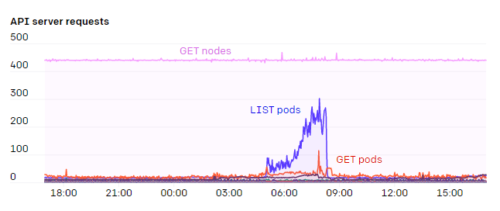
kube内でAPIサーバーを実行している人もいますが、私たちは常にクラスターの外部でAPIサーバーを実行しており、etcdサーバーとAPIサーバーはどちらも、専用のノードで実行されます。
私たちの最大のクラスターは、5つのAPIサーバーと5つのetcdノードを実行して、負荷を分散し、1つがダウンした場合の影響を最小限に抑えます。前回のブログ投稿でKubernetesイベントを独自のetcdクラスターに分割して以来、etcdに特に問題はありませんでした。APIサーバーはステートレスであり、通常、自己修復インスタンスグループまたはスケールセットで簡単に実行できます。重大障害は非常にまれであるため、etcdクラスターの自己修復自動化の構築はまだ試みていません。
APIサーバーはかなりのメモリを消費する可能性があり、クラスター内のノードの数に比例してスケーリングする傾向があります。7,500ノードのクラスターでは、APIサーバーごとに最大70GBのヒープが使用されていることがわかります。したがって、幸いなことに、今後もハードウェア機能の範囲内で十分であるはずです。
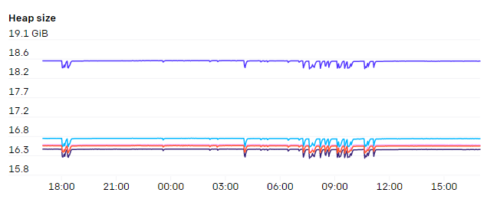
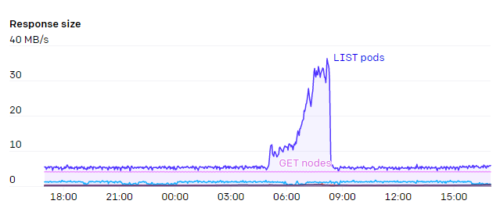
APIサーバーの大きな負担の1つは、エンドポイントでのWATCHでした。「kubelet」や「node-exporter」など、クラスター内のすべてのノードがメンバーになっているサービスがいくつかあります。ノードがクラスターに追加またはクラスターから削除されると、このWATCHが起動します。また、通常、各ノード自体がkube-proxyを介してkubeletサービスを監視していたため、これらの応答に必要な#と帯域幅は\(N^2\) で膨大であり、場合によっては1GB/秒以上になります。
Kubernetes 1.17でリリースされたEndpointSlicesは、この負荷を1000分の1に減らす大きなメリットでした。
クラスターのサイズに応じてスケーリングするAPIサーバーリクエストには十分注意しています。DaemonSetがAPIサーバーと相互に影響しないようにしています。各ノードで変更を監視する必要がある場合は、Datadog Cluster Agentなどの中間キャッシュサービスを導入することは、クラスター全体のボトルネックを回避するための適切なパターンのようです。
クラスターが成長するにつれて、クラスターの実際の自動スケーリングは少なくなります。しかし、一度に自動スケーリングしすぎると、問題が発生することがあります。新しいノードがクラスターに参加するときに生成されるリクエストは多数あり、一度に数百のノードを追加すると、APIサーバーの容量が過負荷になる可能性があります。 これを数秒でもスムーズにすることで、停止を回避できます。
3.Kubernetesのノード数を7500に拡張(1/2)関連リンク
1)openai.com
Scaling Kubernetes to 7,500 Nodes

